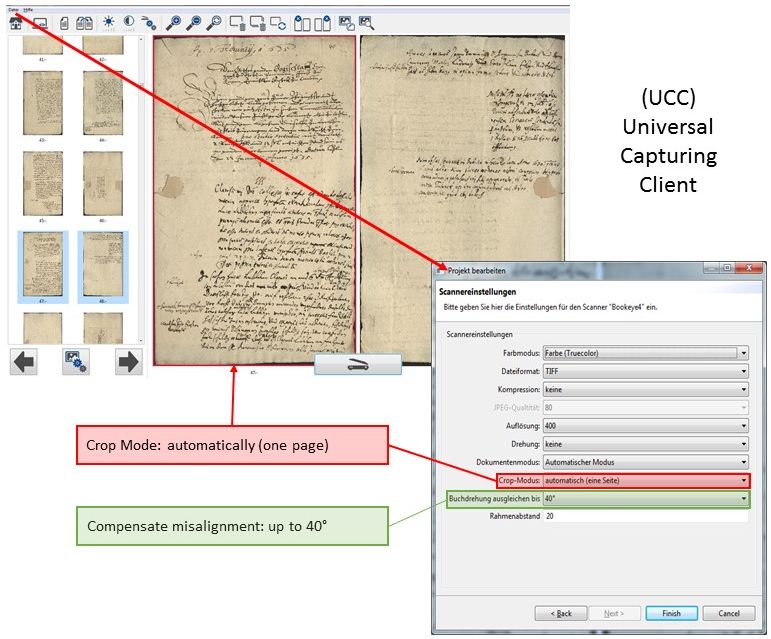
Image resolution
A technical parameter that needs to be uniformly determined at the beginning of the scanning process is the resolution of the digital images, that means how many pixels/dots per inch (dpi) the scanned image should have.
The DFG Code of Practice for Digitisation generally recommends 300 dpi (p. 15). For “text documents with the smallest significant character” of up to 1.5 mm, however, a resolution of 400 dpi can be selected (p. 22). Indeed, in the case of manuscripts – especially concept writings – of the early modern period, the smallest character components can result in different readings and should therefore be as clearly identifiable as possible. We have therefore chosen 400 dpi.
In addition to the advantages for deciphering the scripts, however, the significantly larger storage format of the 400 (around 40,000 KB/img.) compared to the 300 (around 30,000 KB/img.) files must be taken into account and planned for!
The selected dpi number also has an impact on the process of automatic handwritten text recognition. Different resolutions lead to different results of the layout analysis and the HTR. To verify this thesis, we have selected three pages from a speech file of 1618, scanned them in 150, 200, 300 and 400 dpi each, processed all pages in transcript and determined the following CERs:
| Seite/dpi | 150 | 200 | 300 | 400 |
| 2 | 3,99 | 3,5 | 3,63 | 3,14 |
| 5 | 2,1 | 2,37 | 2,45 | 2,11 |
| 9 | 6,73 | 6,81 | 6,52 | 6,37 |
Generally speaking, a lower resolution therefore means a decrease in CERs – though within the range of less than one percent.To be honest, such comparisons of HTR results are somewhat misleading. The very basis of the HTR – the layout analysis – leads to latently different results at different resolutions, which in turn influences the HTR results (apparently cruder analyses achieve worse HTR results) but also the GT production itself (e.g. with cut-off words).

In our example you see the same image in different resolutions. The result of the CITlab Advanced LA changes as the resolution increases. The initial “V” of the first line is no longer recognized at higher resolution, while line 10 is increasingly “torn apart” at higher resolution. With increasing resolution, the LA becomes more sensitive – this can have advantages and disadvantages at the same time.
It is therefore important to have a uniform dpi number for the entire project so that the average CER values and the entire statistical material can be reliably evaluated.