
Use Case: Extend and improve existing HTR-Models
Release 1.10.1
In the last post we described that a base model can pass on everything it has “learned” to the new HTR model. With additional ground truth, the new model can then extend and improve its capabilities.
Here is a typical use case: In our subproject on the Assessor Relations of the Wismar Tribunal we train a model with eight different writers. The train set contains 150,000 words, the CER was 4.09% in the last training. However, the average CER for some writers was much higher than for others.
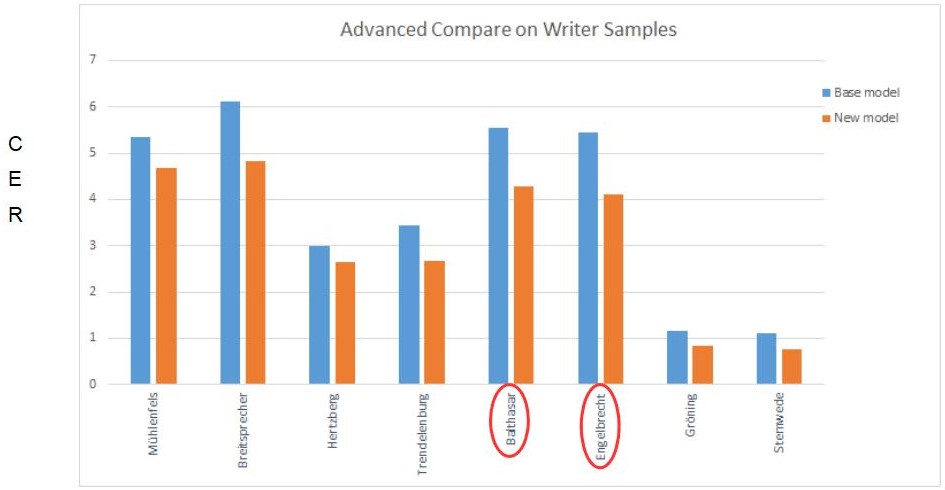
So we decided to do an experiment. We added 10,000 words of new GT for two of the obvious writers (Balthasar and Engelbrecht)and used the Base Model as well as its Training and Validation Set for the new training.
As a result, the new model had an average CER of 3.82% – it had improved. But what is remarkable is that not only the CER of the two writers for which we had added new GT was improved – in both cases up to 1%. Also the reliability of the model applied to the other writers did not suffer, but was reduced as well.