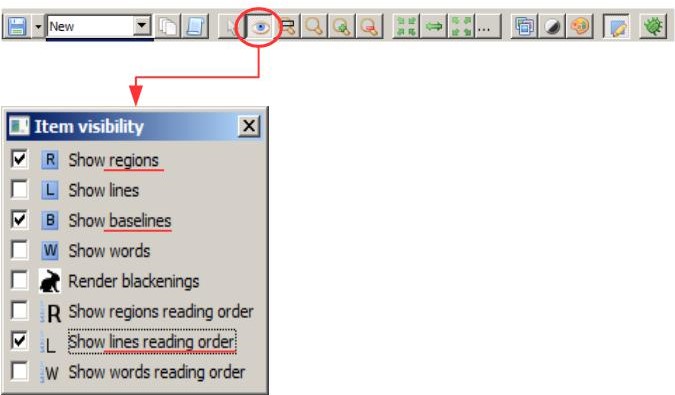
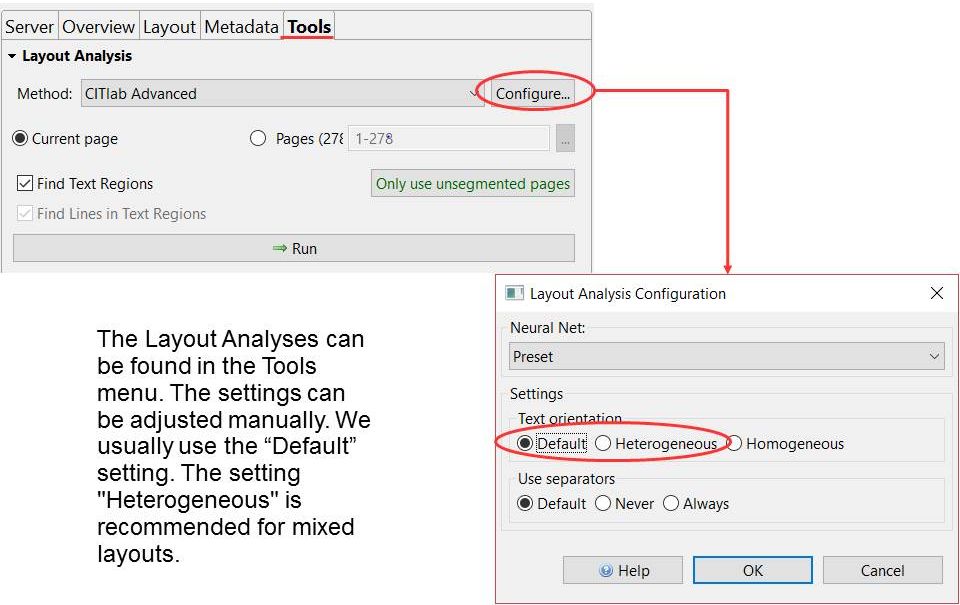
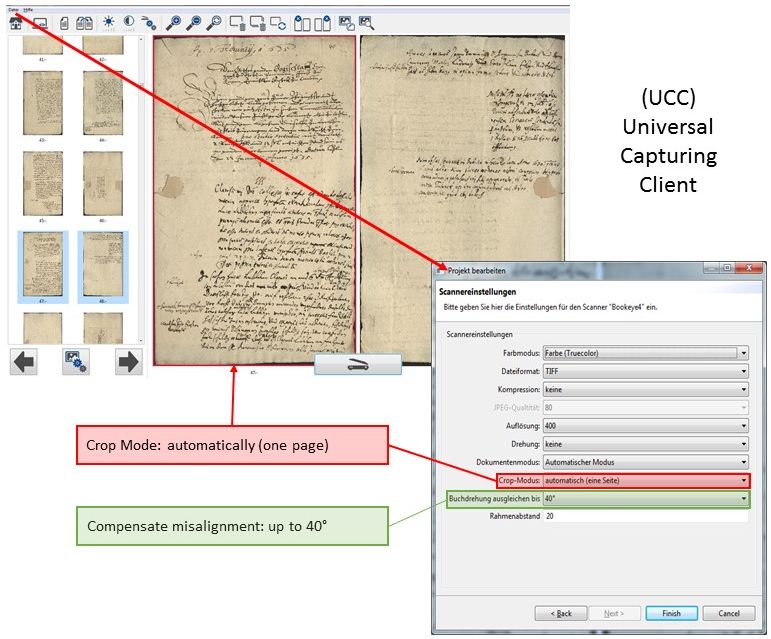
Toolbar – the most important tools and how to use them #2
Release 1.7.1
Correcting layouts

If the basic text regions are drawn, they can be edited. If you select one of the text regions, the other tools on the toolbar will be enabled.
With 1 you can add one or more points to the selected shape (TR or BL!). All shapes consist of dots and straight lines connecting them. You can edit the shape by moving the dots. You can use this tool to make a polygon out of the basic text region, whatever fits best to the text block. Press 2 to remove a dot from the selected shape. This tool is especially useful for correcting or shortening baselines.
This is especially useful if you have split elements. With 3,4 and 5 it is possible to cut a selected shape. This is also possible for both text regions and baselines: 3 cuts horizontally, 4 vertically. With 5 you draw your own line, which does not necessarily have to be horizontal or vertical.
The last important tool (red circle) is the Merge tool. This is especially important if the automatic LA has split baselines in the image. You can use Merge to reassemble all shapes. So baselines with baselines and text regions with text regions. To do this you have to mark the corresponding shapes, which you can do directly in the image or in the layout tab.
Tips & Tools
When splitting, note that the TR and BL can only be cut where they have lines. It is not possible to cut through the dots.
Be aware that when you split a shape Transkribus will automatically change the Reading Order. For example, if two TRs are made from one, a new reading order is started in each TR.