P2PaLA – Postprocessing
Release 1.9.1
Especially at the beginning of the development of a structure model, it occurred to us that the model recognized every irregularity in the layout as a TR. This leads to excessive – and unnecessary – many text regions. Many of these TRs were also extremely small.
The more training material you invest, the smaller the problem. In our case these mini TRs disappeared, after we had trained our model with about 1000 pages. Until then, they are annoying because removing them all by hand is tedious.
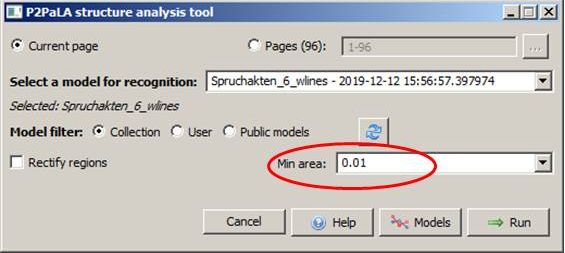
To reduce this labour you have two options. Firstly, starting the P2PaLA you can determine how large the smallest TR is allowed to be. For this you have to select the corresponding value in the “P2PaLA structure analysis tool” before starting the job (“Min area”).
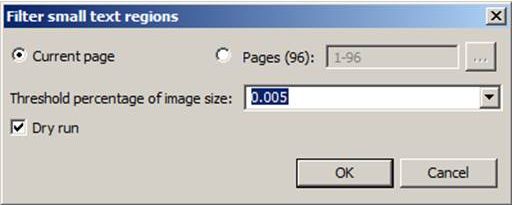
If this option does not bring the expected success, there is the option “remove small textregions”. You will find this on the left toolbar, under the item “other segmentation tools”. In the menu you can set the pages on which the filter should run as well as the size of the TR to be removed. The size is calculated in “Threshold percentage of image size”. Here the value can be calibrated finer than with the above mentioned option. If the images, as with our material, often have small notes, for example the marginalias where there is only a single word in a TR, then the smallest or second smallest value possible should be chosen. We usually use the “Threshold percentage” of 0.005.
Even with a good structural model, it may still be possible that individual TRs have to be manually merged, split or removed, but to a much lesser extent than the standard LA would require.
Tips & Tools
Important: If you want to be sure that you don’t remove too many TRs, you can start with a “dry run”. Then the number of potentially removable TRs will be listed. As soon as you uncheck the box, the affected TRs will be deleted immediately.