Kollaboration – Versions Management
Release 1.7.1
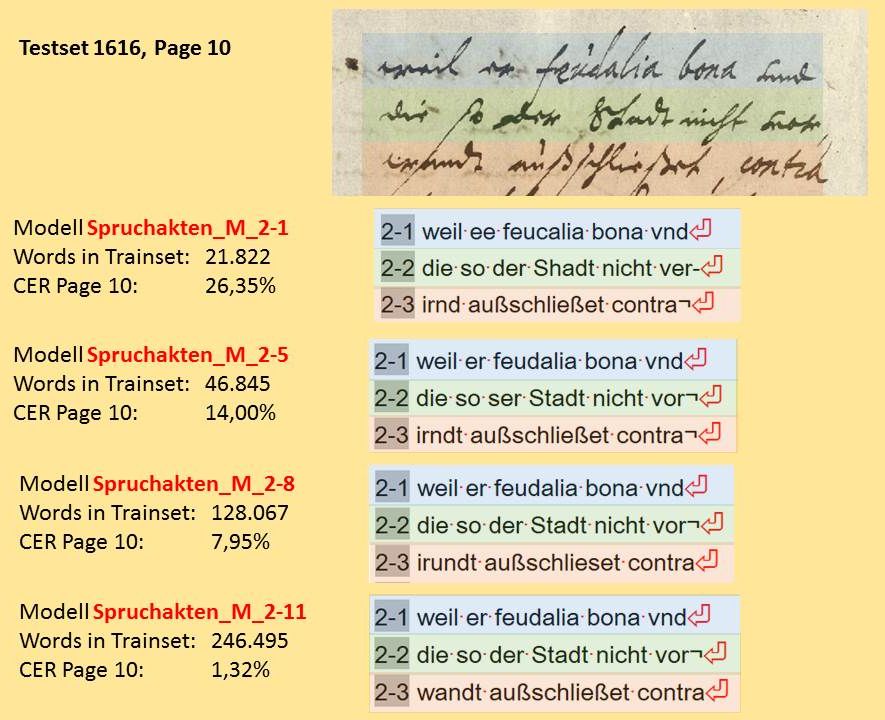
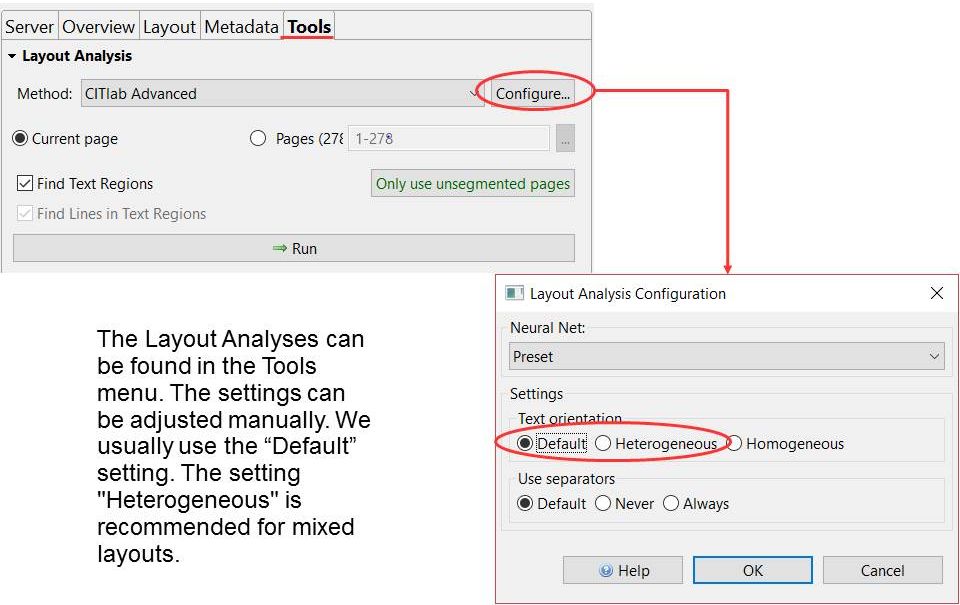
Das zweite wichtige Element für organisierte Kollaboration ist das Versionsmanagement von Transkribus. In der toolbar wirkt es eher unscheinbar, ist aber enorm wichtig. Transkribus legt nämlich bei jedem Speichern eine Version der gerade bearbeiteten page ab, die den aktuellen Stand der Layout- und Inhaltsbearbeitung enthält.
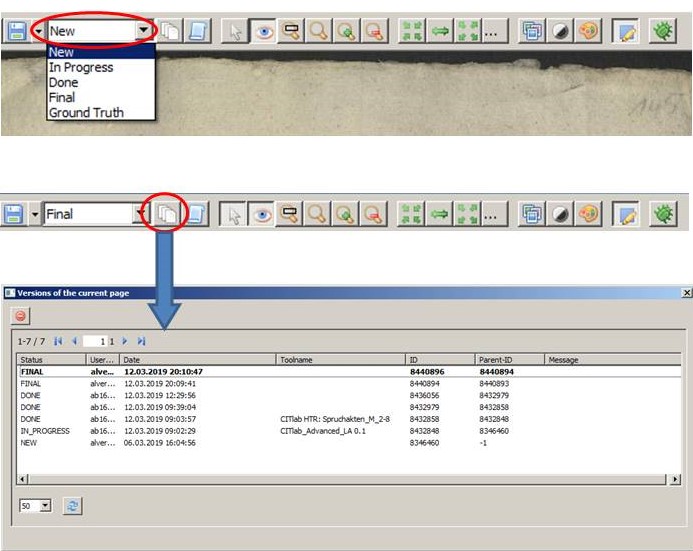
Diese Versionen werden – damit man sie besser unterscheiden kann – mit einem „edit status“ versehen. Ein neu hochgeladenes Dokument enthält nur pages mit dem edit status „new“. Sobald ihr eine page bearbeitet, wechselt der edit status automatisch auf „in progress“. Die drei übrigen Statusanzeigen – „done“, „final“ und „Ground Truth“ – können nur manuell gesetzt werden.
Wann man einen solchen „höheren“ Status setzt, hängt von den Absprachen im Team ab. Wir benutzen das Versionsmanagement vor allem bei der Produktion von Trainingsmaterial – Ground Truth. Dabei werden alle Seiten, die eine fertige Layout Analyse haben auf „done“ gesetzt, damit die Transcriber und Editors wissen, dass diese Seite jetzt von ihnen bearbeitet werden kann. Dieser Status wird nicht verändert, bis die Seite mit einer hundertprozentig sicheren Transkription versehen ist. Dann wird sie auf „Ground Truth“ oder „final“ gesetzt. Alle Seiten mit dem Status „GT“ werden später als Trainingsmaterial für HTR-Modelle genutzt, während aus den Seiten mit edit status „final“ die Testsets gebildet werden.
Jeder Kollaborator kann jederzeit alle Versionen einer Seite aufrufen und bearbeiten oder auch löschen. Der edit staus hilft ihm dabei, die jeweils gewünschte Version schneller zu finden. Neben dem edit status wird bei jeder Version der letzte Bearbeiter und der Speicherzeitpunkt angezeigt. Falls die Version mit einem automatischen Prozesse (Layout Analyse oder HTR) bearbeitet wurde, wird das ebenso kommentiert. So sind die Bearbeitungsschritte detailliert nachvollziehbar.
Tipps & Tools
Ihr könnt mehrere Versionen mit demselben Status haben.
Ihr könnt jede Version in einen beliebigen anderen Status versetzen – außer in „New“.
Ihr könnt einzelne oder mehrere Versionen löschen – außer Final-Versionen, die sind unlöschbar.