Last week we were able to provide the first volumes with the opinions of the assessors of the High Royal Tribunal to Wismar – the final Court of appeal in the German territories of the Swedish Crown. Assessors is what the judges at the tribunal are called. Since the Great Nordic War there was only a panel of four judges instead of eight. The Deputy President assigned them the cases in which they should form a legal opinion. As at the Reichskammergericht at Wetzlar, speakers and co-referees were appointed for each case, who formulated their opinions in writing and discussed them with their colleagues. If the votes of the two judges were in agreement, the consensus of the remaining colleagues was only formally requested in the court session. In addition, all relations had to be checked and confirmed by the Deputy President. If the case was more complicated, all assessors expressed their opinion on the verdict. These reasons for the verdict are recorded in the collection of so-called “Relationes”.
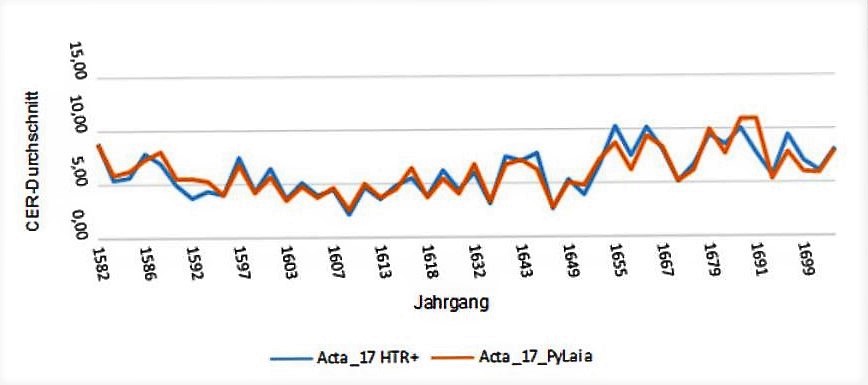
These relations are a first-class source for the history of law, since they refer first to the course of the conflict in a narrative and then propose a judgment. Here we can understand both the legal bases in the justifications and the everyday life of the people in the narratives.The text recognition was realized with an HTR-model that was trained on the manuscripts of 9 different judges of the royal tribunal. The training set consisted of 600,000 words. Accordingly, the accuracy rate of handwritten text recognition is good, which in this case is about 99%.
The results can be seen here. How to navigate in our documents and how the full text search works is explained here.
Who were the judges?
In the second half of the 18th century there was a new generation of judges. At the end of the 1750s / at the beginning of the 1760s, justice at the tribunal was administered by: Hermann Heinrich von Engelbrecht (1709-1760), since 1745 as Assessor, since 1750 as Deputy President, Bogislaw Friedrich Liebeherr (1695-1761), since 1736 as Assessor, Anton Christoph Gröning (1695-1773), since 1749 as Assessor, Christoph Erhard von Corswanten (about 1708-1777), since 1751 Assessor, since 1761 Deputy President, Carl Hinrich Möller (1709-1759), since 1751 as Assessor, Joachim Friedrich Stemwede (about 1720-1787), since 1760 as Assessor, Johann Franz von Boltenstern (1700-1763), since 1762 as Assessor, Johann Gustrav Friedrich von Engelbrechten (1733-1806), between 1762 and 1775 as Assessor and Augustin von Balthasar (1701-1786), since 1763 as Assessor, since 1778 as Deputy President.