Warum Testsets wichtig sind und wie man sie anlegt, #2
Release 1.7.1
Wie geht man nun praktisch vor, um Testsets anzulegen?
Da kann letztlich jeder seinen eigenen Weg finden. In unserem Projekt werden die Seiten für die Testsets bereits während der Erstellung des GT ausgewählt. Sie erhalten einen besonderen edit status (Final) und werden später in separaten Dokumenten zusammengefasst. So ist gesichert, dass sie nicht aus Versehen ins Training geraten. Immer wenn neuer GT für das künftige Training erstellt wird, wird also auch zugleich das Material für das Testset erweitert. Beide Sets wachsen also „organisch“ und proportional.
Für das systematische Training erstellen wir mehrere Documents, die wir als „Testsets“ bezeichnen und die jeweils auf eine Spruchakte (einen Jahrgang) bezogen sind. Zum Beispiel erstellen wir für das Document der Spruchakte 1594 also ein „Testset 1594“. Hierein legen wir repräsentativ ausgewählte Images, die möglichst die Schreibervielfalt abbilden sollen. Im „Mutter-Dokument“ markieren wir die für das Testset ausgewählten Seiten als „Final“, um sicher zu gehen, dass sie dort auch weiterhin nicht bearbeitet werden. Wir haben nicht für jedes Jahr ein eigenes Testet erstellt, sondern sind in Abhängigkeit des Materials in Fünfjahresschritten vorgegangen.

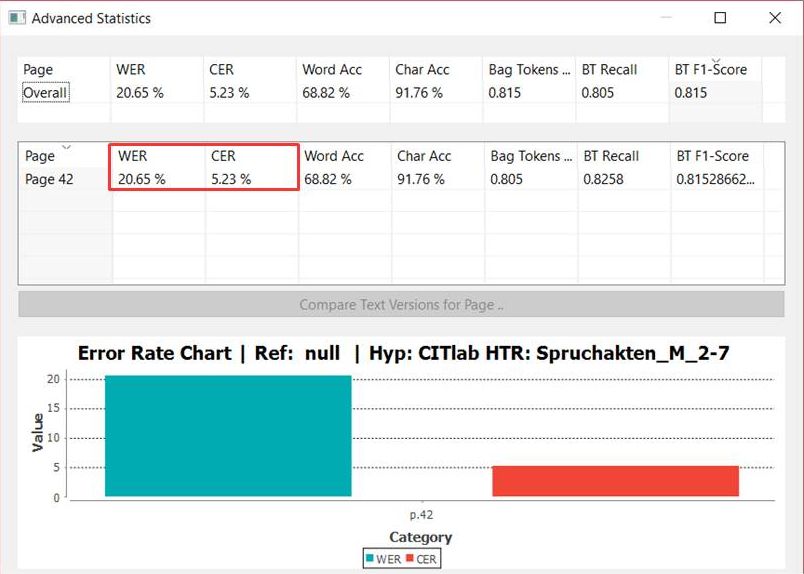
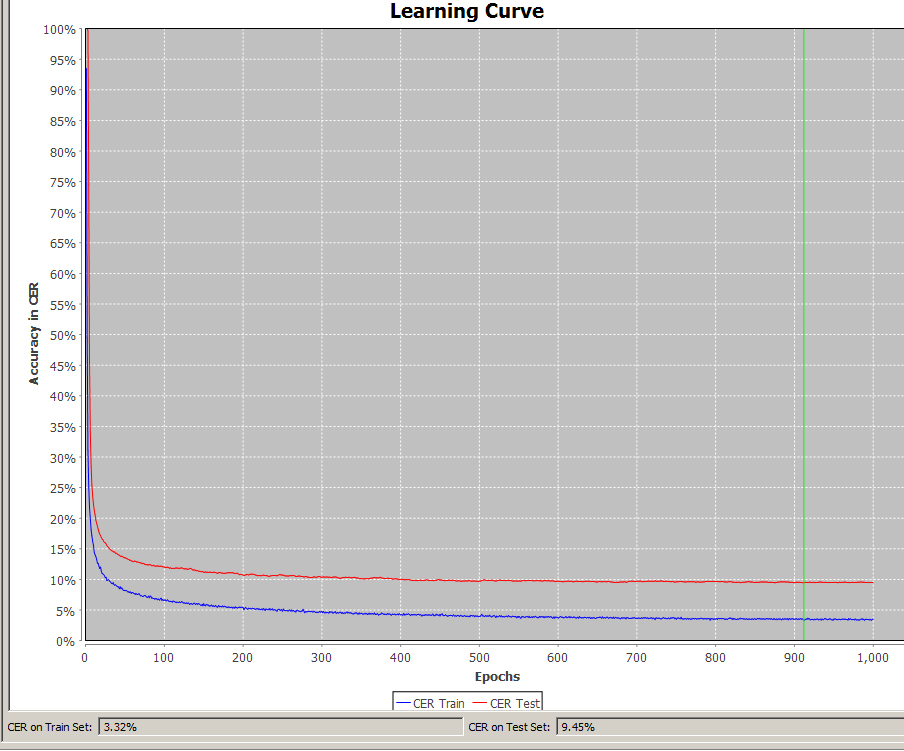
Da ein Modell häufig über viele Durchgänge trainiert wird, hat dieses Vorgehen auch den Vorteil, dass das Testset immer repräsentativ bleibt. Die CERs der unterschiedlichen Versionen eines Modells lassen sich also stets vergleichen und in der Entwicklung beobachten, weil der Test immer auf demselben (oder erweiterten) Set ausgeführt wird. So ist es leichter die Fortschritte eines Modells zu beurteilen und die weitere Trainingsstrategie sinnvoll anzupassen.
Im Übrigen wird in Transkribus nach jedem Training das dafür verwendete Testset in der betroffenen Kollektion selbständig gespeichert. Man kann also immer wieder darauf zurückgreifen.
Es gibt auch die Möglichkeit, ein Testset erst kurz vor der Durchführung des Trainigs auszuwählen und einfach aus dem Trainingsmaterial einzelne Seiten der Dokumente dem Testset zuzuordnen. Das mag für den Einzelfall eine schnelle und pragmatische Lösung sein, ist für den planmäßigen Aufbau mächtiger Modelle aber nicht geeignet.