Transcribing without layout analysis?
Release 1.10.1
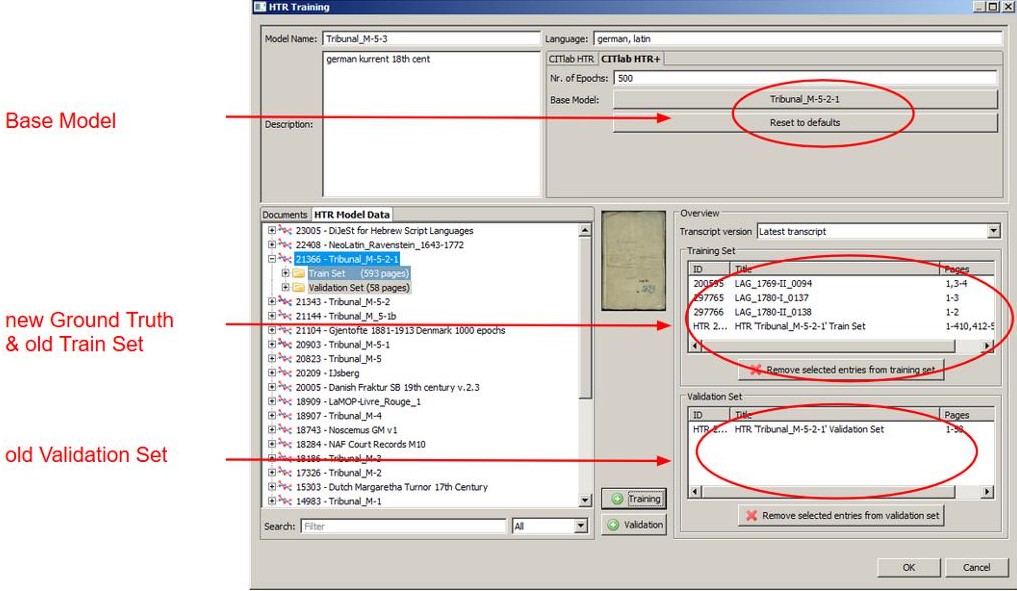
We have emphasized in previous posts how important LA is. Without it, an HTR model, no matter how good it is, has no chance of transcribing a text properly. The steps of automatic LA (or a P2PaLA model) and HTR are usually initiated separately. Now we noticed that when an HTR model runs over a completely new or unedited page, the program automatically executes an LA.
This LA runs with the default settings of CITLab-Advanced LA. On pure pages, fewer lines have to be merged and sometimes more than one text region is recognized.
![]()
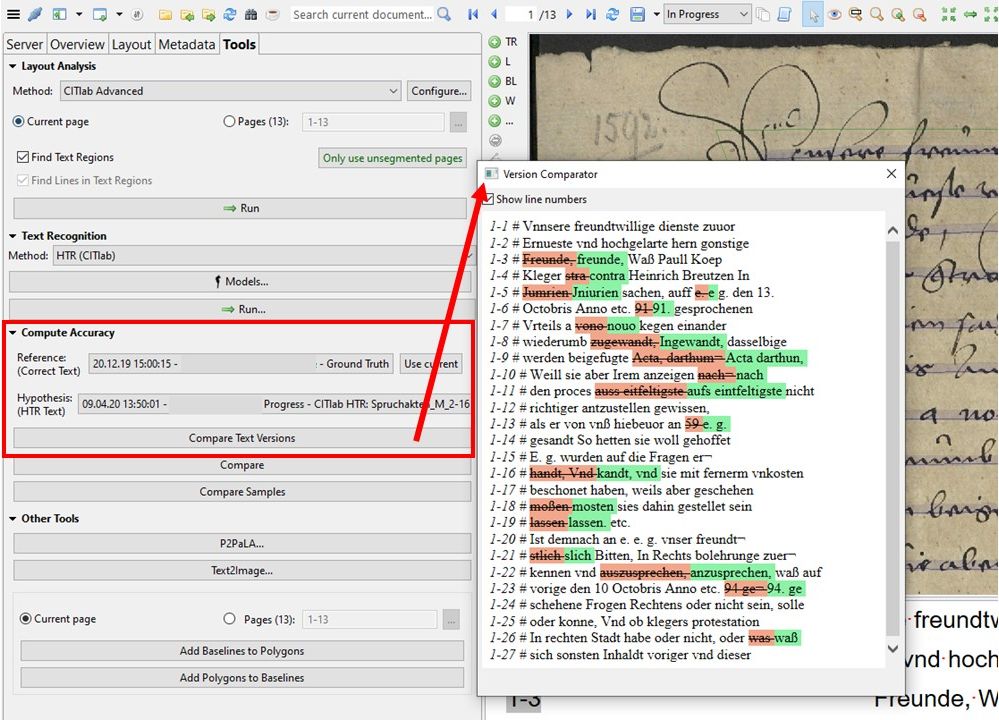
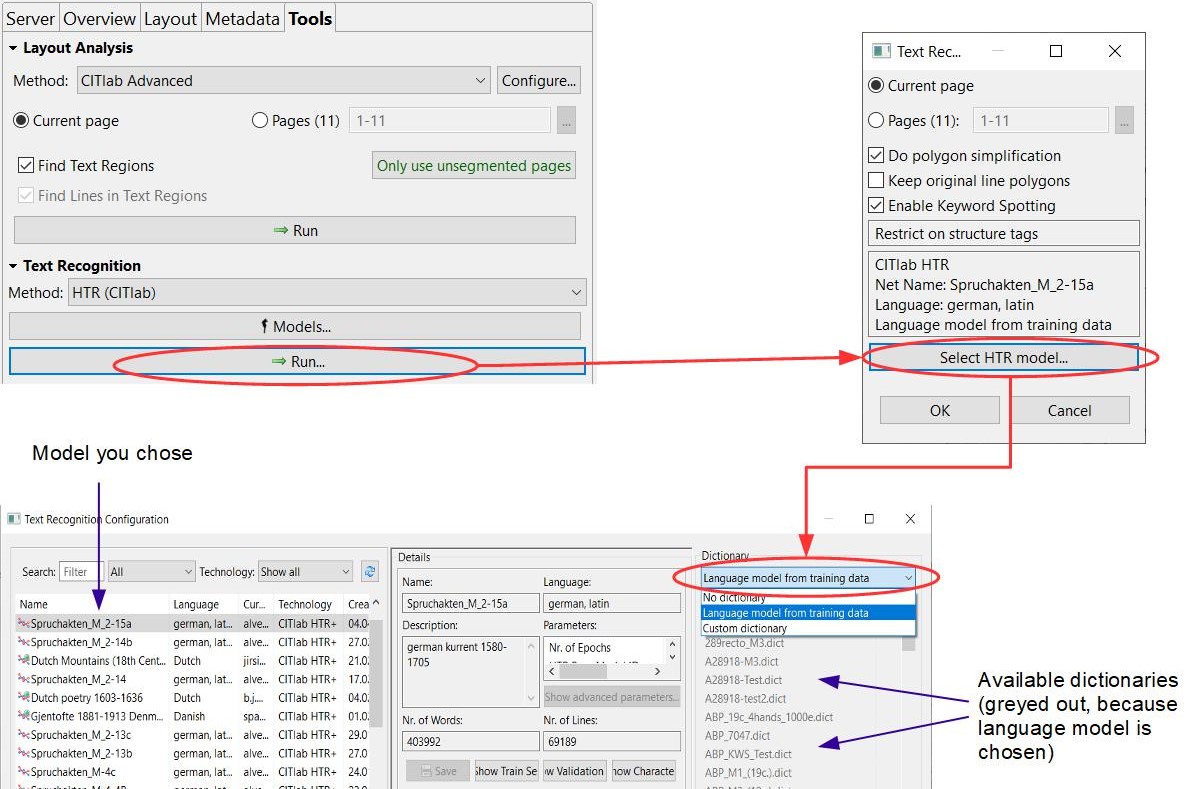
But it also means that only horizontal text is recognized. We had the same problem with our P2PaLA models. Everything that is slanted or vertical cannot be recognized this way. To do this, the LA must be initiated manually, with the setting ‘Text Orientation’ set to ‘Heterogeneous’.
![]()
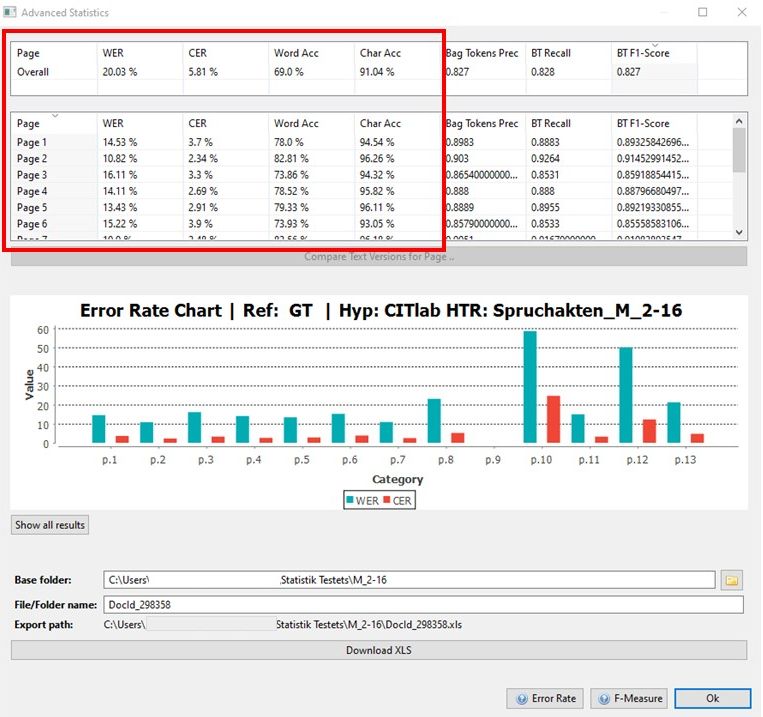
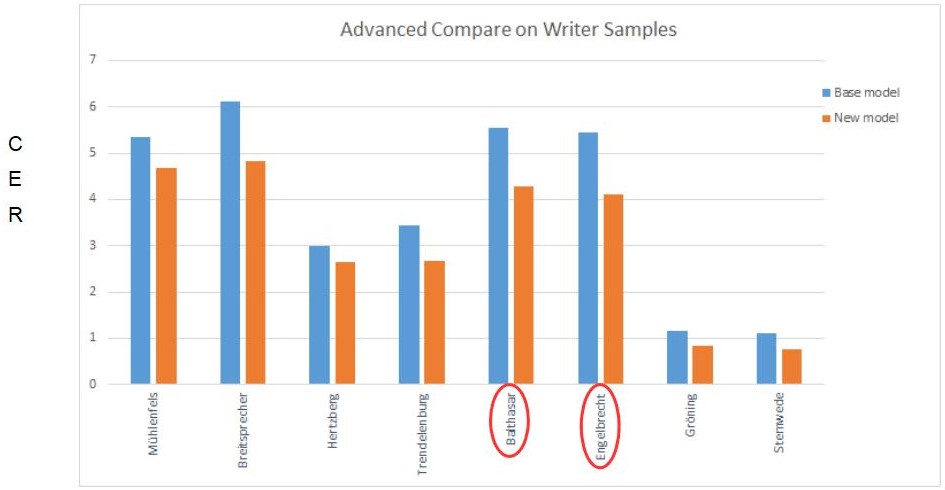
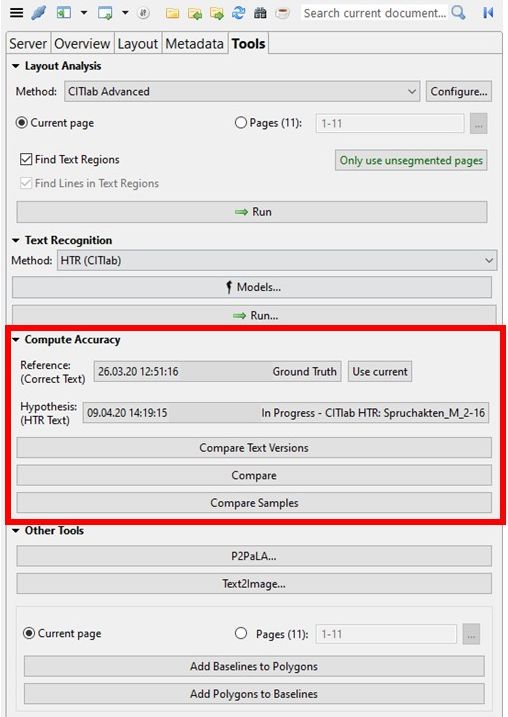
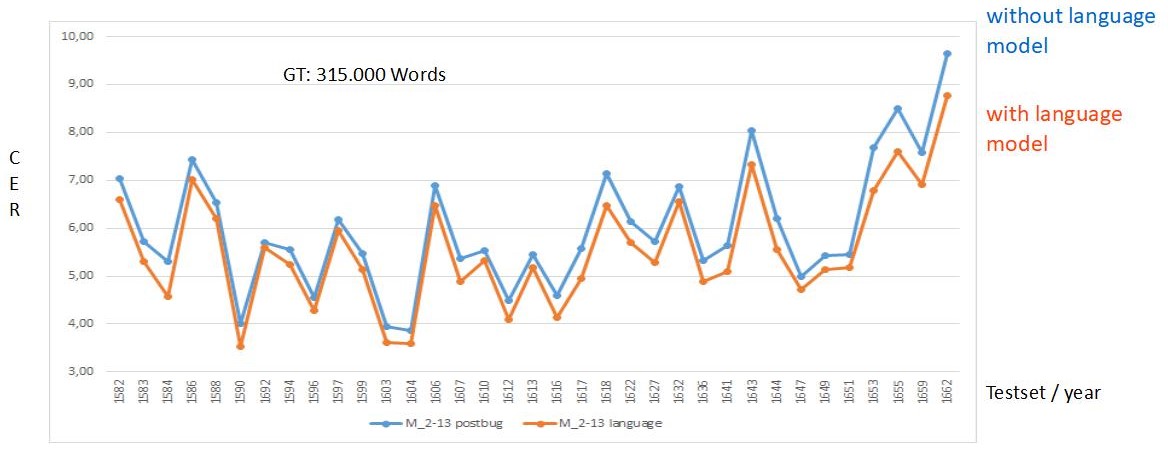
Interestingly, the HTR results are better with this method than with an HTR that has been run over a corrected layout analysis. We have calculated the CER for some pages to show this.
![]()
Thus this method is a very good alternative, especially for pages with an uncomplicated layout. You save time, because you only have to initiate one process, and in the end you have a better result.