Word Error Rate & Character Error Rate – How to evaluate a model
Release 1.7.1
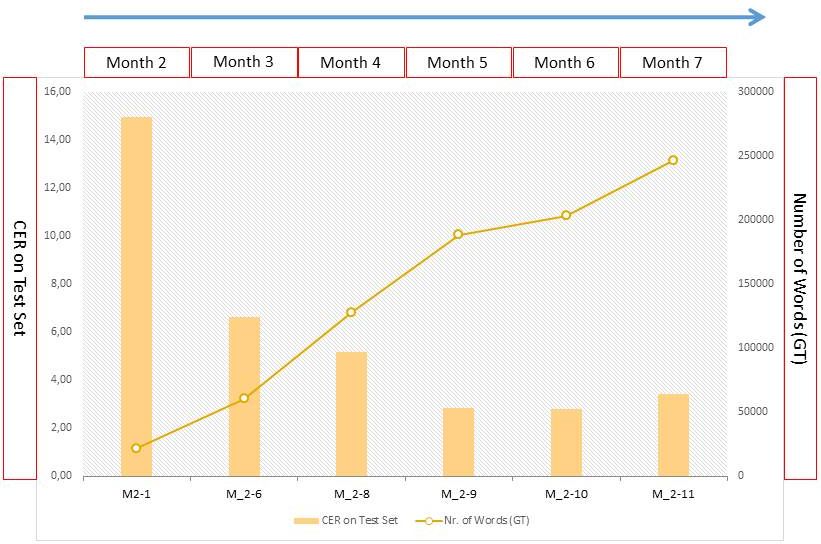
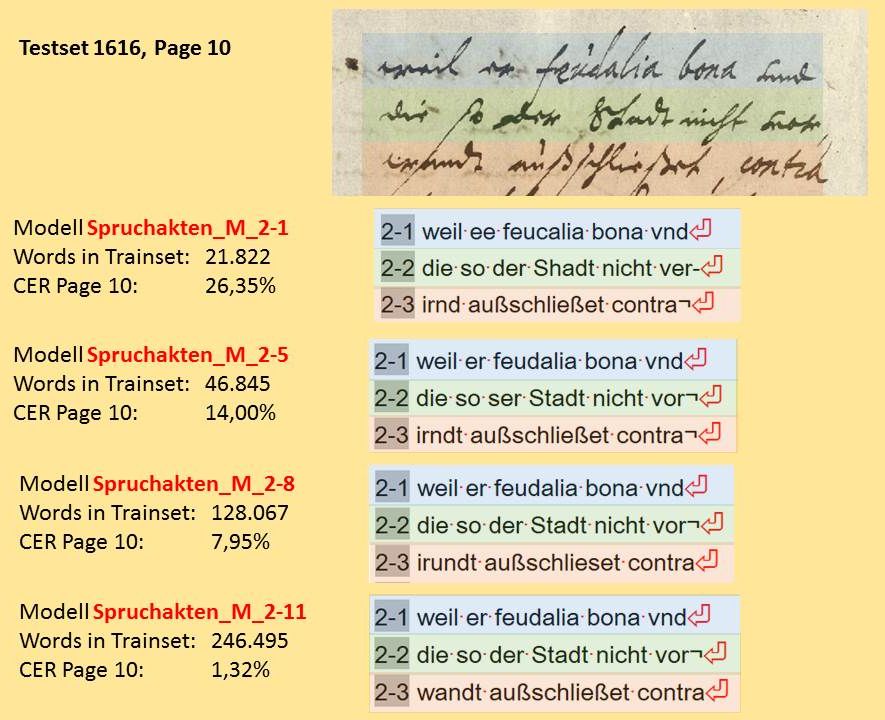
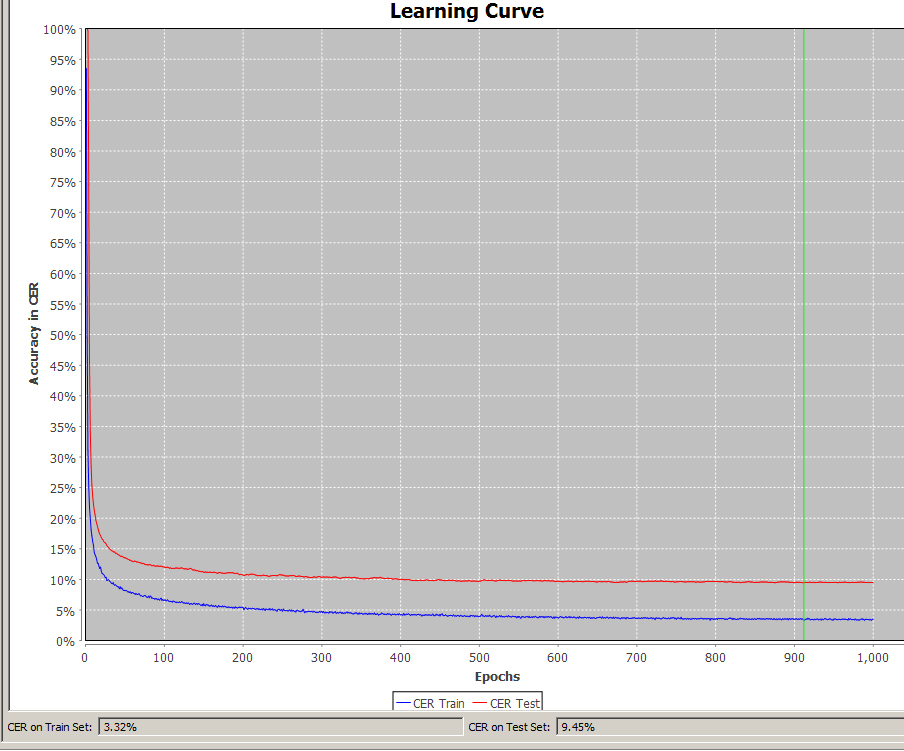
The Word Error Rate (WER) and Character Error Rate (CER) indicate the amount of text in a handwriting that the applied HTR model did not read correctly. A CER of 10% means that every tenth character (and these are not only letters, but also punctuations, spaces, etc.) was not correctly identified. The accuracy rate would therefore be 90 %. A good HTR model should recognize 95% of a handwriting correctly, the CER is not more than 5%. This is roughly the value that is achieved today with “dirty” OCR for fracture fonts. Incidentally, an accuracy rate of 95% also corresponds to the expectations formulated in the DFG’s Practical Rules on Digitization.
Even with a good CER, the word error rate can be high. The WER shows how good the exact reproduction of the words in the text is. As a rule, the WER is three to four times higher than the CER and is proportional to it. The value of the WER is not particularly meaningful for the quality of the model, because unlike characters, words are of different lengths and do not allow a clear comparison (a word is already incorrectly recognized if just one letter in it is not correct). That is why the WER is rarely used to characterize the value of a model.
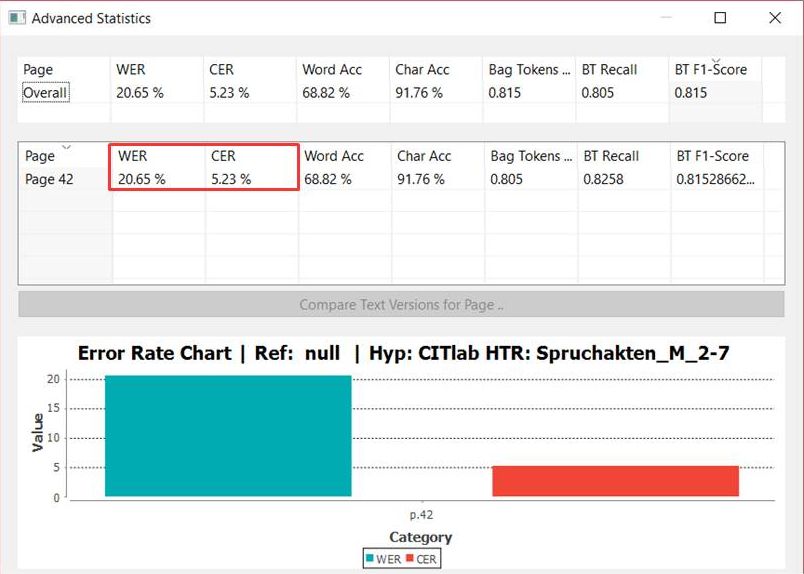
The WER, however, gives clues to an important aspect. Because when I perform a text recognition with the aim of later performing a full text search in my document, the WER shows me the exact success rate that I can expect in my search. The search is for words or parts of words. So no matter how good my CER is: with a WER of 10%, potentially every tenth search term cannot be found.
Tips & Tools
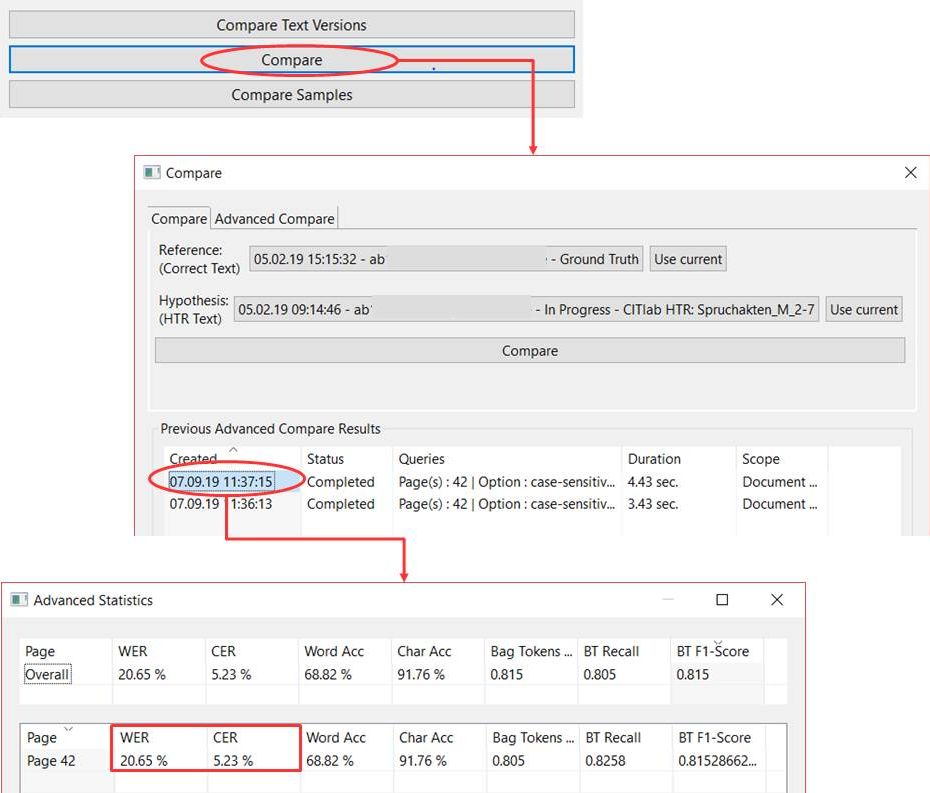
The easiest way to display the CER and WER is to use the Compare function under Tools. Here you can compare one or more pages of a Ground Truth version with an HTR text to estimate the quality of the model.