Edit multiple documents simultaneously
Version 1.15.1
Until now, we were used to initiating the layout analysis and the HTR for the document we were currently in. Now, however, it is possible to activate both steps for all documents of the entire collection in which we are currently located. We will describe how this works in a moment – but first of all why we are very happy about this:
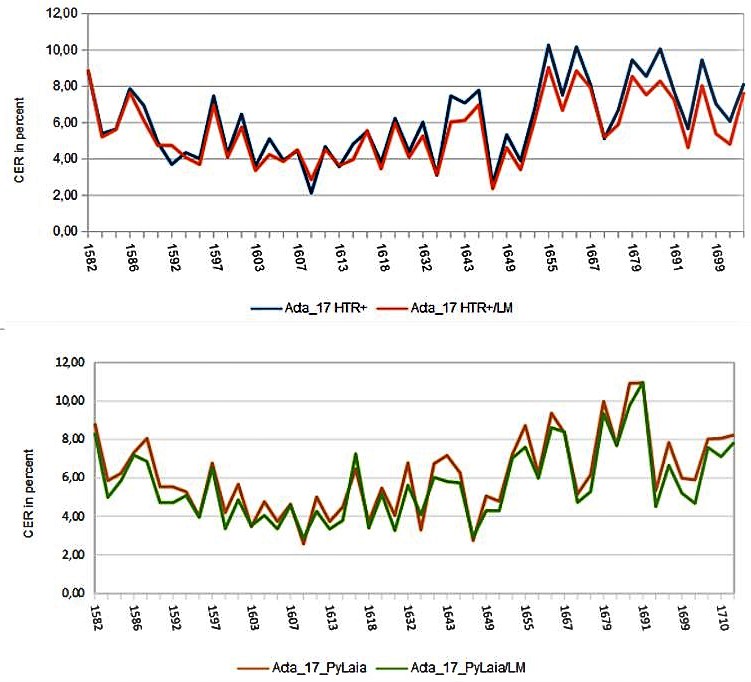
In order to check the results of our freshly trained models, we have created a separate collection of Spruchakten-testsets. How exactly and why, you can read elsewhere. This means that for each document from which we have used GT in training, there is a separate test set document in the test set collection.
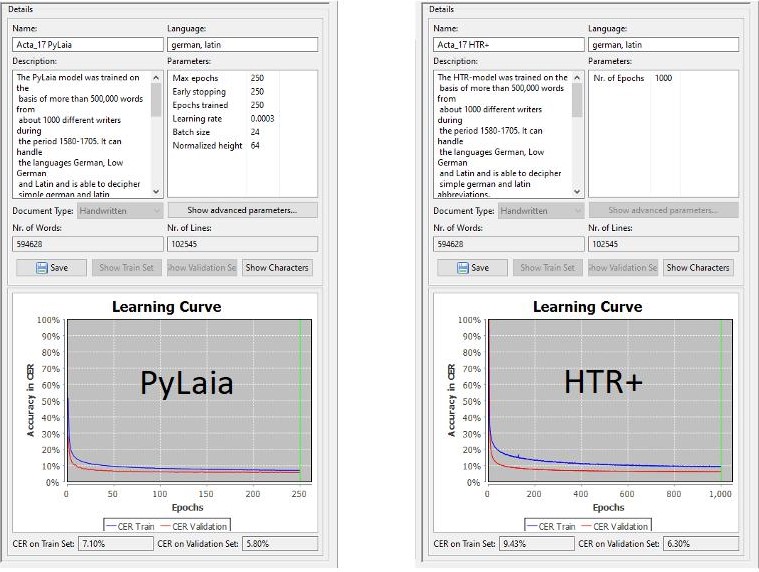
When a new HTR model has finished training and we are curious to see how it will compare to the previous models, we run it through each of the test sets and then calculate the CER. After more than two years of training, our test set collection is now quite full; with almost 70 test sets already in it.
Imagine how time-consuming it used to be to open each test set individually to activate the new HTR. Even with only 40 test sets, you had to be very curious. And now imagine how much easier it is that we can trigger the HTR (and also the LA) for all documents at the same time with one click. This should please all those who process a lot of small documents, such as index cards, in one collection.
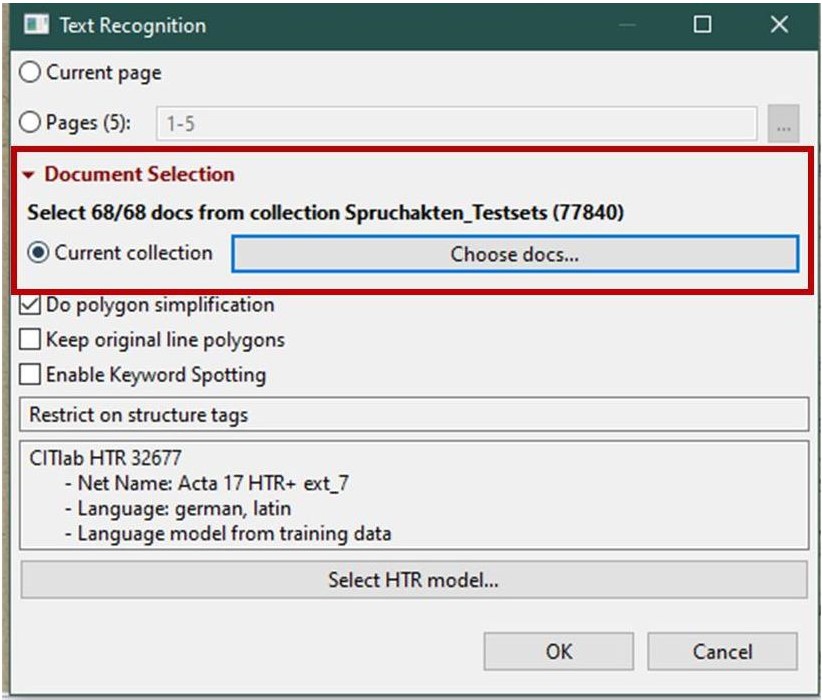
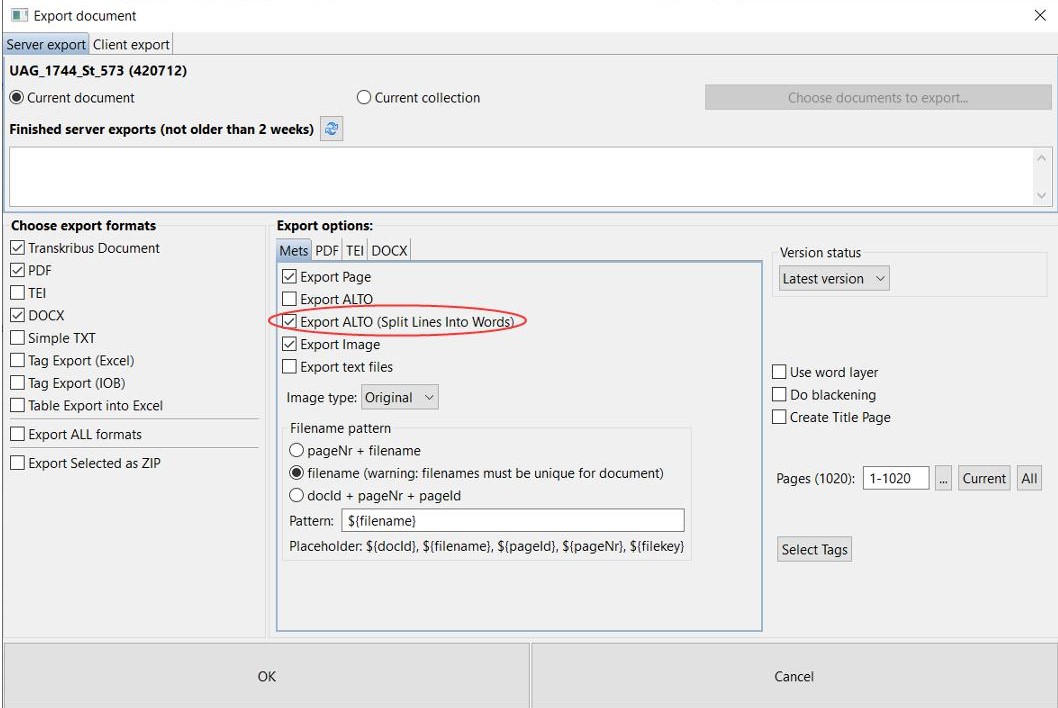
And how does that work now? You can see it immediately under the layout analysis tools: In red, under “Document Selection”, there is the new option “Current collection” to be selected for the following step.
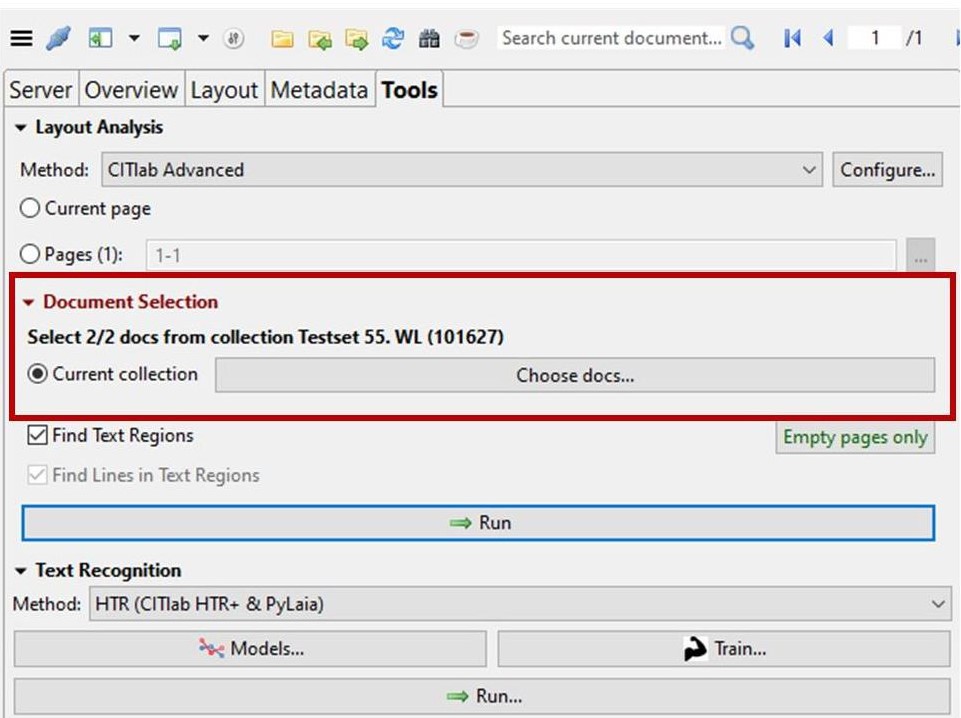
However, it is not enough to simply select “Current Selection” and then start the LA; irst you must always enter the selection via “Choose docs…”. Either you simply confirm the preselection (all docs in the collection) or you select individual docs.
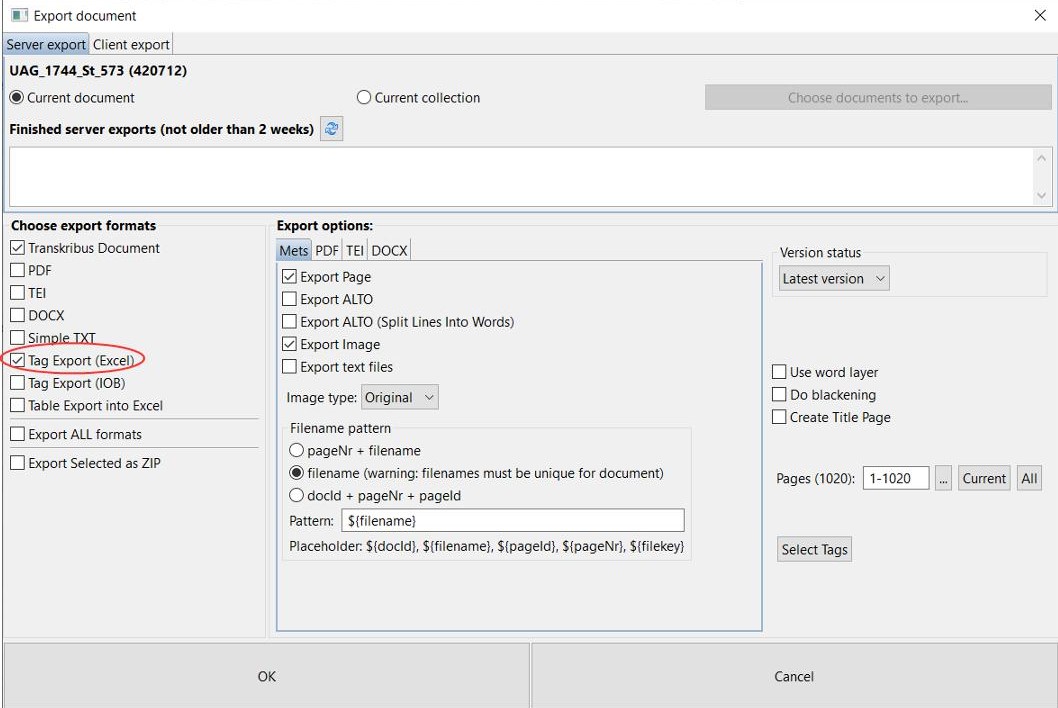
For the HTR, the same option will only appear in the selection window for “Text Recognition”. Here, too, you can select the “Current collection” for the following step. And here, too, you must confirm the selection again via “choose docs….”.