Test samples – the impartial alternative
If a project concept does not allow the strategic planning and organization of test sets, there is a simple alternative: automatically generated samples. Samples are also a valuable addition to the manually created test sets, because here it is the machine that decides which material is included in the test and which is not. Transkribus can select individual lines from a set of pages that you have previously provided. So it’s a more or less random selection. This is worthwhile for projects that have a lot of material at their disposal – including ours.
We use samples as a cross-check to our manually created test sets and because samples are comparable to the statistical methods of random sampling, which the DFG also recommends in its rules of practice for testing the quality of OCR.
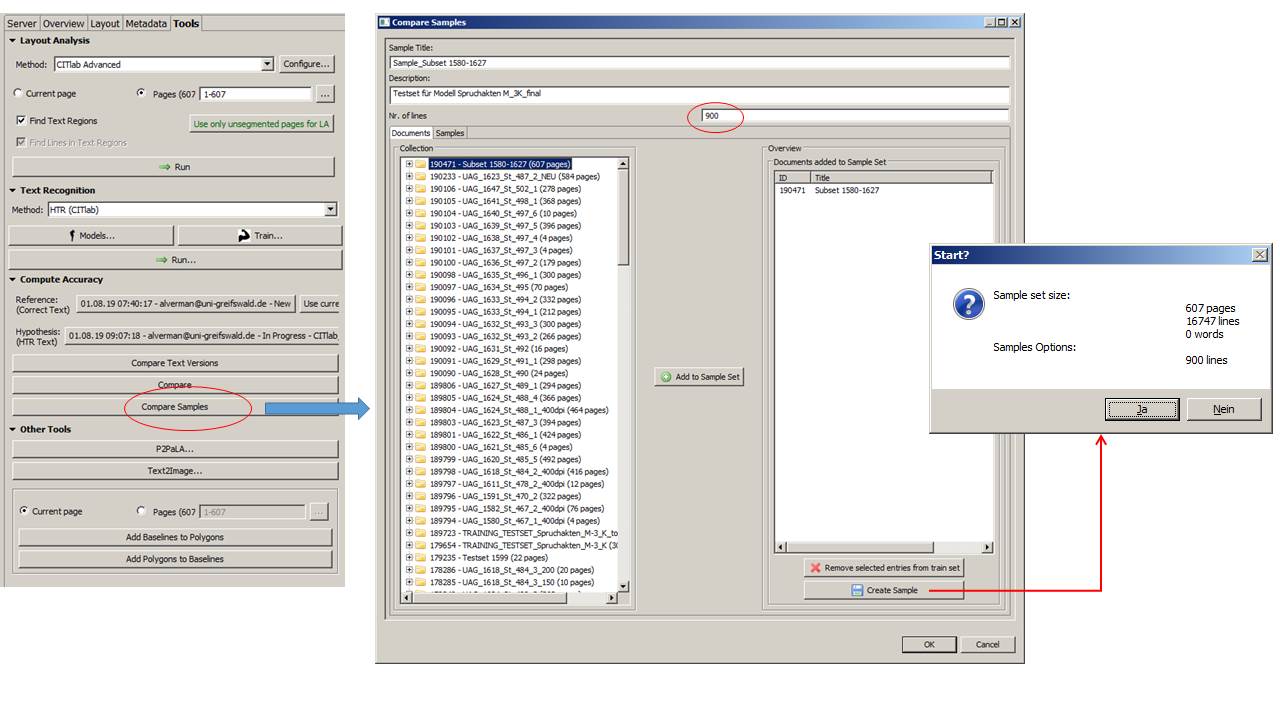
Because HTR – unlike OCR – is line-based, we modify the DFG’s recommendation somewhat. I will explain this with an example: For our model Spruchakten_M-3K, a check should be carried out on the reading accuracy achieved. For this purpose we created a sample, exclusively from untrained material of the whole period for which the model works (1583-1627). To do this, we selected every 20th page from the entire data set, obtainimg a subset of 600 pages. It represents approximately 3.7% of the total 16,500 pages of material available for this period. All this is done on your own network drive. After uploading this subset to Transkribus and processing it with the CITlab Advanced LA (16.747 lines were detected), we let Transkribus create a sample from it. It contains 900 randomly selected lines. This is about 5% of the subset. This sample was now provided with GT and used as a test set to check the model.
And this is how it works in practice: The “Sample Compare” function is called up in the “Tools” menu. Select your subset in the collection and add it to the sample set pressing the “add to sample” button. Then specify the number of lines Transkribus should select from the subset. Here you should select at least as many lines as there are pages in the subset, so that each page has one test line.
In our case, we decided to use a factor of 1.5 just to be sure. The program now selects the lines independently and compiles a sample from them, which is saved as a new document. This document does not contain any pages, but only lines. These must now be transcribed as usual to create GT. Afterwards any model can be tested on this test set using the Compare function.