Toolbar – die wichtigsten Werkzeuge und wie man sie benutzt, Teil 1
Release 1.7.1
Layouts erstellen

So sieht die Toolbar bei einem neuen Image aus. Wenn eine CITlab Advanced LA über das Image gelaufen ist, können auch die anderen Tools aktiviert werden. Wenn das Layout von Hand gemacht werden soll, sind vor allem die beiden Tools in den oberen Kreisen wichtig. TR steht für Textregion, das erste was bei einem Layout erstellt werden muss. Damit wird festgelegt welche Bereiche des Images Text haben und welche nicht. Wenn der Text nicht richtig in eine Textregion passt, zieht ihr diese zuerst grob und passt sie später an. Anschließend können mit „BL“ die Baselines gezogen werden. Von den unteren Tools ist nur der grüne, halbrunde Pfeil wichtig. Dies ist das Tool „undo“; wie der Name schon sagt, dient es um Aktionen rückgängig zu machen.
Tipps & Tools
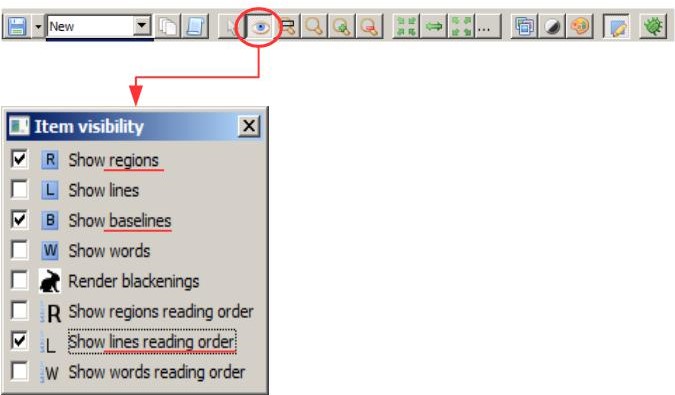
„Item visibility“ ist ein Hilfsmittel um das Dokument für euch übersichtlicher zu gestalten. Wenn es angeklickt ist, erscheint ein Kasten, in dem ausgewählt kann, was im aktuellen Image zu sehen sein soll. Wichtig sind vor allem die TR und die BL, nicht nur wenn das Layout bearbeitet wird, sondern auch bei der späteren Transkription. Diese beiden Kästen sind in der Voreinstellung eigentlich immer abgehackt, wenn die Anzeige der BL stört müsst ihr sie also manuell deaktivieren. Auch wichtig für die Korrektur des Layouts ist die Lines Reading Order, also in welcher Reihenfolge die Zeilen später von der HTR gelesen werden. Wenn die Reading Order angezeigt ist, kann man schnell sehen, ob die Layoutanalyse zuverlässig gearbeitet hat. Diese Anzeige ist jedoch für die Transkription von Hand meist störend, dort solltet ihr sie wieder ausblenden.