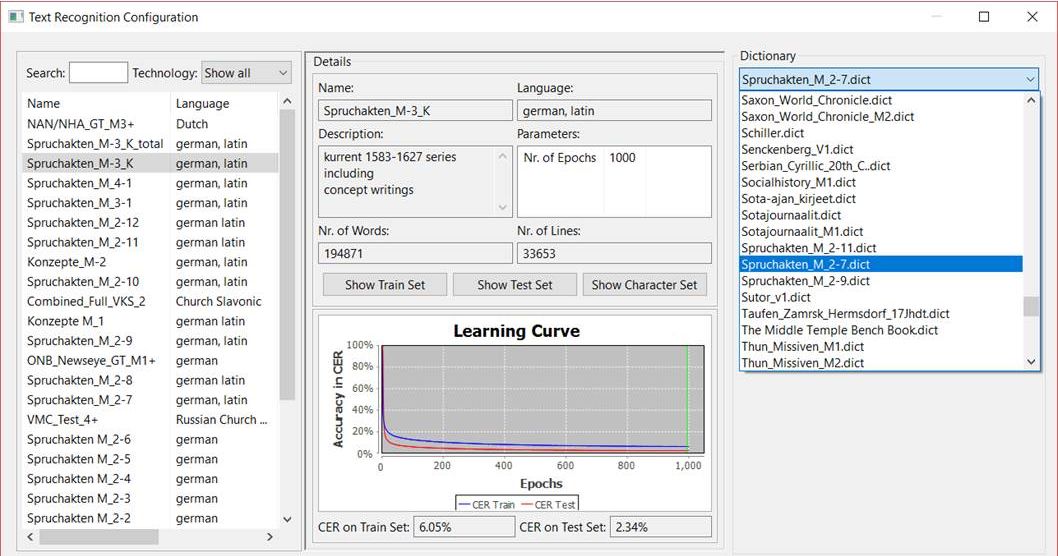
dictionaries
Release 1.7.1
HTR does not require dictionaries. However, they are also available and can be selected if you perform full-text recognition.
With each HTR training, a dictionary can be generated out of the GT in the training set. It is therefore possible to create a suitable dictionary for each model or for the type of text you are working with.
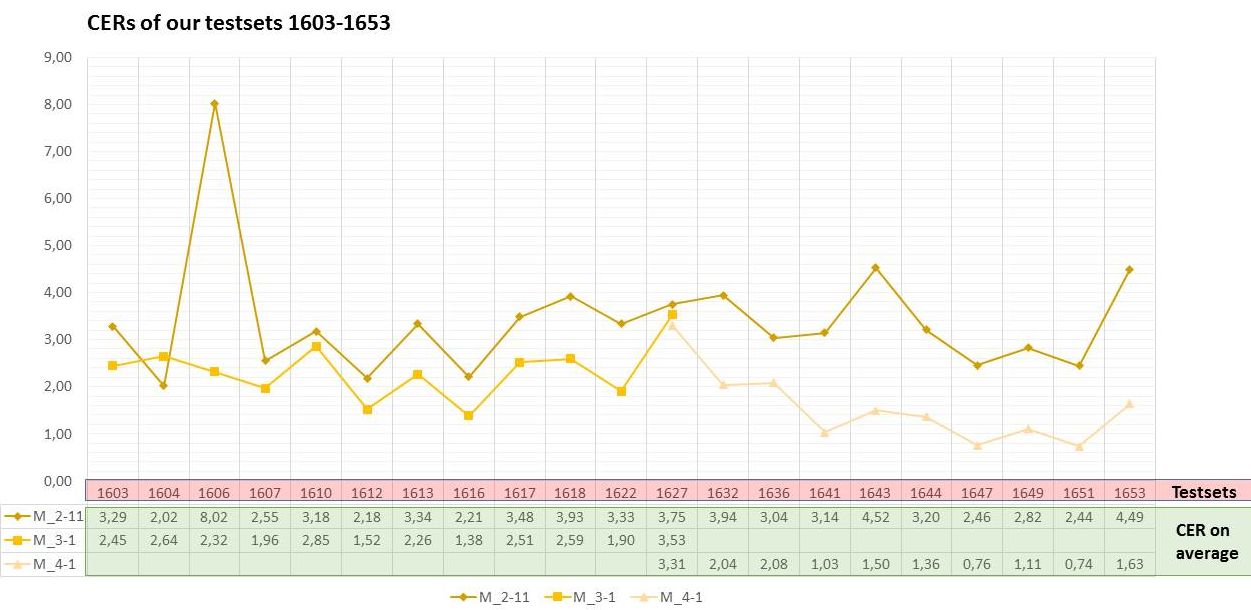
However, dictionaries are rarely used in Transkribus. In our project they are sometimes used at the beginning of the work on new models. As long as the model to be improved still has a CER of more than 8%, correcting the texts recognized by the HTR is very time-consuming. If a dictionary is used at this point, the CER can often be reduced to 5%. If the model already has a CER below 8%, the use of dictionaries is counterproductive because the reading result often becomes worse again. In such cases, the HTR “contrary to better knowledge” replaces its own reading result with a recommendation from the dictionary.
We use dictionaries just to support very weak models. And we do this rather to help the transcriber with particularly difficult writings. So we used a dictionary to create the GT for the really hard to read concept writings. Of course, the results had to be corrected in every case. But the “reading recommendations”, which were based on the HTR with dictionary, were a good help. As soon as our model was able to recognize concept writings with less than 8% CER, we decided not to use the dictionary any longer.