Release 1.9.1
At another place of these blog you can find information and tips for structure tagging. This kind of tagging can be good for a lot of things – the following is about its use for an improved layout analysis. Because structure tagging is an important part of training P2PaLA models.
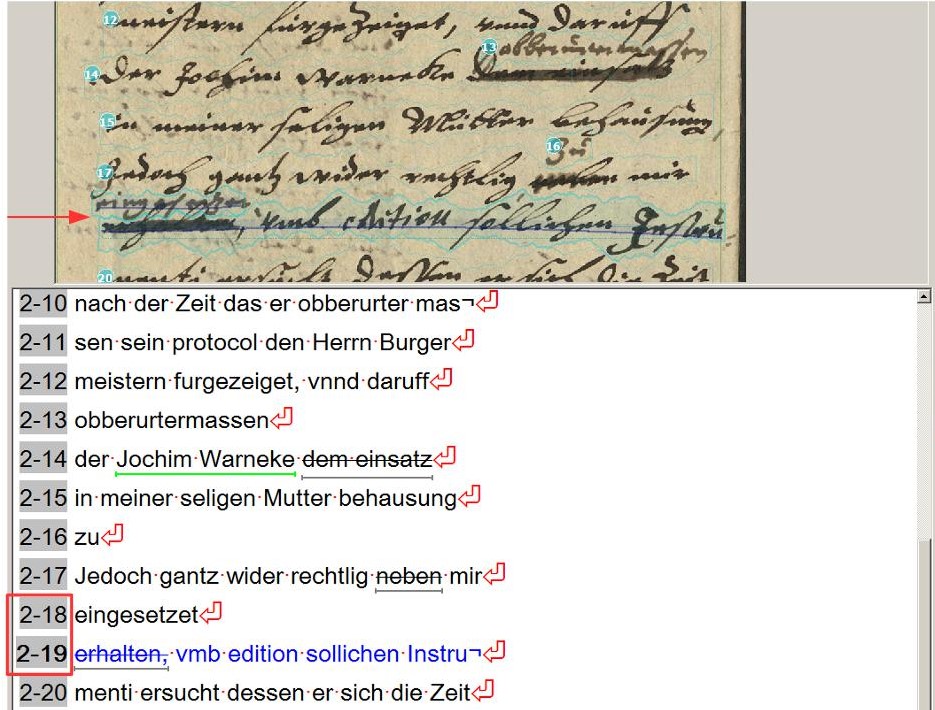
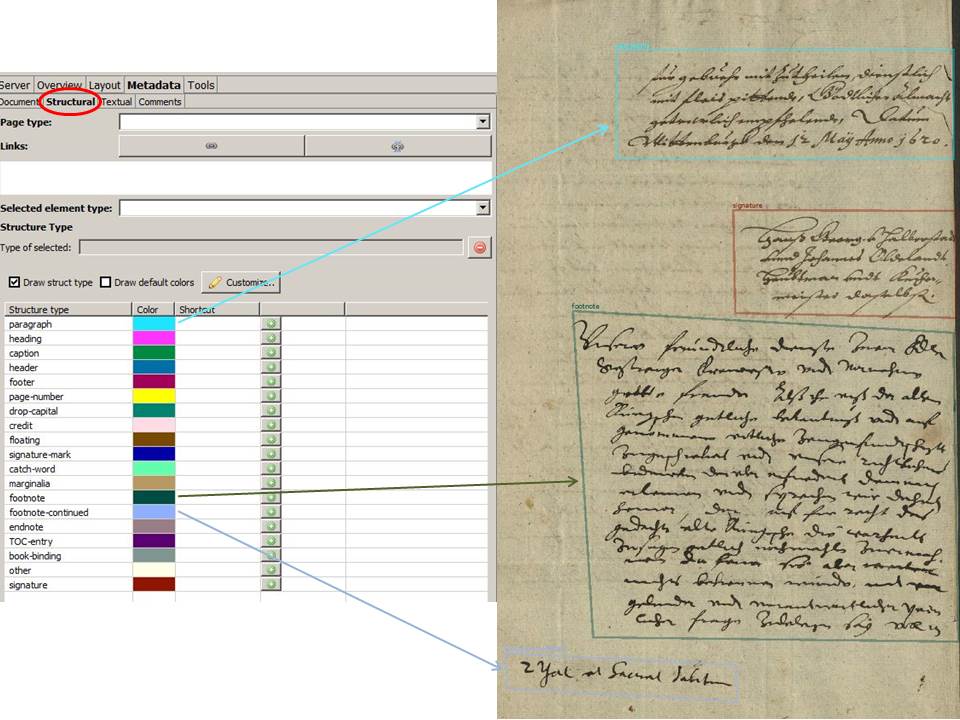
With our mixed layouts the standard LA simply had to fail. The material was too extensive for a manual creation of the layout. So we decided to try P2PaLA. For this we created training material for which we selected particularly “difficult” but at the same time “typical” pages. These were pages that contained, in addition to the actual main text, comments and additions and the like.

coll: UAG Strukturtagging, doc. UAG 1618-1, image 12
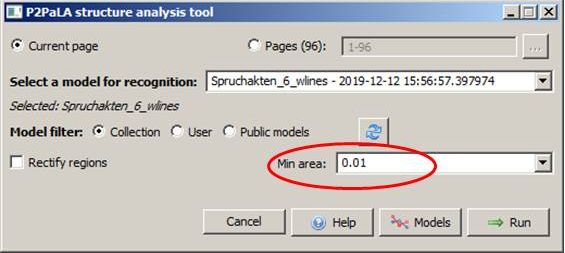
For the training material only the correctly drawn and tagged text regions are important. No additional line detection or HTR is required. However, it doesn’t bother either, so you can include pages that have already been completely edited in the training. However, if you take new pages on which only the TR has to be drawn and tagged, you’ll be faster. Then you can prepare eighty to one hundred pages for training in one hour.
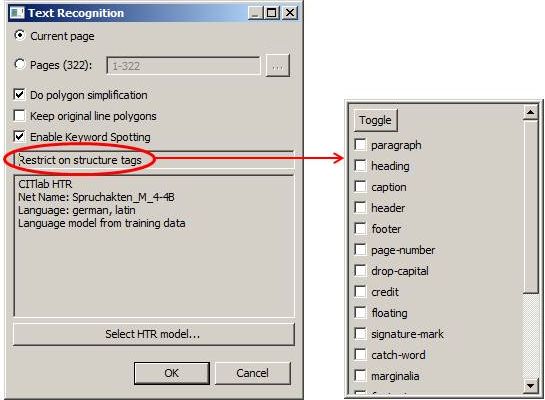
While we had tagged seven different structure types with our first model, we later reduced the number to five. In our experience, a too strong differentiation of the structure types has a rather negative effect on the training.
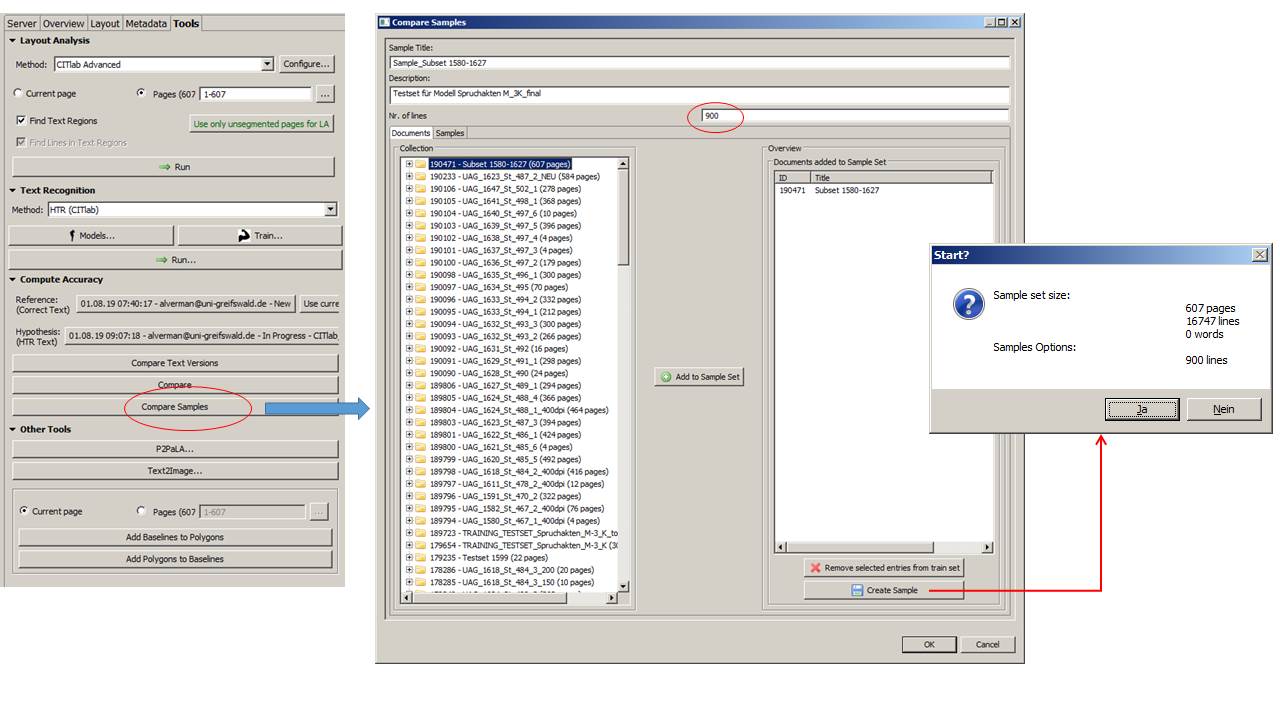
Of course, the success of the training also depends on the amount of training material you invest. According to our experience (and based on our material) you can make a good start with 200 pages, with 600 pages you get a model you can already work with; from 2000 pages on it is very reliable.
Tips & Tools
When you create the material for structure training, it is initially difficult to realize that this is not about content. That means no matter what the content is, the TR in the middle is always the paragraph. Even if there is only one note in the middle and the concept is much longer and more important. This is the only way to really recognize the necessary patterns during training.