
Mixed Layouts
Release 1.7.1
Die CITlab Advanced Layout Analysis kommt mit den meisten „ordentlichen“ Layouts in über 90% der Fälle gut zurecht. Reden wir hier also über die anderen 10%.
Wie man vorgeht, um sich Ärger mit der Reading Order zu ersparen, hatten wir schon besprochen. Aber was passiert, wenn wir es mit wirklich gemischten – verrückten – Layouts zu tun bekommen, z. B. bei Konzepten?

Bei komplizierten Layouts werdet ihr schnell merken, dass die manuell gezogenen TRs sich überlappen. Das ist nicht gut – denn in solchen überlappenden Textregionen funktioniert die automatische Line Detection nicht zuverlässig. Auch dieses Problem lässt sich leicht beheben, denn TRs müssen nicht nur viereckig sein. Sie können als Vielecke (Polygons) gezogen werden und sind dadurch leicht voneinander abzugrenzen.
Es ist sinnvoll, dass ihr diese vielen Textregionen mit strukturellen Tags verseht, um sie besser auseinanderhalten zu können und um sie bei der späteren Weiterverarbeitung evtl. bestimmten Verarbeitungsroutinen zuzuweisen. Das ist ein kleiner Aufwand mit großem Nutzen, denn das Strukturtagging ist nicht aufwendiger, als das Tagging im Kontext.
Tipps & Tools
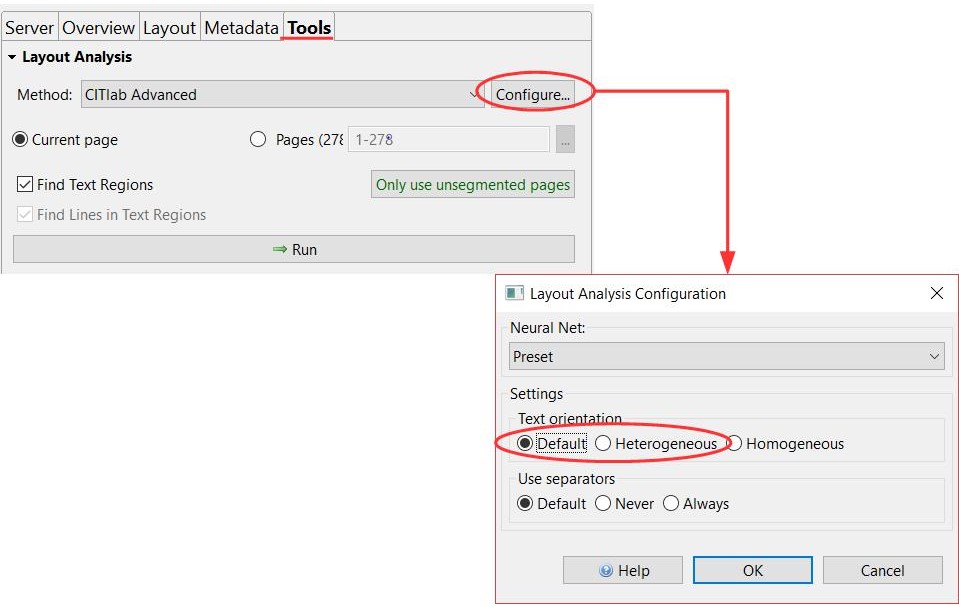
Eine echte Herausforderung kann hier die automatische Line Detection sein. Abschnitte, bei denen Ihr schon (mit ein wenig Erfahrung) vorhersehen könnt, dass das nichts wird, bearbeitet ihr am besten manuell. Bei der automatischen Line Detection sollte CITlab Advanced so konfiguriert werden, dass die Default Einstellung gegen „Heterogeneous“ getauscht wird. Die LA wird jetzt sowohl waagerechte als auch senkrechte oder schiefe und schräge Zeilen berücksichtigen. Das dauert zwar etwas länger, aber dafür ist das Ergebnis auch besser.
Sollten solche komplizierten Layouts ein durchgängiges Merkmal eures Materials sein, dann lohnt es sich ein P2PaLA-Training zu konzipieren. Damit schafft ihr Euch ein eigenes Layout-Analyse-Modell, das für die spezifischen Herausforderungen eures Materials zugeschnitten ist. Für ein solches Training ist das Strukturtagging übrigens die Grundvoraussetzung.

{kind=link}