The more, the better – how to generate more and more GT?
Release 1.7.1
To make sure that the model can reproduce the content of the handwriting as accurately as possible, learning requires a lot of Ground Truth; the more, the better. But how do you get as much GT as possible?
It takes some time to produce a lot of GT. When we were at the beginning of our project and had no models available yet, it took us one hour to transcribe 1 to 2 pages. That’s an average of 150 to 350 words per hour.
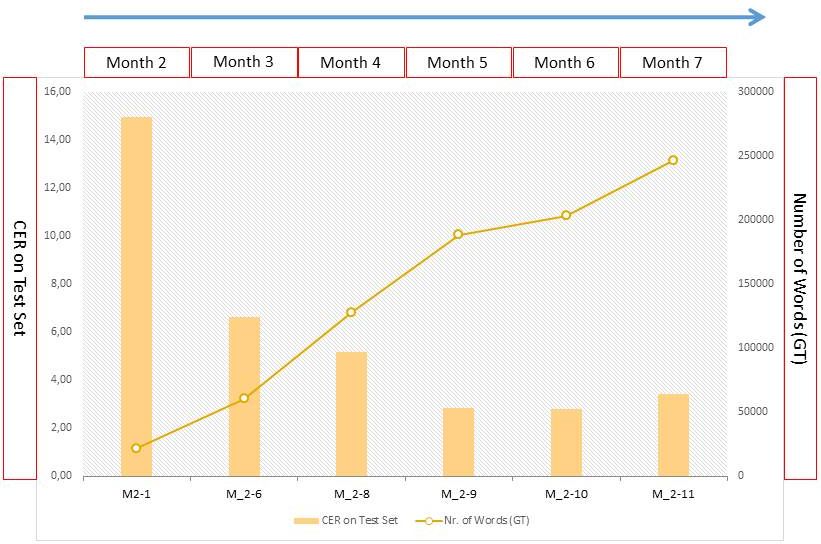
Five months later, however, we had almost 250,000 words in training. We neither had a legion of transcribers nor did one person have to write GT day and night. Just the exponential improvement of the models themselves enabled us to produce more and more GT:
The more GT you invest, the better your model will be. The better your model reads, the easier it will be to write GT. You don’t have to write by yourself anymore, you just correct the HTR. With models that have an average error rate of less than 8%, we’ve produced about 6 pages of GT per hour.
The better the model reads, the more GT can be produced and the more GT there is, the better the model will be. What is the opposite of a vicious circle?