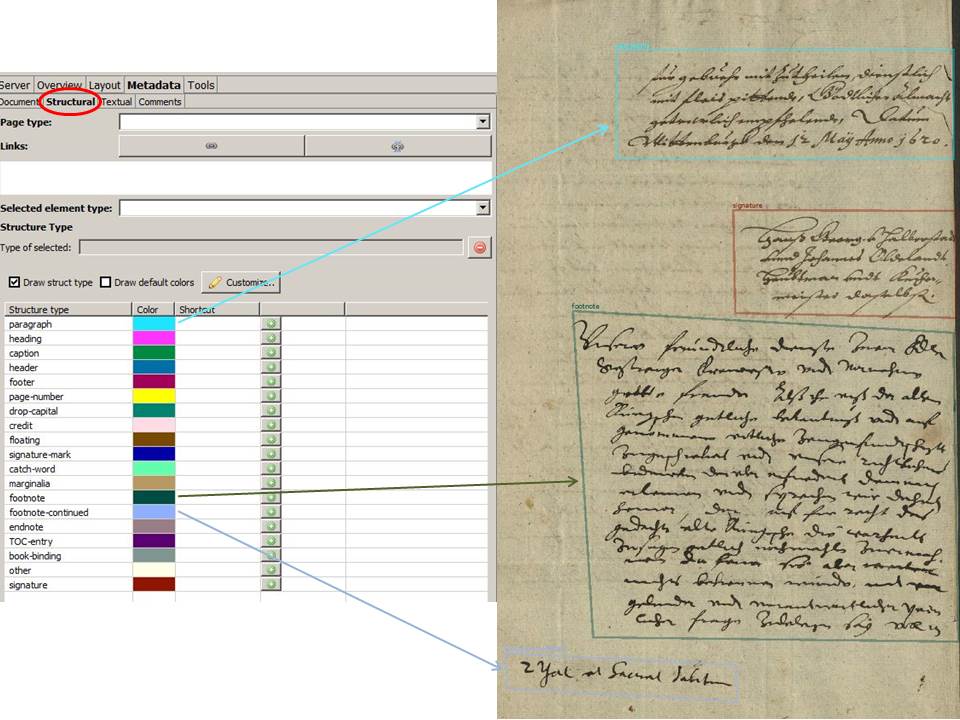
Tag Export II
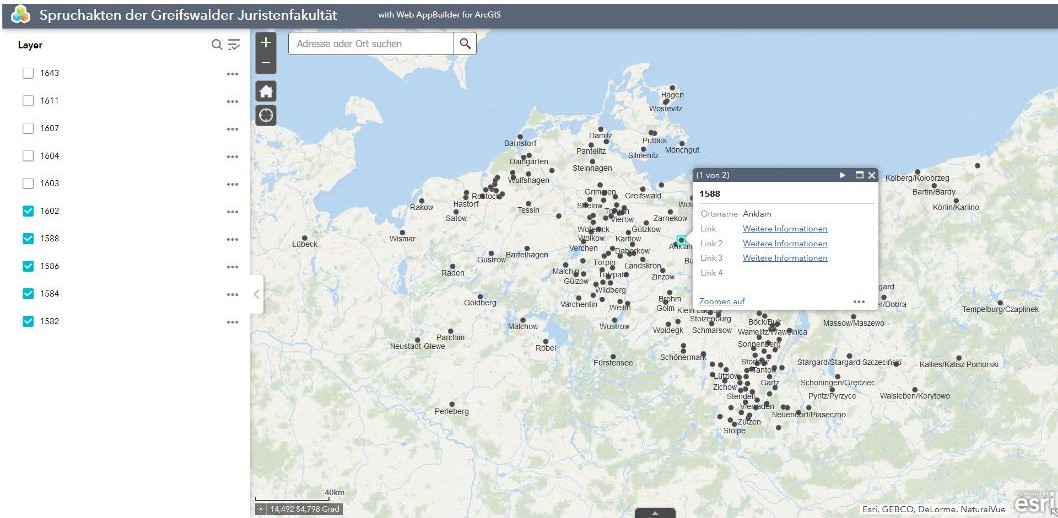
In the last post we presented a benefit of tags. As an example we showed the visualization of results by displaying place tags on a map. But there are other possibilities.
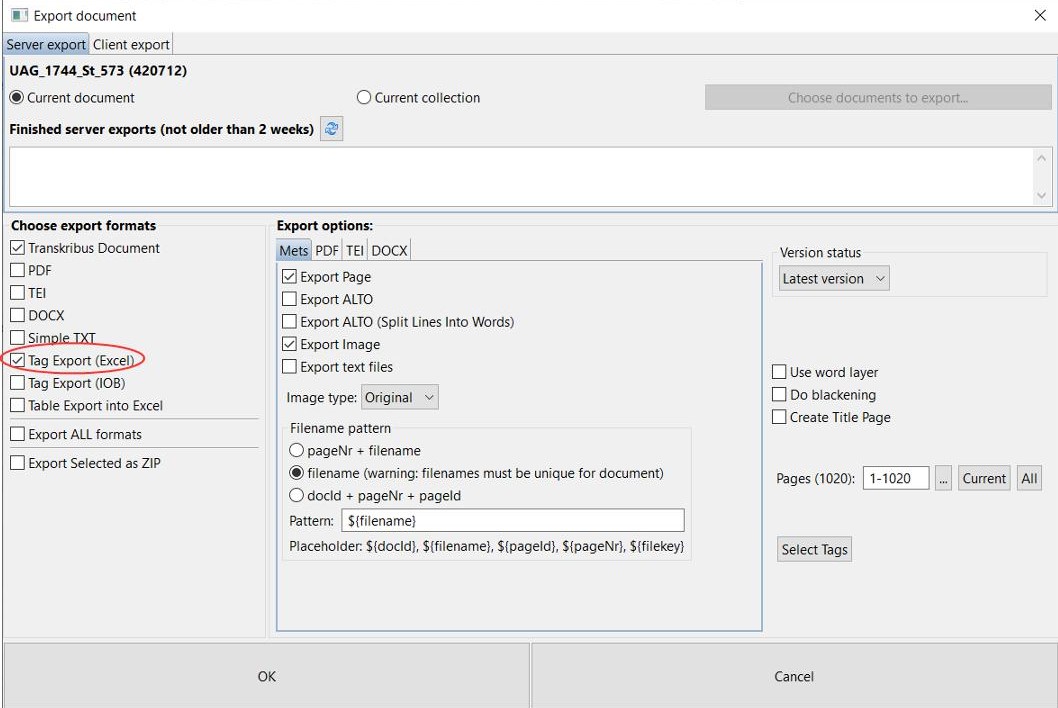
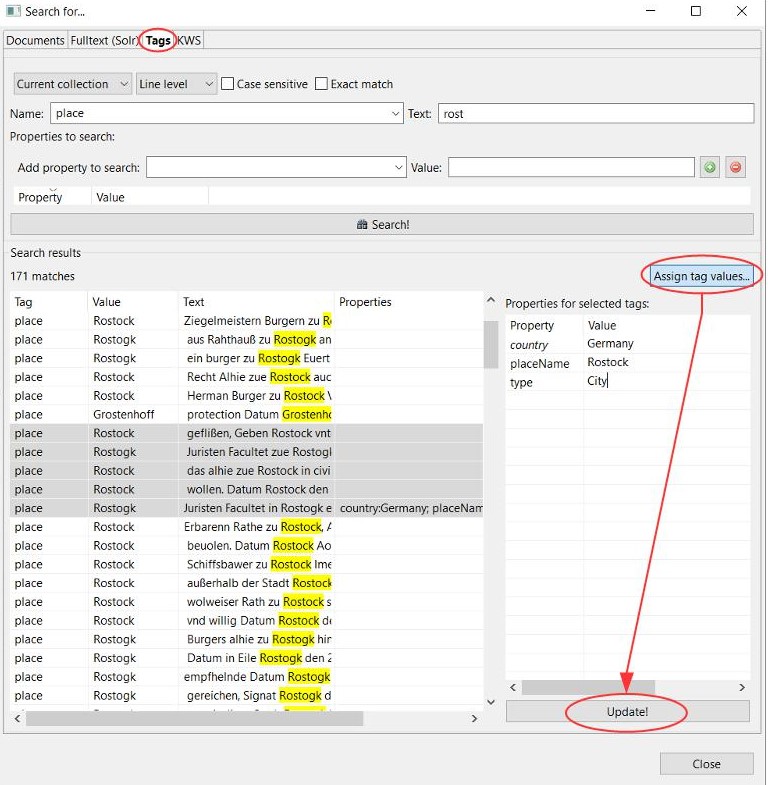
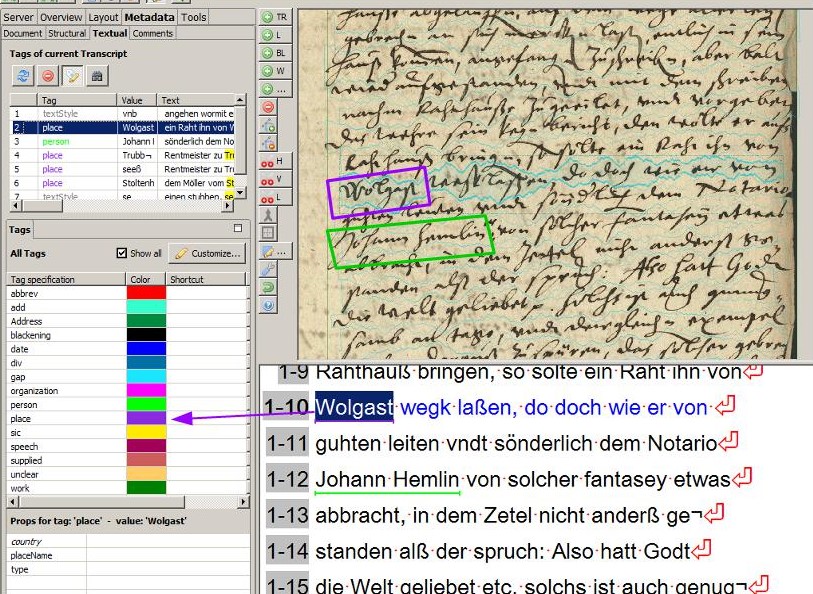
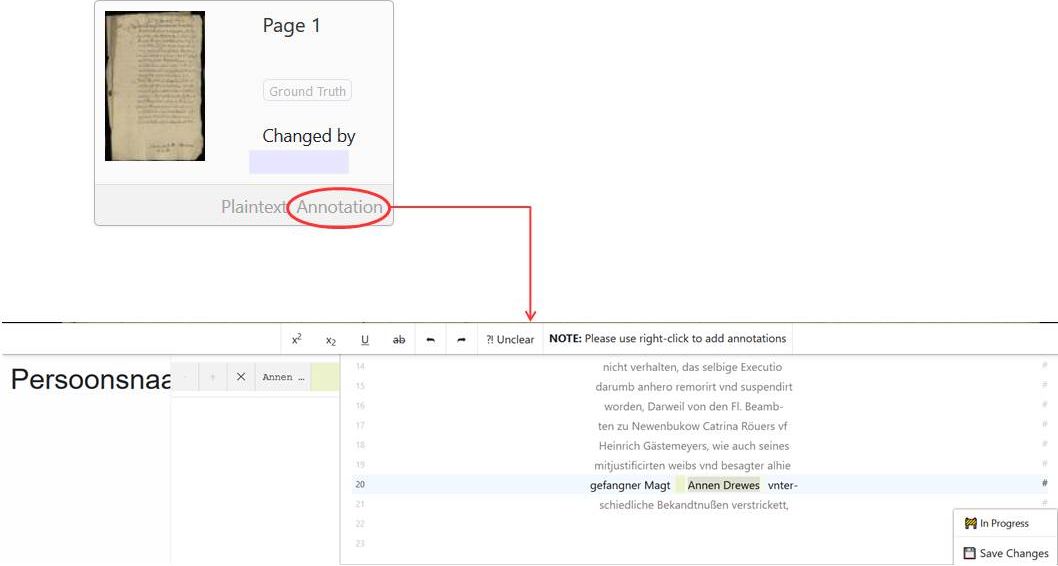
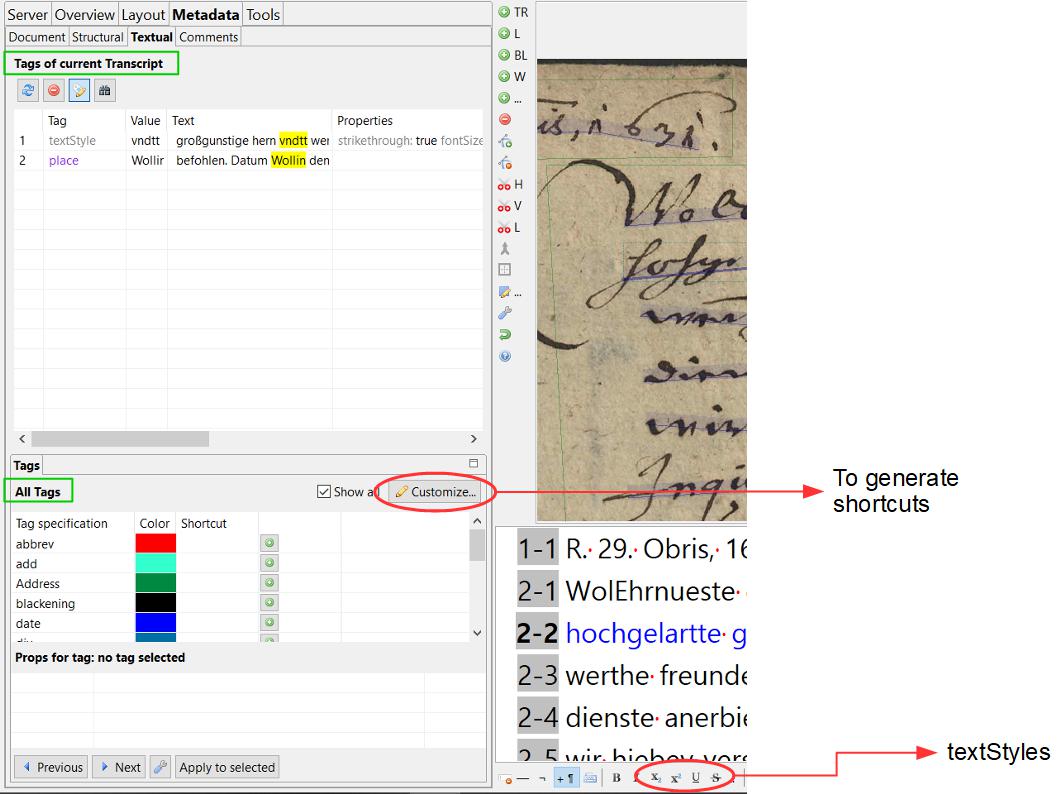
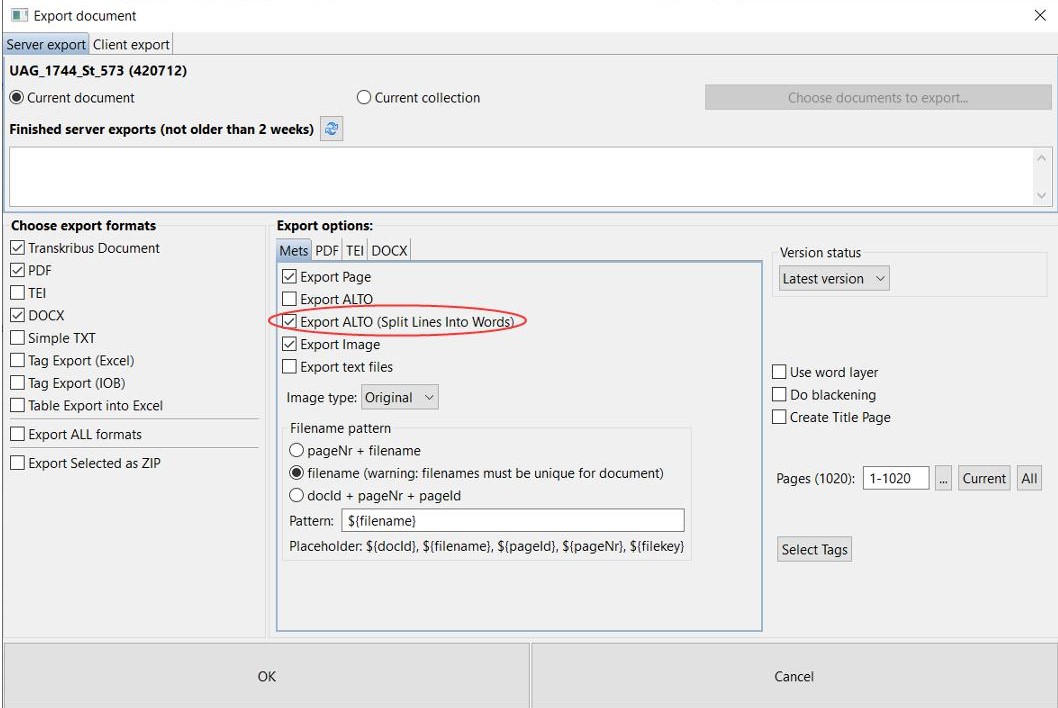
Tags can not only be exported separately, as in the form of an Excel table. Some tags (place or person) are also output in the ALTO files. These files are among other things responsible for the fact that we can display the hits of the full text search in our viewer/presenter. To do this, simply select “Export ALTO (Split lines into words)” when exporting the METS files.
In our presenter in the Digital Library Mecklenburg-Vorpommern the tags are then displayed as “named entities” separated by places and persons for the respective document. The whole thing is still in the experimental phase and will be further developed in the near future so that you can jump directly to the corresponding places in the document via an actual tag cloud.