How to create test sets and why they are important, #2
Release 1.7.1
What is the best procedure for creating test sets?
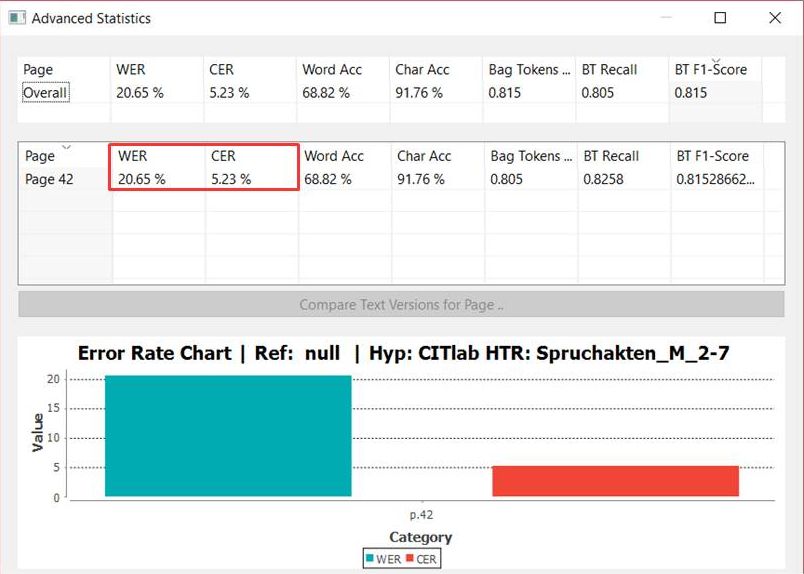
In the end, everyone can find their own way. In our project, the pages for the test sets are already selected during the creation of the GT. They receive a special edit status (Final) and are later collected in separate documents. This ensures that they will not accidentally be put into training. Whenever new GT is created for future training, the material for the test set is also extended at the same time. So both sets grow in proportion.
For the systematic training we create several Documents, which we call “test sets” and which are each related to a single Spruchakte (one year). For example, we create a “test set 1594” for the Document of the Spruchakte 1594. Here, we place representatively selected images, which should reflect the variety of writers as exactly as possible. In the “mother document” we mark the pages selected for the test set as “Final” to make sure that they will not be edited there in the future. We have not created a separate test set for each singel record or year, but have proceeded in five-year steps.

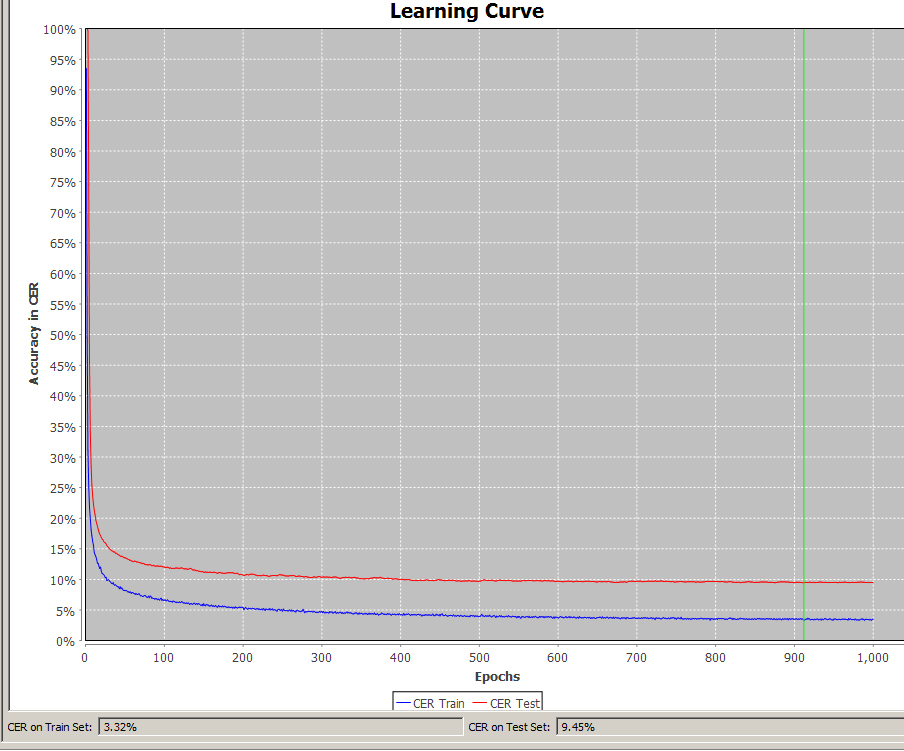
Since a model is often trained over many rounds, this procedure also has the advantage that the test set always remains representative. The CERs of the different versions of a model can therefore always be compared and observed during development, because the test is always executed on the same (or extended) set. This makes it easier to evaluate the progress of a model and to adjust the training strategy accordingly.
Transkribus also stores the test set used for each training session in the affected collection independently. So you can always fall back on it.
It is also possible to select a test set just before the training and simply assign individual pages of the documents from the training material to the test set. This may be a quick and pragmatic solution for the individual case, but it is not suitable for the planned development of powerful models.