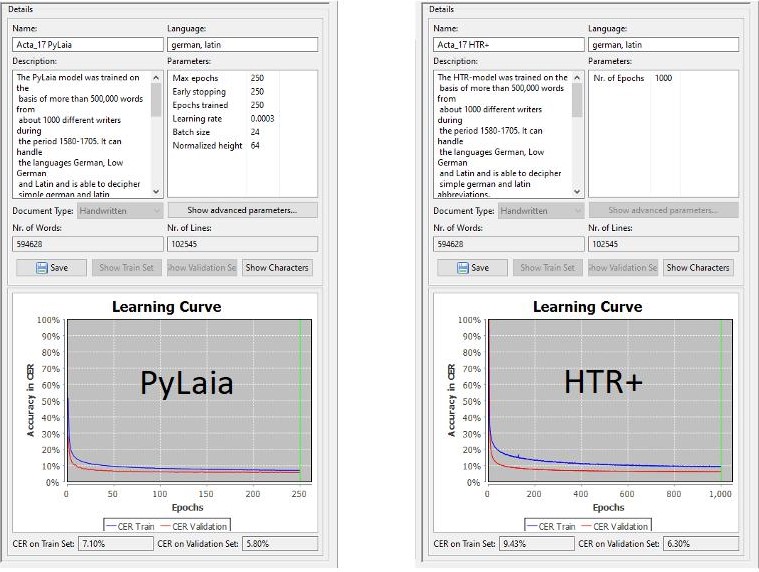
Exclude single lines from training
Some of you will know this from practical experience: you are transcribing a particularly difficult page in Transkribus and you cannot decipher everything with the best will in the world. What do you do? If the page is set to the edit status “ground truth”, the transcription goes into training with the obvious errors (or what you could not read). This is not what is intended. But you don’t want to simply “throw away” the page either.
We have already mentioned the use of tags in another post. We used the “unclear” tag in the project from the beginning. Others also like to use the “gap” tag for such reading problems.
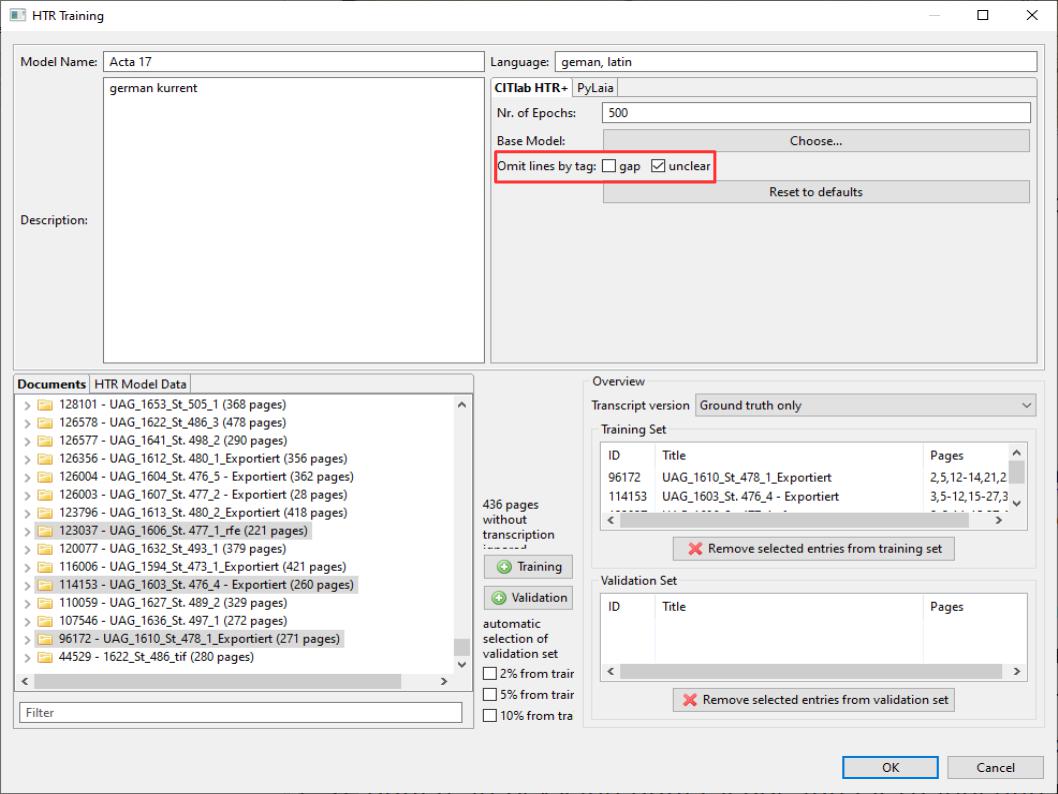
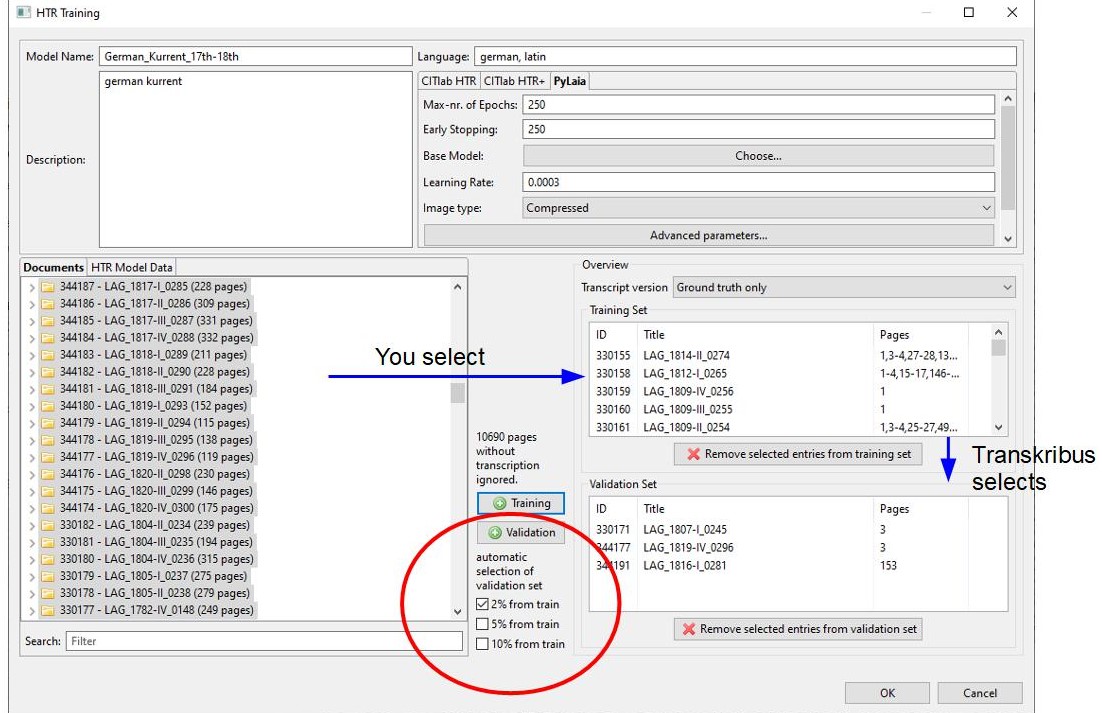
This is now proving to be a great advantage. For some months now, the Transkribus training tool has offered the function “omit lines at tag”
The tool ensures that on all pages that are taken into the training or validation set, the lines that have a tag “unclear” or “gap” are automatically excluded from the training. This means that pages that are not perfectly transcribed, but where the parts that could not be deciphered are marked by tags, can be trained without hesitation.