Collaboration – Versions Management
Release 1.7.1
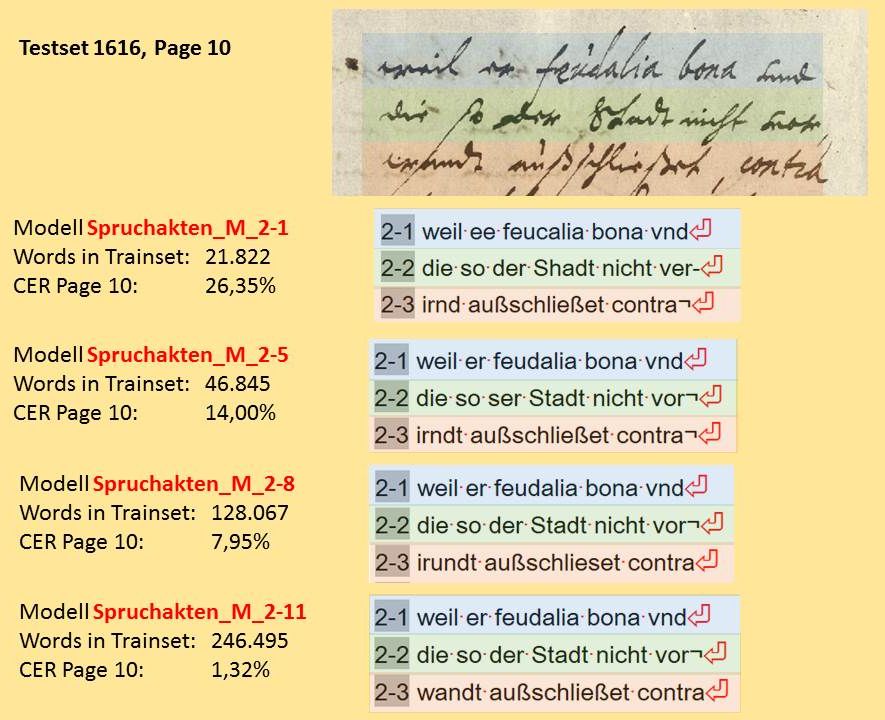
The second important element for organized collaboration is the version management of Transkribus. In the toolbar it seems rather inconspicuous, but it is enormously important. Transkribus stores a version of the currently edited page each time it is saved. It contains the current status of the layout work and content processing.
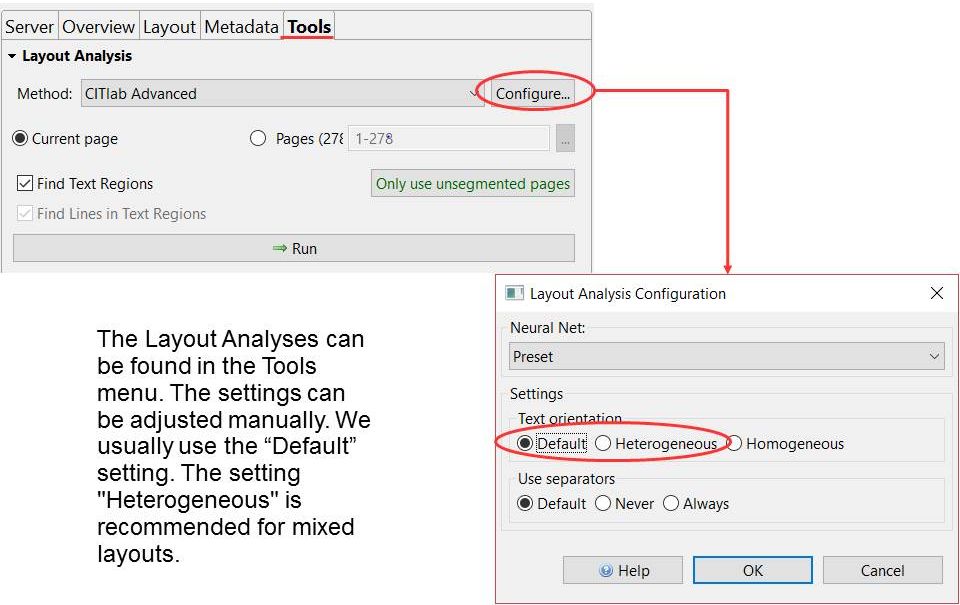
These versions are provided with an “edit status” so that they can be easier distinguished. A newly uploaded Document contains only pages with the edit status “new”. As soon as you edit a page, the edit status automatically changes to “in progress”. The three other status options – “done”, “final” and “Ground Truth” – can only be set manually.
The logical time to set such a “higher” status depends on the agreements within the team. We use versions management mostly during the production of training material – Ground Truth. All pages that have a finished layout analysis are set to “done” so that the transcribers and editors know that this page can now be finished by them. This status will not be changed until the page has a 100% secure transcription. Then it will be set to “Ground Truth” or “final”. All pages with the status “GT” will later be used as training material for HTR models, while the pages with edit status “final” will be used to create the test sets.
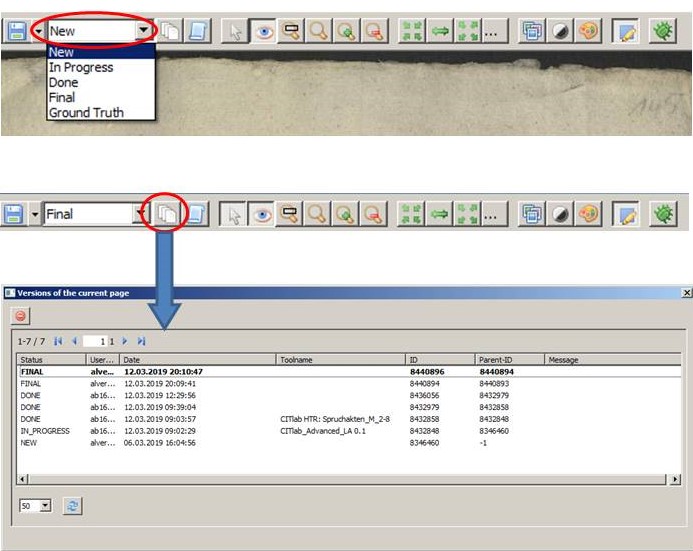
Each collaborator can access and edit or delete all versions of a page at any time. The edit status helps him to find the desired version faster. In addition to the edit status, the last editor and the save time are displayed for each version. If the version was edited with an automatic process (layout analysis or HTR), this is also commented. Thus, the processing steps are traceable in detail.
Tips & Tools
You can have multiple versions with the same status.
You can set any version to any other status – except to “New”.
You can delete single or multiple versions – except final versions, which cannot be deleted.