Abbreviaturen
Release 1.9.1
Mittelalterliche und frühneuzeitliche Handschriften weisen in der Regel Abbreviaturen auf, also Abkürzungen in jeglicher Form. Das können sowohl Kontraktionen (Auslassung im Wort) und Suspensionen (Auslassung am Wortende) sein als auch die unterschiedlichsten Sonderzeichen. Sobald wir also alte Handschriften transkribieren wollen, müssen wir uns überlegen, wie wir die Abbreviaturen wiedergeben möchten: Geben wir alles so wieder, wie es im Text erscheint, oder lösen wir alles auf – oder passen wir uns den Kapazitäten der HTR an?
Für den Umgang mit Abbreviaturen in Transkribus gibt es grob gesehen drei verschiedene Möglichkeiten:
– Ihr könnt versuchen Abbreviaturzeichen als Unicode-Zeichen wiederzugeben. Viele der in lateinischen und deutschen Handschriften des 15. und 16. Jahrhunderts gebräuchlichen Abbreviaturzeichen findet ihr im Unicode block „Latin Extended-D“. Solche Unicode-Lösungen für Sonderzeichen in mittelalterlichen lateinischen Texten findet ihr bei der Medieval Unicode Font Initiative. Ob und wann dieser Weg sinnvoll ist, muss man aufgrund der Ziele des eigenen Projektes entscheiden. Auf jeden Fall ist dieser Weg recht aufwendig.
– Wenn ihr nicht mit Unicode-Zeichen arbeiten möchtet, könntet ihr auch den im Abbreviaturzeichen erkannten „Grundbuchstaben“ aus dem regulären Alphabet nutzen. Das wäre dann praktische wie eine litterale Transskription. So ein „Platzhalter“ kann dann mit einem textual tag versehen werden, der das Wort als Abbreviatur auszeichnet („abbrev“). Die Auflösung der so getaggten Abbreviatur kann dem tag als Eigenschaft unter „expansion“ eingegeben werden.
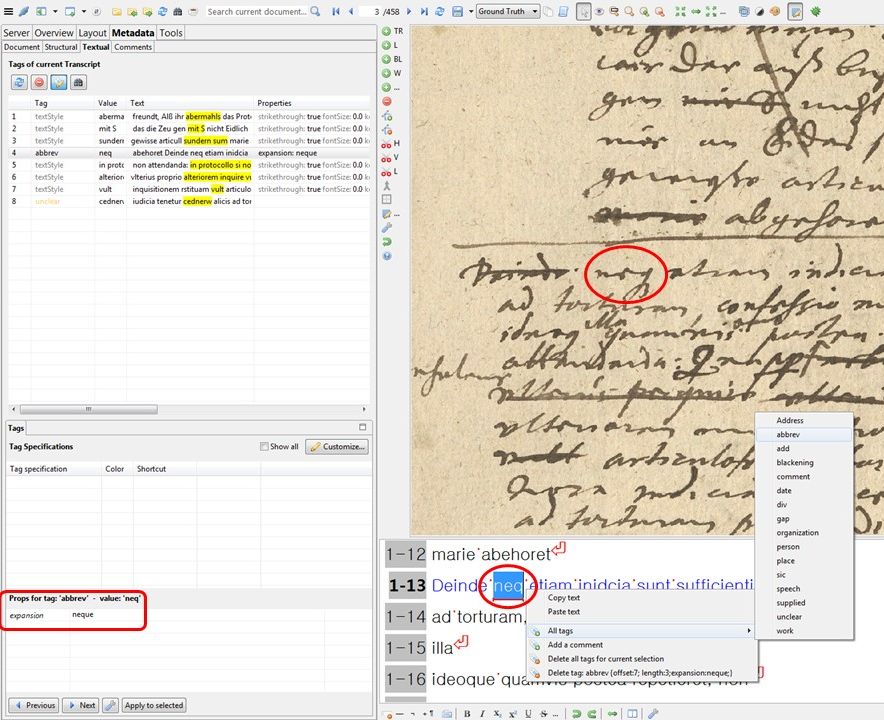
Die Auflösung der Abbreviatur wird also Bestandteil der Metadaten. Dieser Weg bietet die meisten Möglichkeiten für die Nachnutzung des Materials. Aber auch er ist mühsam, denn es muss wirklich jede Abbreviatur getaggt werden.
– Oder ihr löst die Abbreviaturen einfach auf. Wenn man – wie wir – große Mengen Volltext durchsuchbar bereitstellen möchte, macht eine konsequente Auflösung der Abbreviaturen Sinn, weil sie die Suche erleichtert. Wer sucht schon nach „pfessores“ statt nach „professores“?
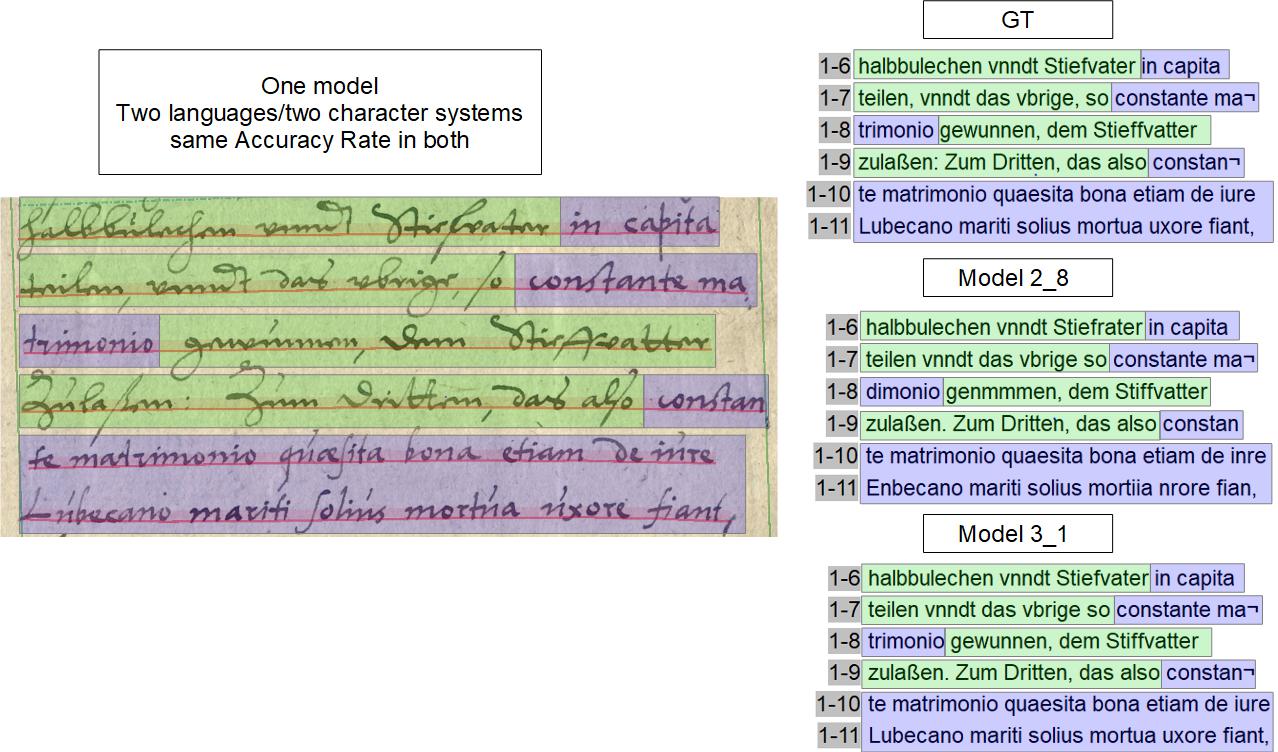
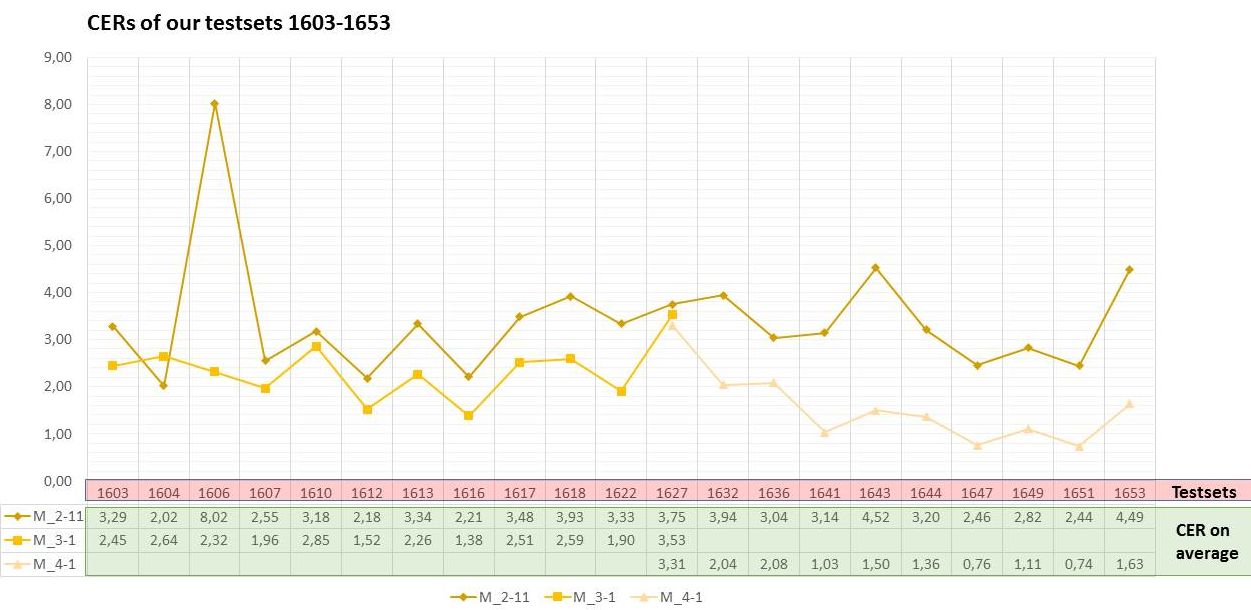
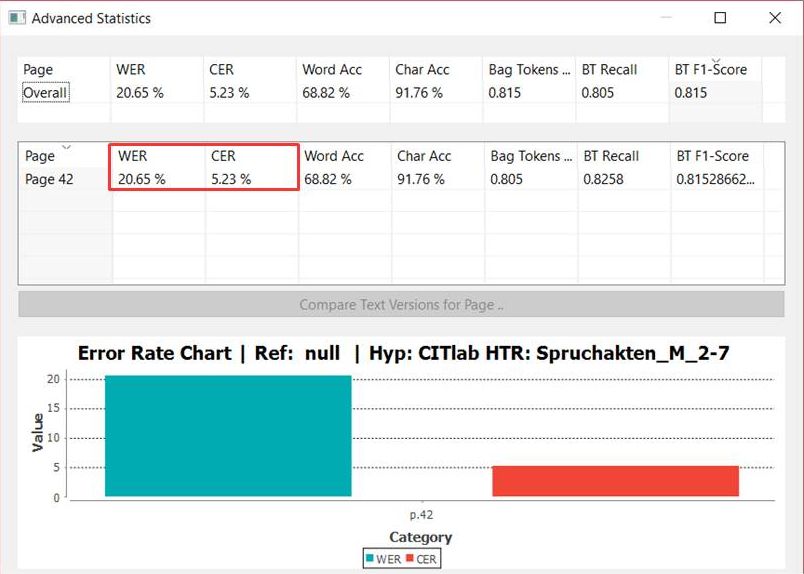
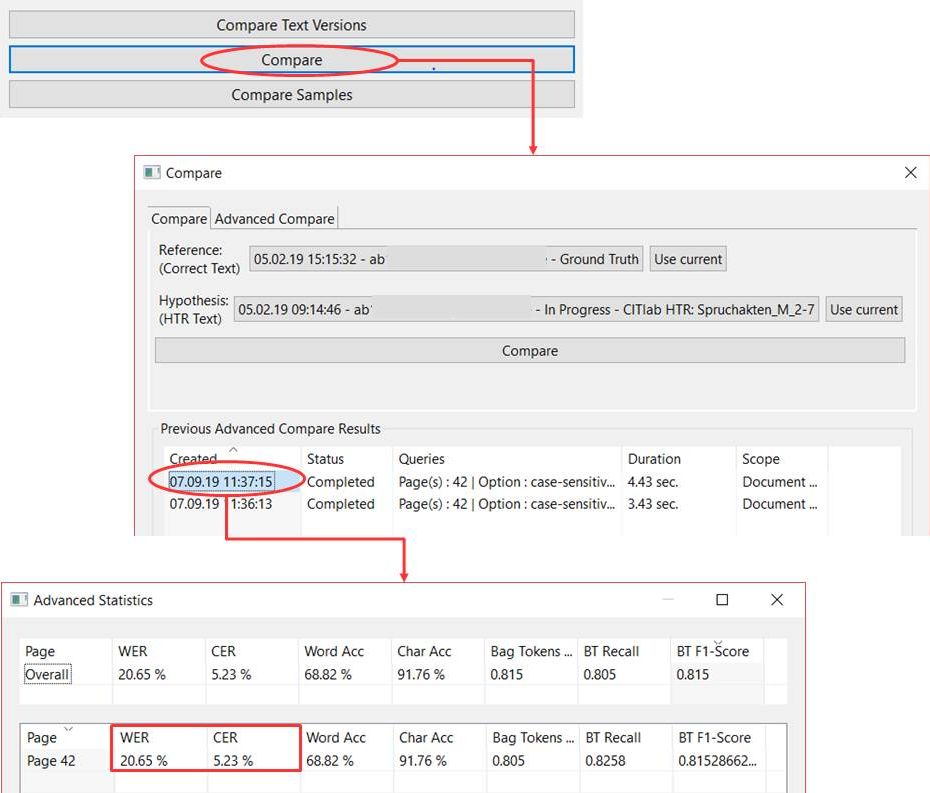
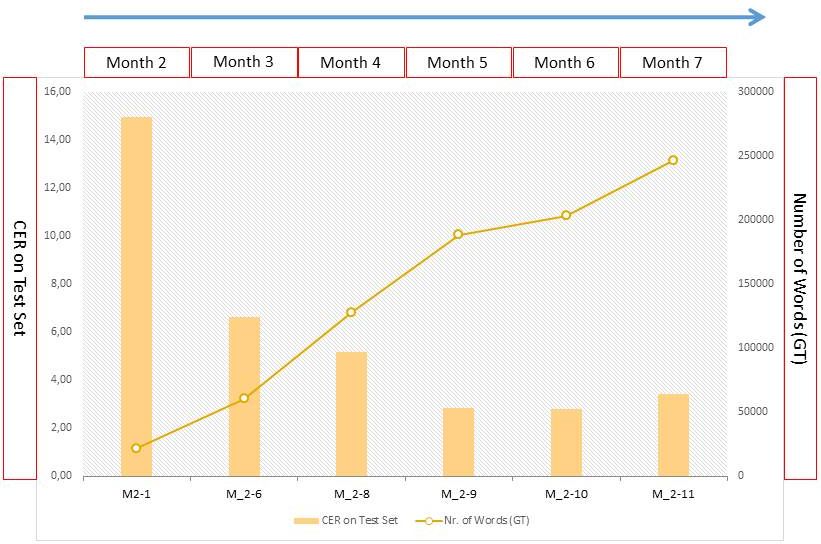
Wir haben die Erfahrung gemacht, dass die HTR mit Abbreviaturen recht gut umgehen kann. Sowohl die klassischen lateinischen und deutschen Abbreviaturen, als auch Währungszeichen oder andere Sonderzeichen. Daher lösen wir die meisten Abbreviaturen schon während der Transskription auf und benutzen sie als Bestandteil des Ground Truth im HTR-Training.
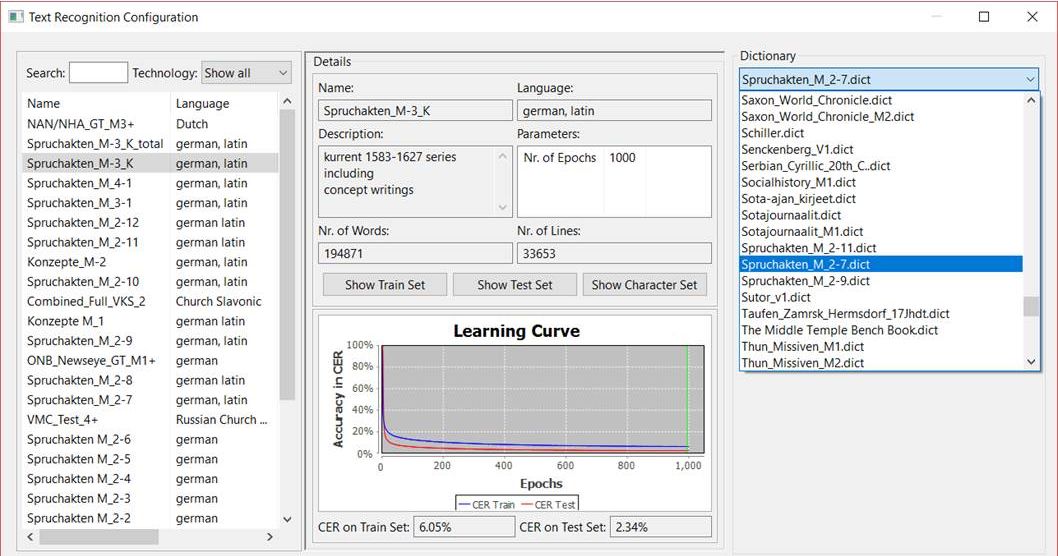
Die von uns trainierten Modell haben einige Abbreviaturen sehr gut erlernt. Die in den Handschriften häufig verwendeten Verkürzungen, wie die auslaufende en-Endung können von einem HTR-Modell aufgelöst werden, wenn es ihm konsequent beigebracht wurde.

Komplexere Abbreviaturen – vor allem die Kontraktionen – bereiten der HTR dagegen Schwierigkeiten. In unserem Projekt haben wir uns daher dafür entschieden, solche Abbreviaturen nur literal wiederzugeben.

Welche Abbreviaturen uns in unserem Material aus dem 16. Bis 18. Jahrhunderts begegnen und wie wir (und später die HTR-Modelle) sie auflösen, seht ihr in unserer Abbreviaturensammlung, die von uns – work in progress! – stets erweitert wird.