
Generic vs. specialized model
Release 1.7.1
Did you notice in the graph for the model development that the character error rate (CER) of the last model got slightly worse again? Despite the fact that we had significantly increased the GT input? We had about 43,000 more words in training but the average CER deteriorated from 2.79% to 3.43%. We couldn’t really explain that.
At this point we couldn’t get any further with more and more GT. So we had to change our training strategy. So far we had trained large models, with writings from a total period of 70 years and more than 500 writers.
Our first suspicion fell on the concept writings, of which we already knew that the machine (LA and HTR) – just like ourselves – had its problems with it. During the next training we excluded these concept writings and trained exclusively with “clean” office writings. But that didn’t lead to a noticeable improvement: the Test Set-CER dropped from 3.43% to just 3.31%.
In the following trainings, we additionally focused on a chronological seuqencing of the models. We split our material and created two different models: Spruchakten_M_3-1 (Spruchakten 1583-1627) and Spruchakten_M_4-1 (Spruchakten 1627-1653).
With these new specialized models we actually achieved an improvement of the HTR – where the generic model was no longer sufficient. In the test sets several pages showed an error rate of less than 2 %. In the case of the model M_4-1, many CERs of single pages remained below 1 % and two pages were with 0 % even free of any errors.
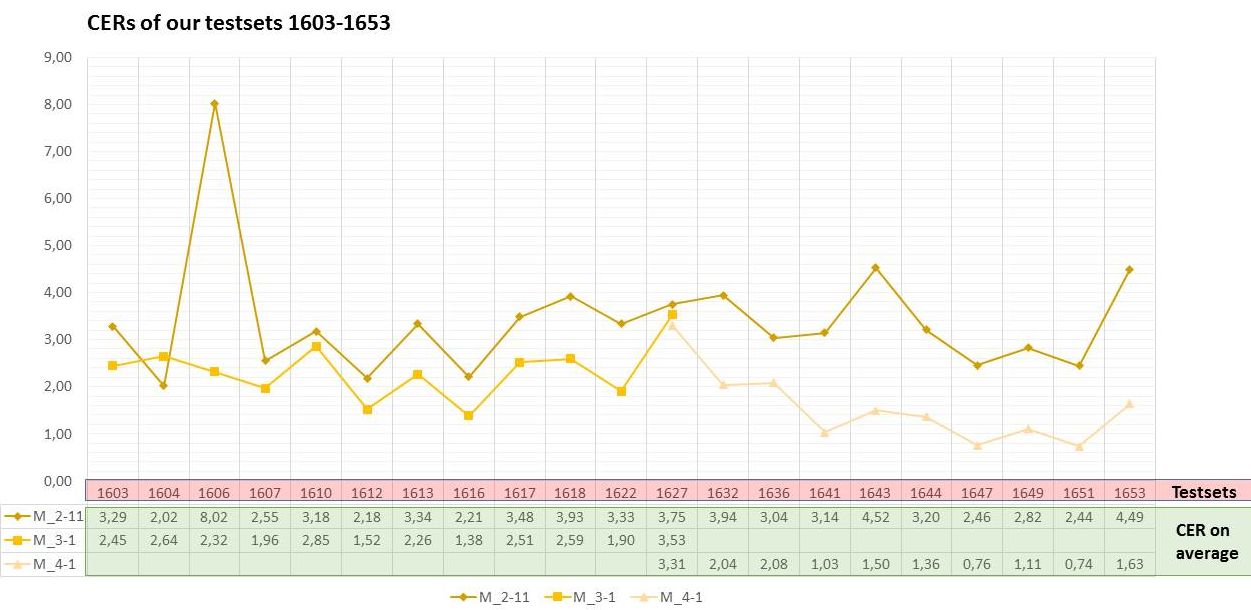
Whether an generic or specialized model will help and produce better results depends a lot on the size and composition of the material. In the beginning, when you are keen to progress as quickly as possible (the more, the better), an generic model is useful. However, if that reaches its limits, you shouldn’t “overburden” the HTR any further, but instead specialize your models.