Mehrere Dokumente gleichzeitig bearbeiten
Version 1.15.1
Bislang waren wir es gewöhnt die Layout Analyse und auch die HTR stets für das Dokument auszulösen, in dem wir uns gerade jeweils befanden. Mittlerweile ist es allerdings möglich, beide Schritte für sämtliche bzw. für ausgesuchte Dokumente der Kollektion, in der wir uns gerade jeweils befinden, auszulösen. Wir beschreiben gleich, wie das geht – aber zunächst einmal warum wir uns darüber sehr freuen:
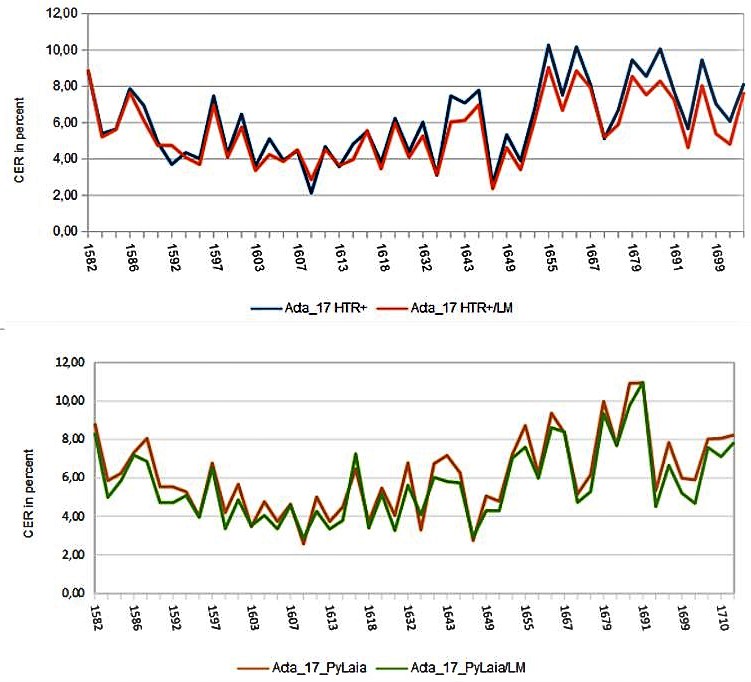
Um die Ergebnisse unserer frisch trainierten Modelle zu überprüfen, haben wir in einer separaten Kollektion Spruchakten-Testsets angelegt. Wie genau und warum, könnt ihr an anderer Stelle nachlesen. Für jedes Dokument, aus dem wir GT ins Training gegeben haben, existiert also in der Testset-Kollektion ein eigenes Testset-Dokument.
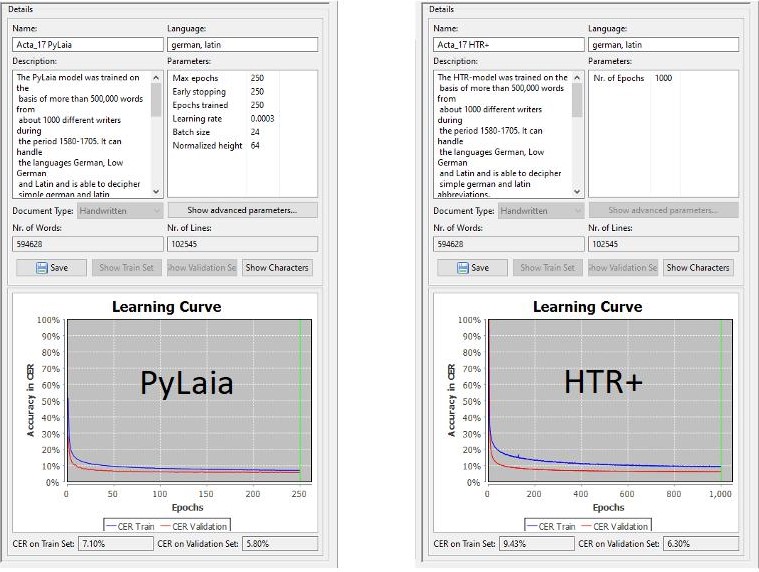
Wenn ein neues HTR-Modell fertig trainiert hat und wir ganz neugierig sind, wie es im Vergleich zu den bisherigen Modellen abschneiden wird, lassen wir es über jedes der Testsets laufen und anschließend die CER berechnen. Nach über zwei Jahren Trainingstätigkeit ist unsere Testset-Kollektion mittlerweile ziemlich voll; knapp 70 Testsets befinden sich schon darin.
Stellt euch vor, wie aufwändig es bisher war, jedes Testset einzeln zu öffnen, um jeweils die neue HTR auszulösen. Da musste man auch bei nur 40 Teststes schon sehr neugierig sein. Und stellt euch nun vor, welche Erleichterung es bringt, dass wir die HTR (und auch die LA) mit einem Klick für alle Dokumente gleichzeitig auslösen können. Das dürfte alle freuen, die sehr viele kleine Dokumente, wie z.B. Karteikarten in einer Kollektion bearbeiten.
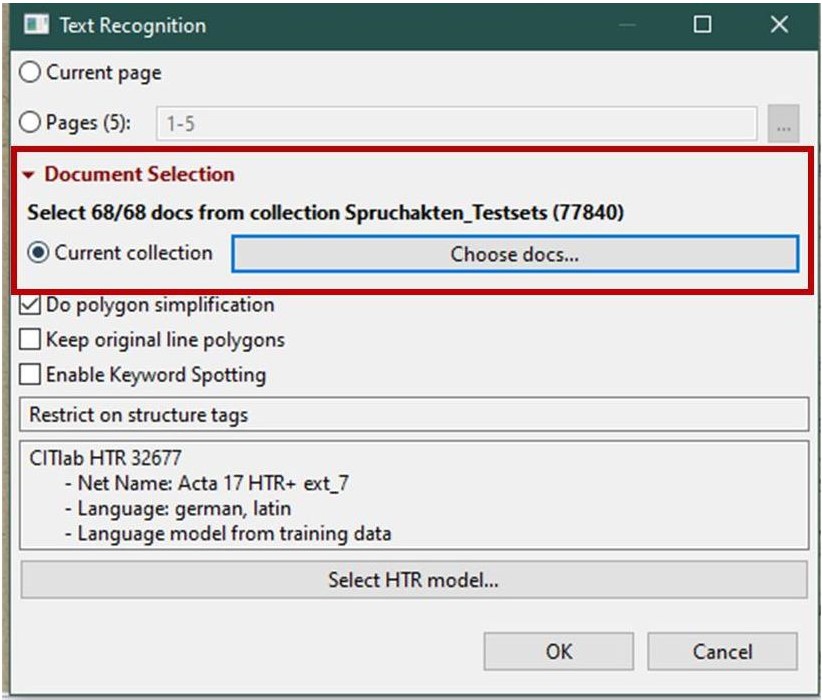
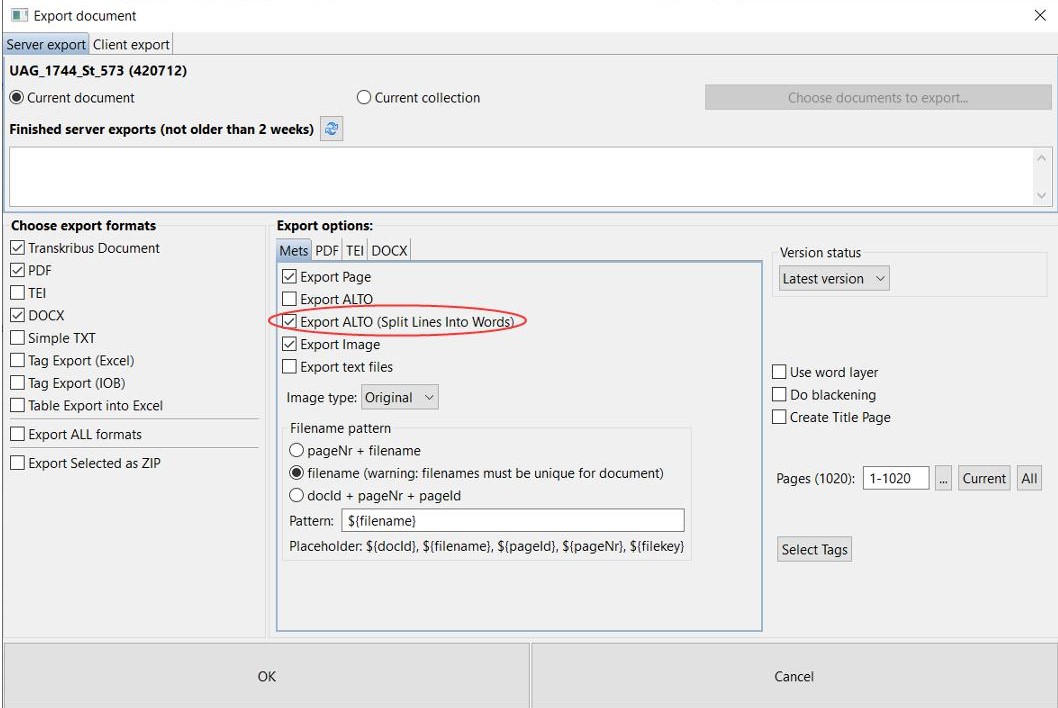
Und wie geht das nun? Unter den Layout-Analyse-Tools sieht man es eigentlich sofort: In Rot steht da unter „Document Selection“, die neue Auswahlmöglichkeit „Current collection“ mit der sich die gesamte aktuelle Kollektion für den folgenden Schritt auswählen lässt.
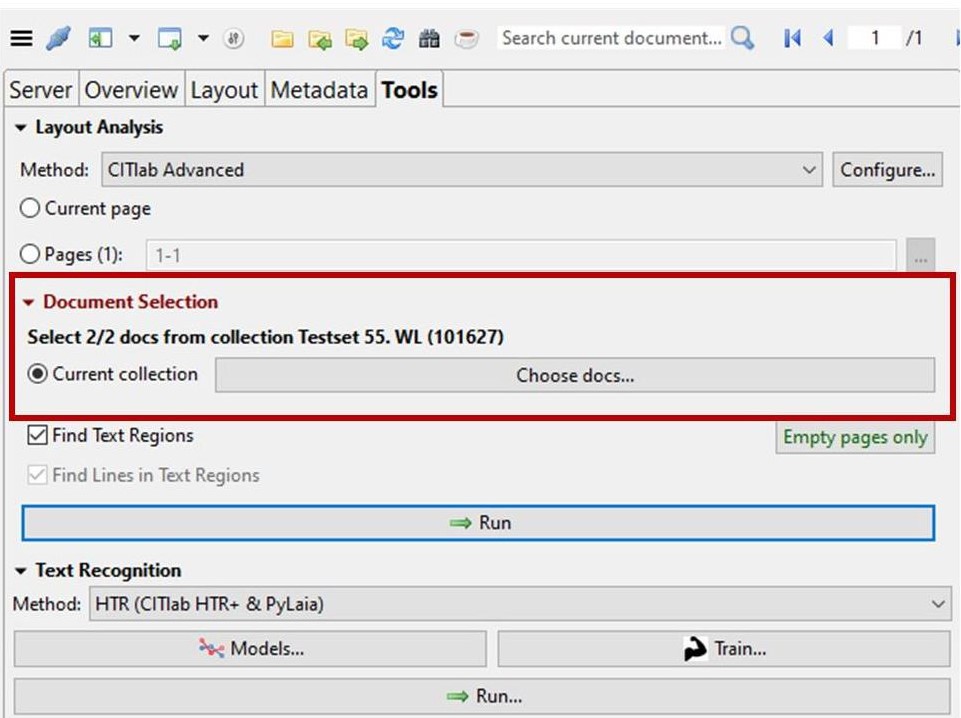
Es reicht hier allerdings nicht aus, einfach nur „Current Selection“ zu markieren und dann die LA auszulösen; ihr müsst vorher über „Choose docs…“ immer erst in die Auswahl hineingehen. Entweder bestätigt ihr dort einfach nur die Vorauswahl (alle docs der collection) oder ihr wählt gezielt einzelne doc aus.
Für die HTR erscheint die gleiche Auswahlmöglichkeit erst im Auswahlfenster zur „Text Recognition“. Auch hier könnt ihr dann für den folgenden Schritt die „Current collection“ auswählen. Und auch hier müsst ihr über „choose docs….“ die Auswahl noch einmal bestätigen.