Breaking the rules – the problem with concept writings
Release 1.10.1
Concept scripts are were used when a scribe quickly creates created a draft that is later on “written in the clean”. In the case of the Spruchakten, these are mainly the drafts to the judgments that were sent away later. The concept scripts were usually written very quickly and “sloppy”. Often letters are omitted or word endings “swallowed”. Even for humans conceptual writings are not easy to decipher – for the machine they are a particular challenge.
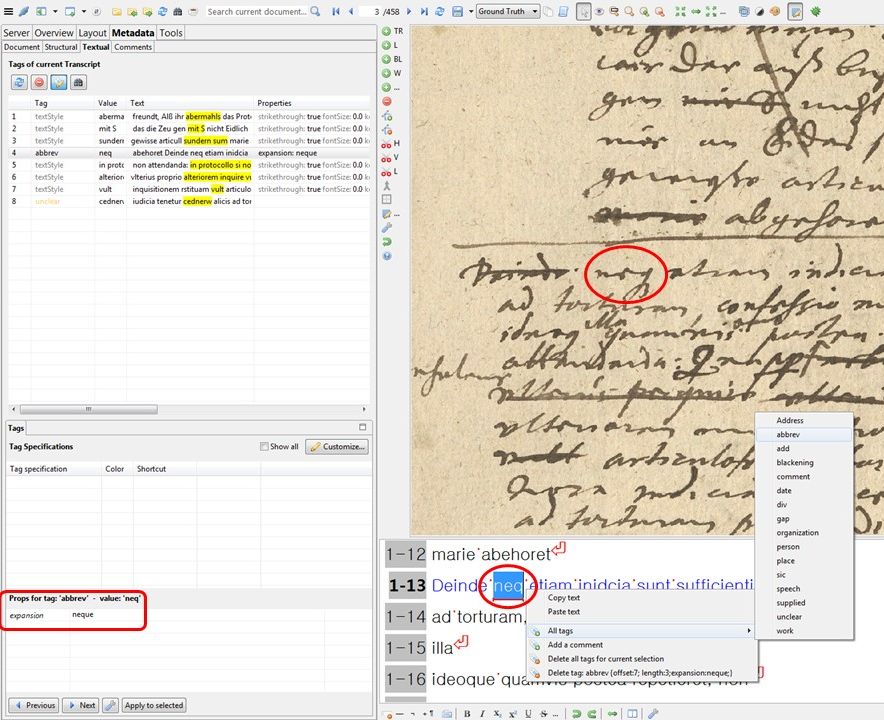
To train an HTR model for reading concept scripts, you proceed in a similar way to training a model that is to interpret abbreviations. In both cases, the HTR model must be enabled to read something that is not really there – namely missing letters and syllables. To achieve this we must break our first rule: “We transcribe as ground truth only what is really written on paper”. Instead, we have to include all skipped letters and missing word endings etc. in our transcription. Otherwise we will not get a sensible and searchable HTR result in the end.
In our experiments with concept writings we tried at first to train special HTR models for concept scripts. The success was rather small. Finally, we decided to train concept scripts – similar to abbreviations – directly within our generic model. In doing so, we checked again and again whether the “wrong ground truth” that we produce in the process worsened the overall result of our HTR model. Surprisingly, the breaking of the transcription rule had no negative effect on the quality of the model. But this could also happen due to the sheer amount of ground truth used in our case (about 400,000 words).
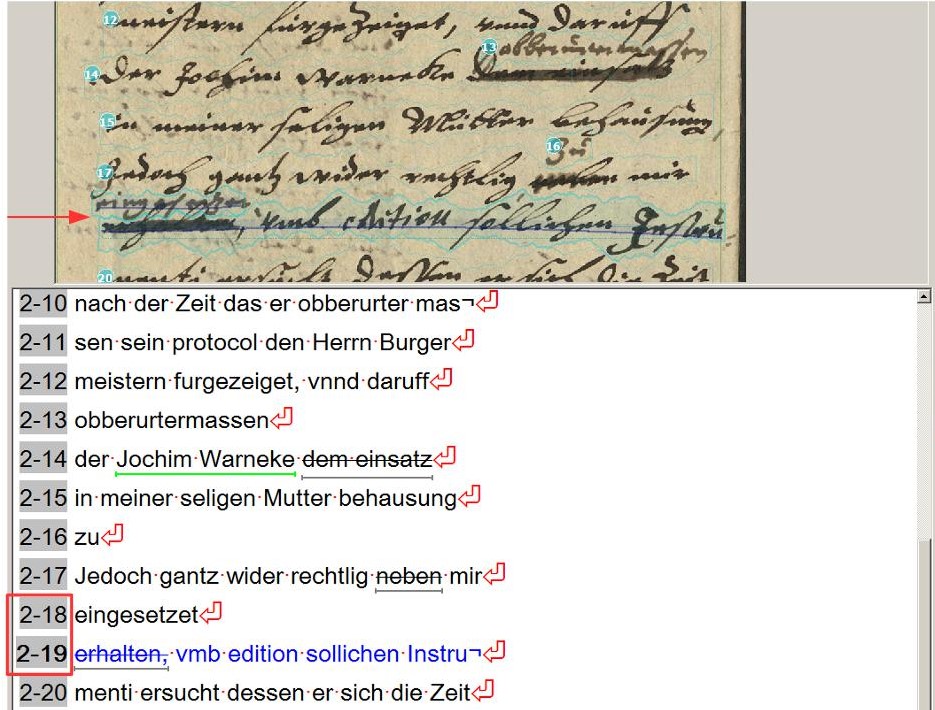
HTR models are therefore able to distinguish concept writings from fair copies and interpret them accordingly – within certain limits. Below you can see a comparison of the HTR result with the GT for a typical concept script from our material.