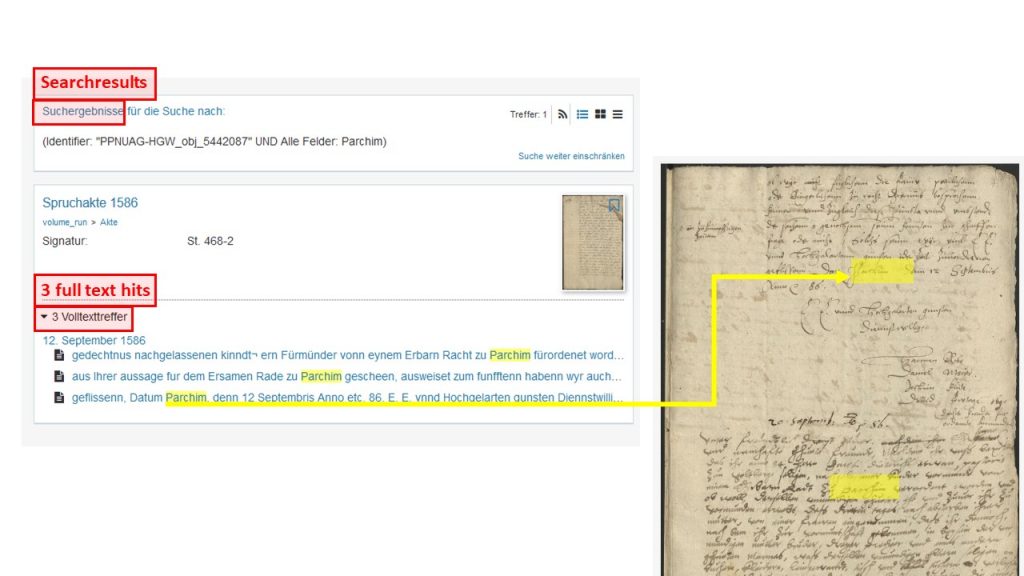
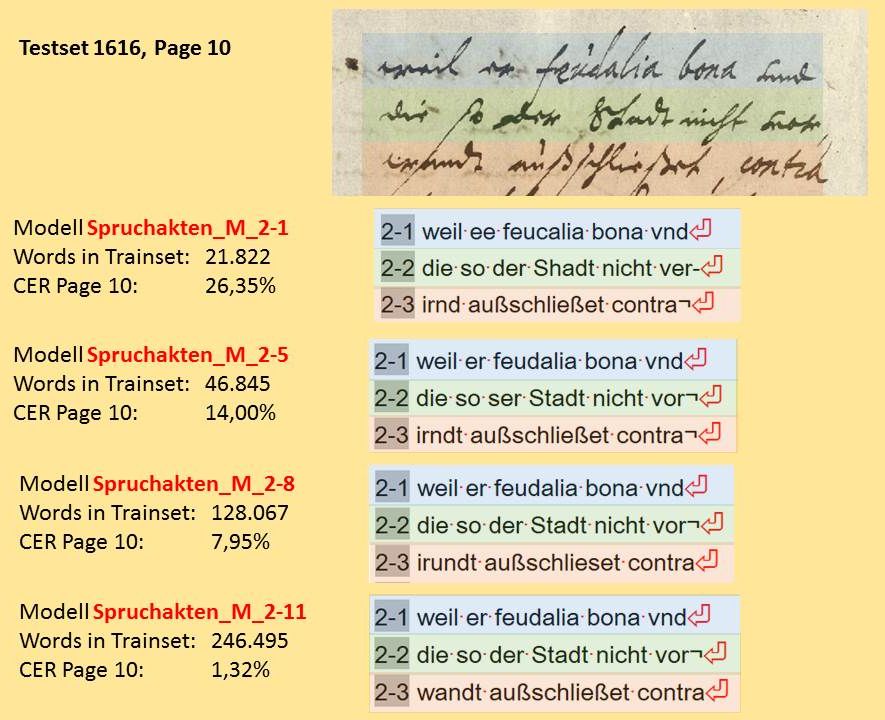
In the transcripts for the Ground Truth, the litteral or diplomatic transcription is used. This means that we do not regulate the characters in the transcription, if possible. The machine must learn from a transcription that is as accurate as possible so that it can later reproduce exactly what is written on the sheet. For example, we consequently adopt the vocal and consonant use of “u” and “v” of the original. You can get used to the “Vrtheill” (sentence) and the “Vniuersitet” (university) quite quickly.
We made only the following exceptions from the literal transcription and regulated characters. The handling of abbreviations is dealt with separately.
We cannot literally transcribe the so-called “long-s” (“ſ”) and the “final-s” because we are dependent on the antiqua sign system. Therefore we transfer both forms as “s”.
We reproduce umlauts as they appear. Diacritical signs are adopted, unless the modern sign system does not allow this; as in the case of the “a” with ‘diacritical e’, which becomes the “ä”. Diphthongs are replaced, for example the “æ″ becomes “ae″.
The Ypsilon is written in many manuscripts as “ÿ″. However, we usually transcribe it as a simple “y″. In clear cases, we differentiate between “y” and the similarly used “ij” in the transcription.
There are also some exceptions to the literal transcription with regard to the punctuation and special characters: In the manuscripts, brackets are represented in very different ways. But here we use the modern brackets (…) uniformly. The hyphenation at the end of the lines is indicated by different characters. We transcribe them exclusively with a “¬”. The common linkage sign in modern use – the hyphen – hardly occurs in the manuscripts. Instead, when two words are linked, we often find the “=”, which we reproduce with a simple hyphen.
We take the comma and point setting as it appears – if it exists at all. If the sentence does not end with a dot, we do not set a dot.
Upper and lower case will be adopted unchanged according to the original. However, it is not always possible to strictly distinguish between upper and lower case letters. This applies to a large extent to the D/d, the V/v and also the Z/z, regardless of the writer. In case of doubt, we compare the letter in question with its usual appearance in the text. In composites, capital letters can occur within a word – they are also transcribed accurately according to the original.