mixed layouts
Release 1.7.1
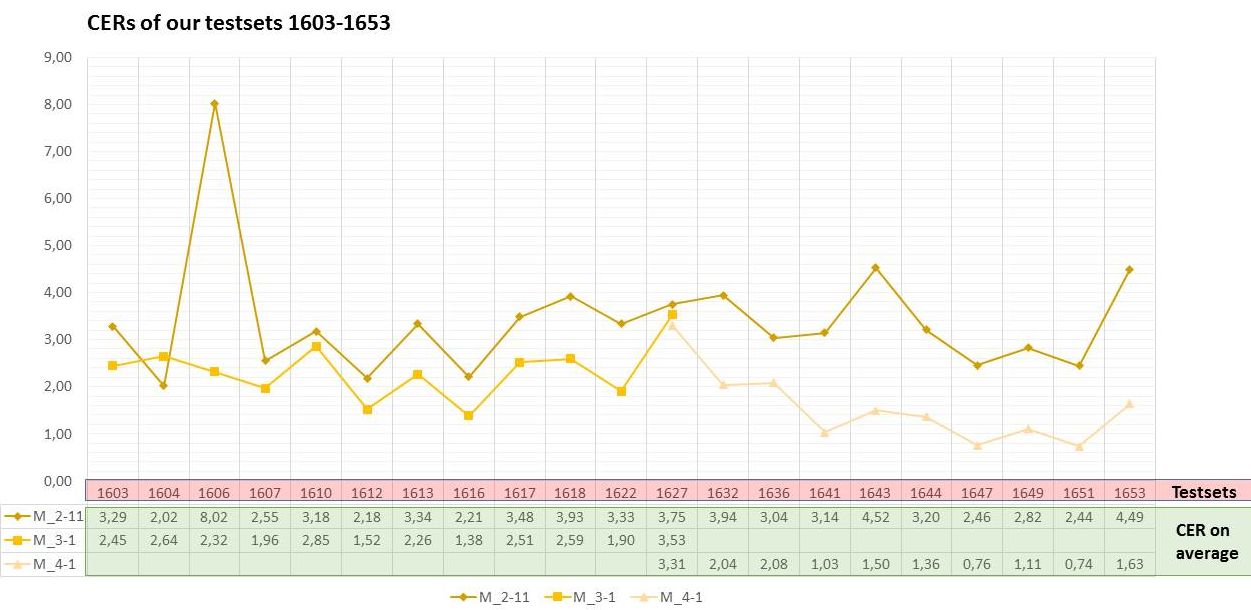
The CITlab Advanced Layout Analysis handles most “ordinary” layouts well – in 90% of the cases. Let’s talk about the remaining 10%.
We already discussed how to proceed in order to avoid trouble with the Reading Order. But what happens if we have to deal with really mixed – crazy – layouts, e.g. concept writings?

With complicated layouts, you’ll quickly notice that the manually drawn TRs overlap. That’s not good – because in such overlapping text regions the automatic line detection doesn’t work reliably. This problem is easily solved because TRs can have shapes other than square. They can be drawn as polygons and are therefore easily separated from each other.
It makes sense to add structural tags if there are many text regions in order to be able to distinguish them better. You can also assign them to certain processing routines during later processing. This is a small effort with great benefits, because the structural tagging is not more complex than the tagging in context.
Tips & Tools
Automatic line detection can be a real challenge here. Sections where you can already predict (with a little experience) that this won’t happen are best handled manually. For automatic line detection, CITlab Advanced should be configured so that the default setting is replaced by “heterogeneous”. The LA will now take both horizontal and vertical or skewed and oblique lines into account. This will take a little longer, but the result will be better.
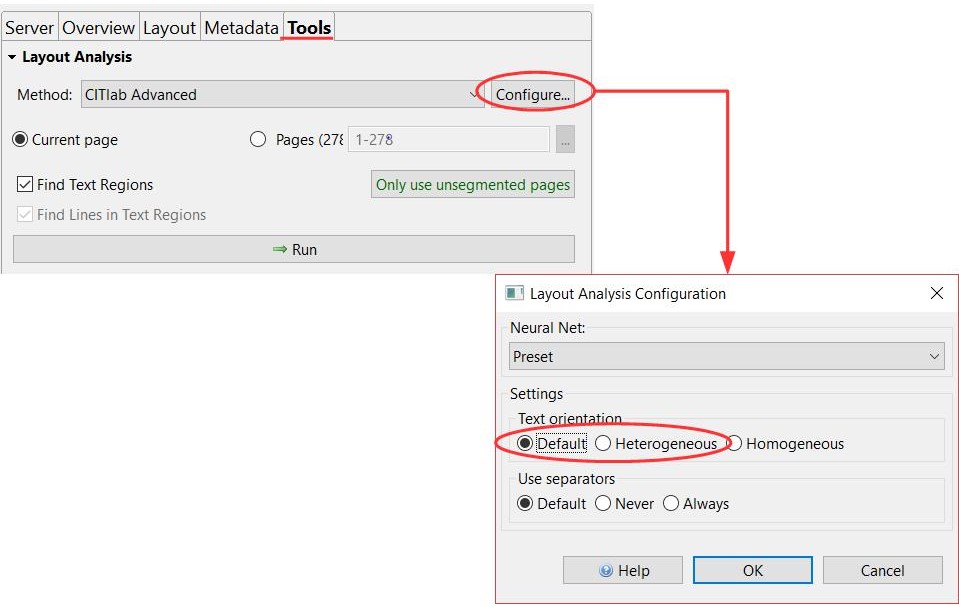
If such complicated layouts are a continuous characteristic of your material, then it is worth designing a P2PaLA training course. This will create your own layout analysis model that is tailored to the specific challenges of your material. By the way, structure tagging is the basic requirement for such training.