Release 1.10.1
As the name suggests, the Compare Samples tool tests the capabilities of an HTR model based on a sample rather than a manually selected test set. We have explained in an earlier post how to create such samples, that they represent an objective alternative to conventional test sets and why they can be created with much less effort.
“Compare Samples” may look like a validation tool, but is actually not one of them. You can use it to validate an HTR model, but Advanced Compare is better suited for this. The real function of “Sample Compare” is to make predictions about the success of an HTR model on a given material.
You may remember the Model Booster. There you need a suitable HTR model that can serve as a base model for a planned HTR training. With the numerous Public Models available, it is a good idea to first check with “Compare Samples” which model fits to your project.
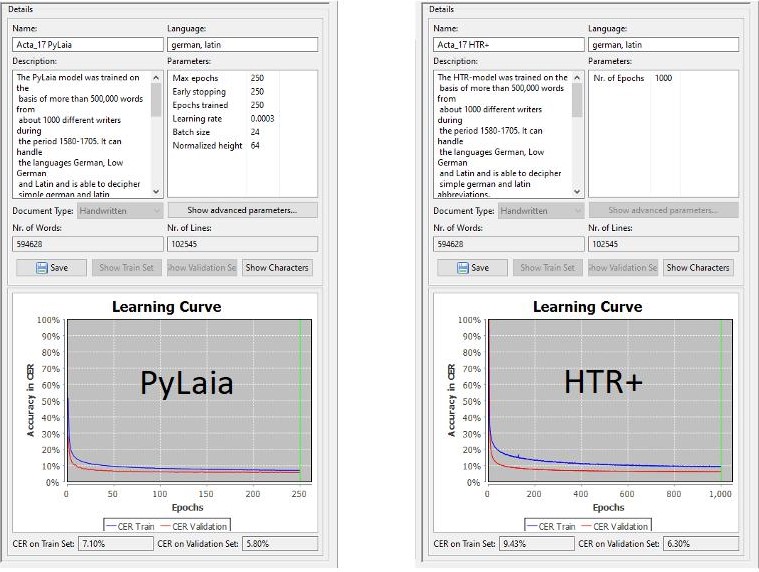
To create such a prediction for a sample, you first have to run the selected HTR models over the entire sample (before that, of course, you have already created the GT for the sample). Then open the Samples tab of the “Compare Samples” tool. This tab lists all samples of your active collection. You select the sample that will be used as the basis for the prediction. Now you can select the model in the middle, whose text version should serve as a reference for the GT. Start “Compute” and you’re done.
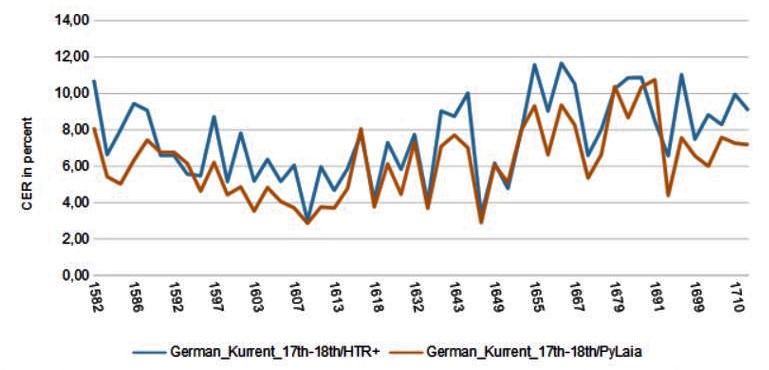
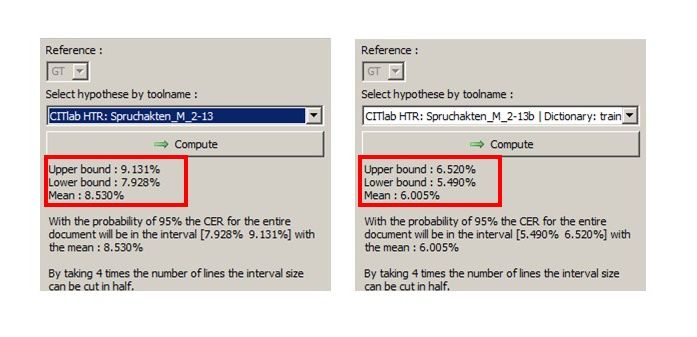
The tool now calculates average values for all lines of the sample with an upper bound, a lower bound and an average value. In the range between upper bound and lower bound you should find the Character Error Rate for 95% of your material at which the selected HTR model is expected to work. In our example below, between 4,7 and 2,9 %.
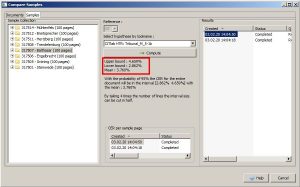
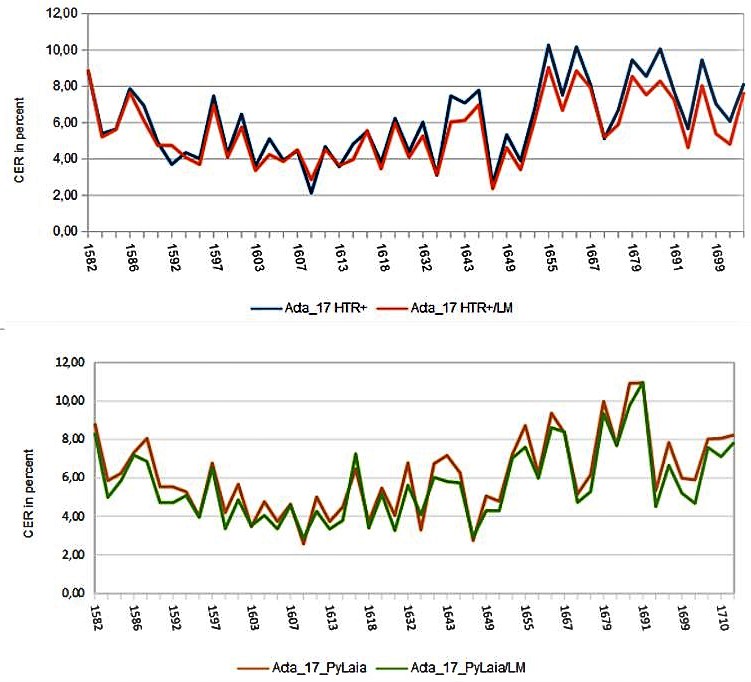
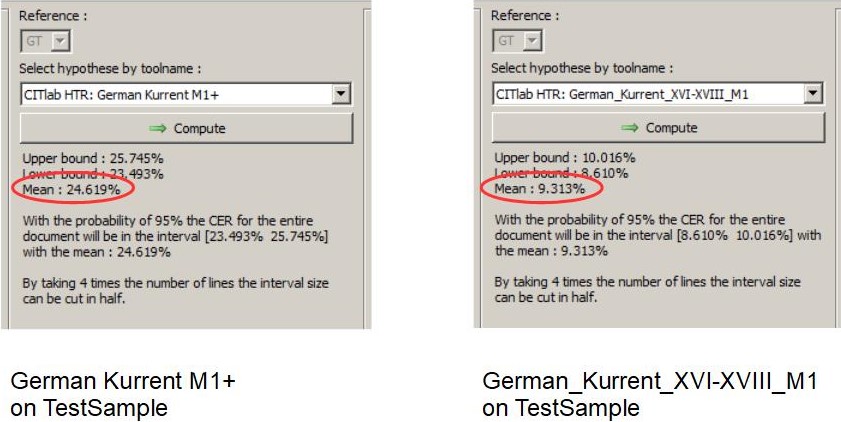
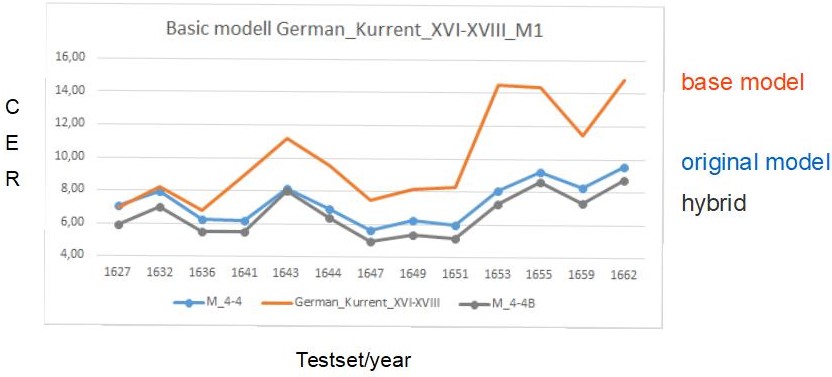
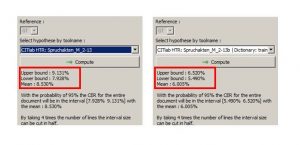
This way you can compare as many models for your material as you like. But the tool also allows a few other things. For example, you can easily check how an HTR model with or without language model or dictionary works on your material and if it is worth using one or the other. Of course this is especially useful to check your own models.
Tips & Tools
Create several smaller samples rather than one giant sample for all your material. You can separate them chronologically or by writer’s hands, for example. This will allow you to make a differentiated prediction for the use of HTR models on all your material or parts of it.