Our first public model for german current (17th century)
Today we proudly present our HTR-model “Acta 17” as a public model.
The model was trained on the base of more than 500,000 words from about a 1000 different writers during the period of 1580-1705. It can handle the languages German, Lower German and Latin and is able to decipher simple german and latin abbreviations. Besides the usual chancellery lettering, the training material also contained a selection of concept writings and printed material of the period.
The entire training material is based on legal texts or court writings from the Responsa of the Greifswald Law Faculty. Validation sets are based on a chronological selection of the years: 1580 – 1705. GT & validation set was produced by Dirk Alvermann, Elisabeth Heigl, Anna Brandt.
Due to some problems with creating a large series of base-model-trainings for HTR+ Models in the last couple of weeks, we decided to launch an HTR+ Model trained from the scratch.
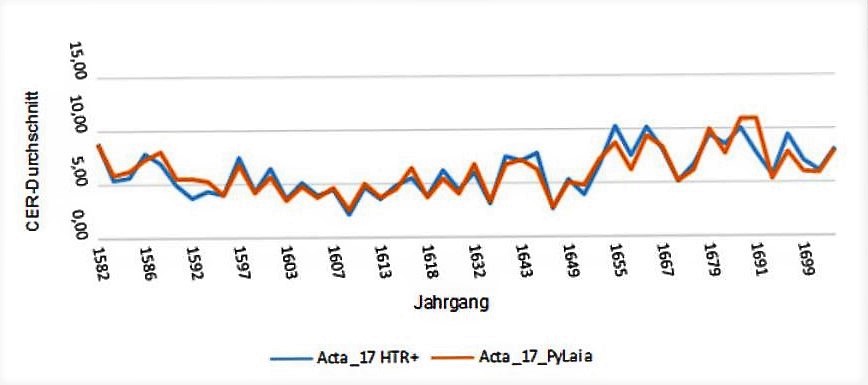
It is accompanied by a PyLaia model, which is based on the same training and validation sets and was also trained without using a base model.
For the validation set we choose pages representing single years of the total set of documents. All together they represent 48 selected years, five pages of each year.
How the models do perform in the several time periods of the validation set, you can check in the comparison below. Both models did run without language model.