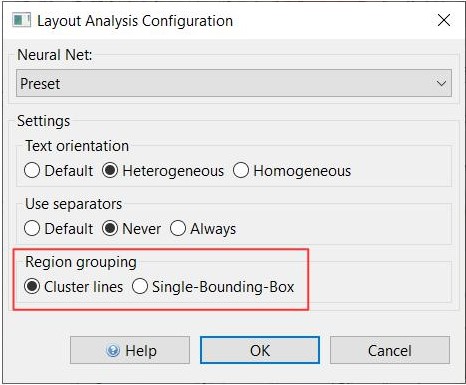
Region grouping
Seit dem Versionsupdate 1.14.0 gibt es eine neue Funktion zur Konfiguration der Layout Analyse. Es geht dabei um die Anordnung der Text Regionen, genannt ‚Region grouping‘. Dabei könnt ihr nun einstellen ob diese um „Bündel“ von Baselines gezogen werden sollen oder ob alle Lines in einer einzigen TR sein sollen.
Bei der zuerst genannten Einstellung kann es schnell passieren, dass am Rand des Images oder auch mittendrin viele kleine TRs auftauchen, auch wenn es eigentlich nur einen Textblock gibt. Dieses Problem kann man in einem weiteren Schritt mit dem Remove small Textregions lösen.
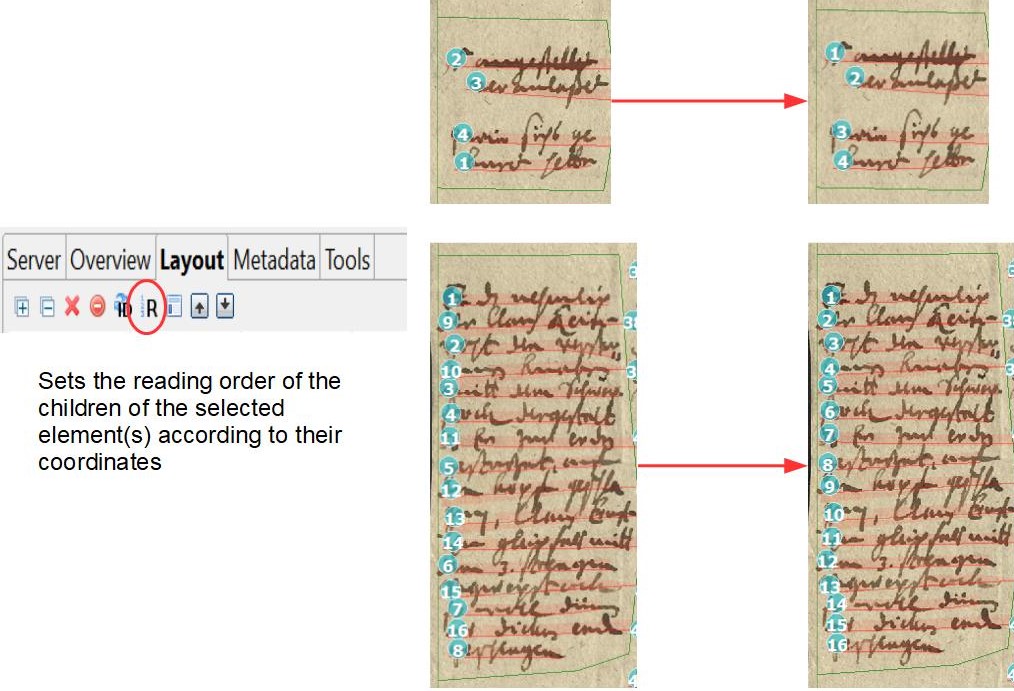
Dagegen sind bei der Einstellung von nur einer Textregion, wirklich alle Baselines in dieser Textregion, auch die, die sonst als Marginalien am Rande stehen und sogar senkrechte BL. Solange die Einstellung ‚Heterogeneous‘ bei ‚Text orientation‘ gewählt ist, erkennt die Layout Analyse auch die senkrechten Linien in derselben TR mit den waagerechten. Es ist zu erkennen, dass die LA normalerweise mehrere TR erkennen würde. Die reading order für die Zeilen wird nämlich weiterhin eingeteilt, als befänden sie sich in eigenen Textregionen. Der Hauptparagraph ist meistens TR 1, deshalb fängt auch die RO dort an. Die anderen Baselines werden hinten angestellt, auch wenn sie seitlich neben dem Haupttext stehen und damit eigentlich mittendrin eingeordnet werden könnten.

Welche Einstellung für euch besser ist, müsst ihr ausprobieren. Bei Seiten, die nur einen Textblock haben, ist die zweite Einstellung natürlich von Vorteil, weil die ganzen kleinen TR nicht auftauchen. Es könnte auch sein, dass man innerhalb eines Dokuments verschiedene Einstellung wählen muss.