Sprachen
Release 1.7.1
HTR benötigt keine Wörterbücher und funktioniert auch unabhängig von der Sprache in der ein Text verfasst ist – solange nur das Zeichensystem verwendet wird, auf das das benutzte Modell trainiert ist.
Für die Trainingsstrategie in unserem Projekt bedeutet das, dass wir zwischen lateinischen und deutschen Texten oder niederdeutschen und hochdeutschen Texten bei der Auswahl des Trainingsmaterials nicht unterscheiden. Wir konnten bisher in der Qualität der HTR-Ergebnisse keine gravierenden Unterschiede zwischen Texten in beiden Sprachen feststellen.
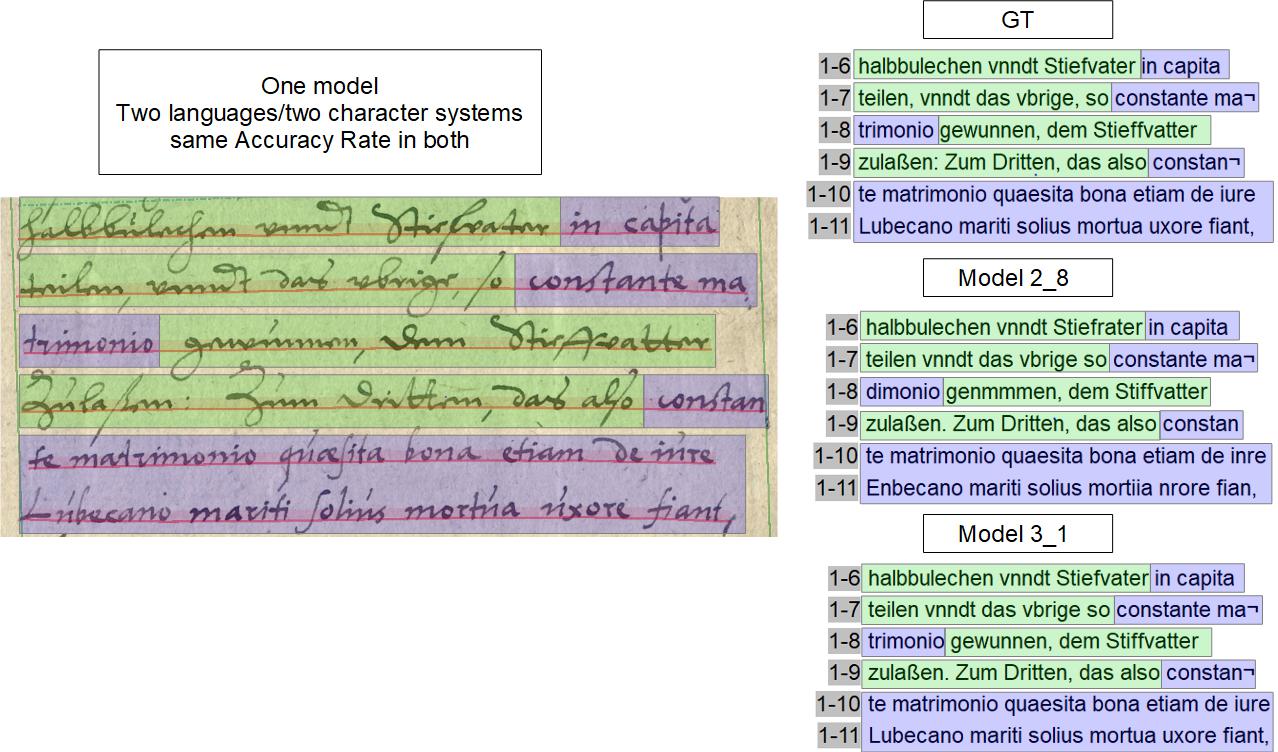
Für historische Handschriften aus dem deutschen Sprachraum ist diese Beobachtung wichtig. Denn üblicherweise ändert sich mit der verwendeten Sprache innerhalb eines Dokuments hier auch die Schrift. Die meisten Schreiber des 16. bis 18. Jahrhunderts wechseln, wenn sie vom Deutschen zum Lateinischen übergehen, mitten im Text von der Kurrentschrift zur lateinischne Schreibschrift (Antiqua). Das ist – in den Augen der Maschine – ein anderes Zeichensystem. Anders als bei der OCR, wo die gemischte Verwendung von Fraktur und Antiqua in neuzeitlichen Drucken große Schwierigkeiten bereitet, hat die HTR – sofern sie darauf traniert ist – mit diesem Wechsel kein Problem.
Ein typisches Beispiel aus unserem Material, das hier mit einem Vergleich der Textversionen von HTR-Ergebnis und GT, versehen ist, kann das verdeutlichen. Die Fehlerquote in dem sich sprachlich unterscheidenden Textabschnitten der Seite ist durchaus vergleichbar. Zum Einsatz kam das Modell Spruchakten M 2-8 sowie M 3-1. Während das erstere ein Gesamtmodell ist, ist das zweite für Schriften von 1583 bis 1627 trainiert.