Use Case: “Model Booster”
Release 1.10.1
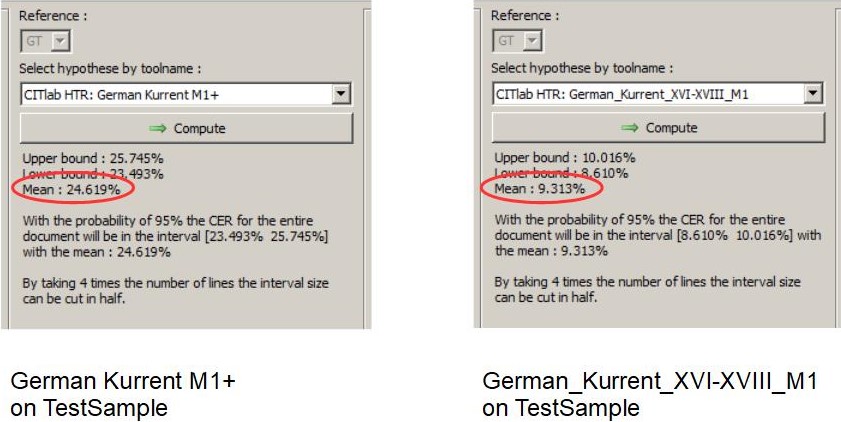
In our example we want to improve our HTR model for the Responsa. This is an HTR model that can read 17th century Kurrent documents. In the search for a possible base model, you can find two candidates in the “public models” of Transkribus: “German Kurrent M1+” from the Transkribus Team and “German_Kurrent_XVI-XVIII_M1” from Tobias Hodel. Both could fit. But the test on the Sample Compare shows that “German_Kurrent_XVI-XVIII_M1” performed better with a predicted average CER of 9.3% on our sample set.
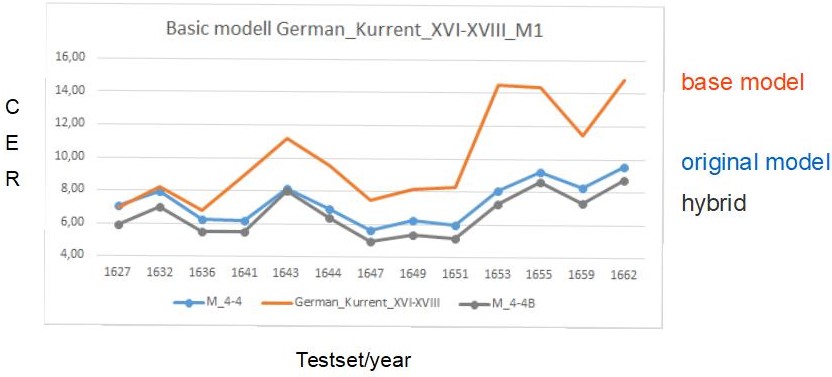
Therefore “German_Kurrent_XVI-XVIII_M1” was chosen as the base model for the training. Afterwards the Ground Truth of the Responsa (108.000 words) and also the Validation Set of our old model was added. The average CER of our HTR model has improved considerably after the Base Model Training, from 7.3% to 6.6%.As you can see in the graph, the base model on the test set reads much worse than the original model, but the hybrid of the two is better than either one. The improvement of the model can be seen in each of the years tested and is up to 1%.