Toolbar – the most important tools and how to use them #1
Release 1.7.1
Creating Layouts

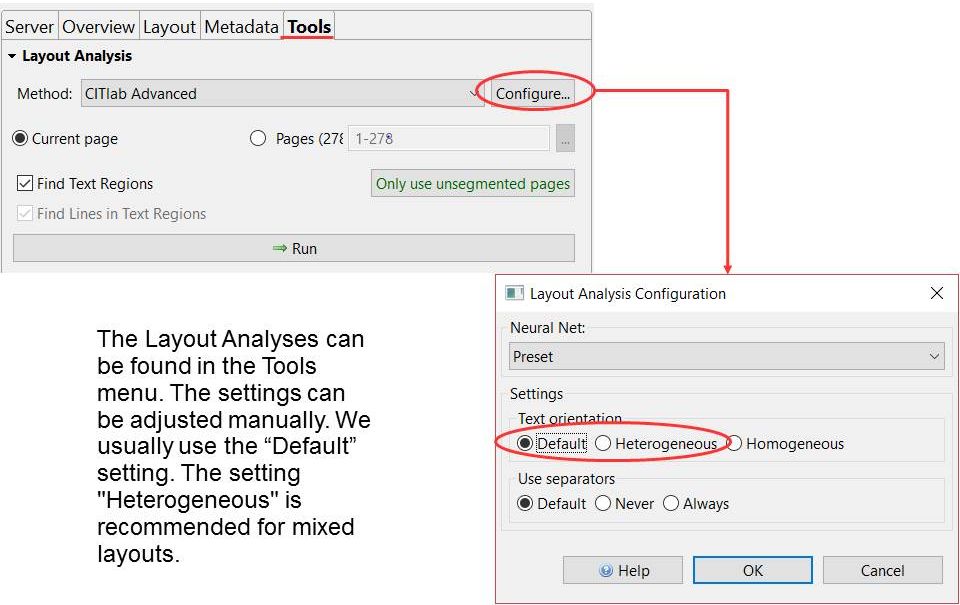
This is how the toolbar looks like with a new image. After you have run the CITlab Advanced LA, the other tools will be enabled. If the layout is to be done manually, the two tools in the upper circles are particularly important. TR means text region. This is the first layout element that has to be created for a page. It defines which areas of the image have text and which do not. If the text does not fit correctly into a text region, you first roughly draw the TR and later adjust it. Then you can draw the baselines with “BL”. Among the lower tools, only the green, semicircular arrow is important. This is the “undo”-function; as the name suggests, it is used to undo actions.
Tips & Tools
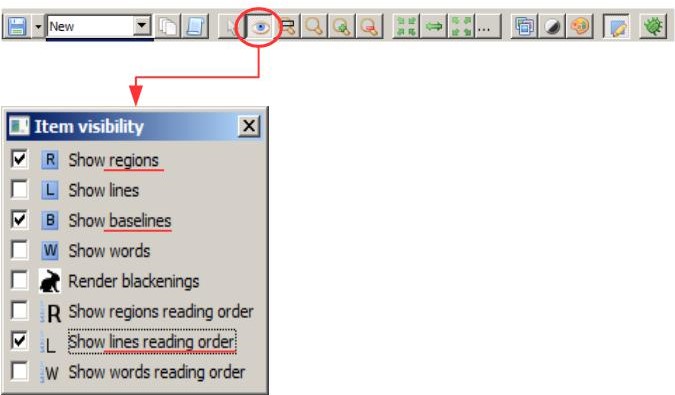
“Item visibility” is a function that makes structure of the document more transparent for you. If it is enabled, a box appears in which you can select what items should be visible in the current image. Textregions and Baselines are the most important elements, not only while editing the layout, but also during the later transcription. These two boxes are always checked in the default setting. If the display of the Baselines annoys you, you should deactivate it manually. Another important feature for correcting the layout is the Lines Reading Order, i.e. the order in which the lines are read later by the HTR. When the Reading Order is displayed, you can easily see whether the layout analysis has worked reliably. However, this display is mostly distracting while transcribing. In this case you should hide it again.