How to train PyLaia models
Release 1.12.0
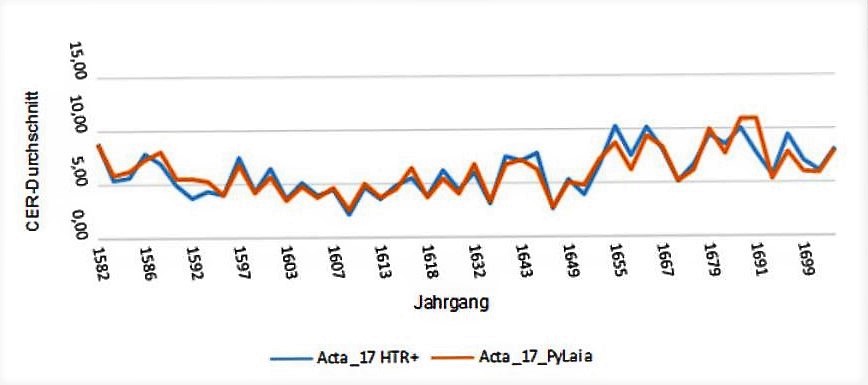
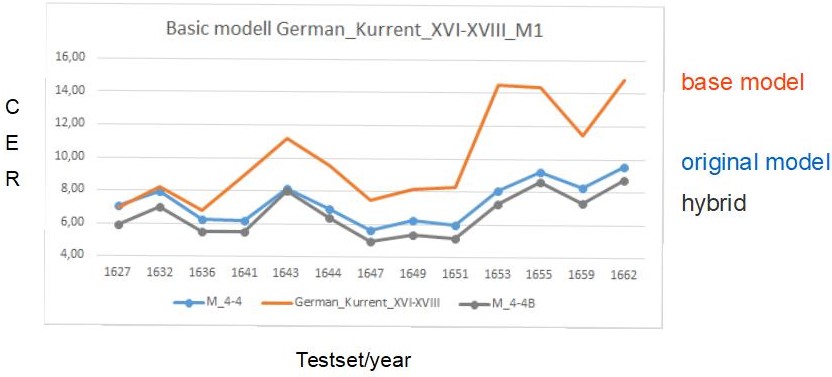
Since version 1.12.0 it is possible to train PyLaia models in Transkribus besides the proven HTR+ models. We have gained some experience with this in the last months and are quite impressed by the performance of the models.
PyLaia models can be trained like HTR or HTR+ models using the usual training tool. But there are some differences.

Like a normal HTR+ model you have to enter the name of the model, a description and the languages the model can be used for. Unlike the training of HTR+ models, the number of iterations (epochs) is limited to 250. This is sufficient in our experience. You can also train PyLaia models with base models, i.e. you can design longer training series that are based on each other. In contrast to the usual training, PyLaia has an “Early Stopping” setting. It determines when the training can be stopped, if a good result is achieved. At the beginning of your training attempts you should always set this value to the same number of iterations as you have chosen for the whole training. So if you train with 250 epochs, the setting for “Early Stopping” should be the same. Otherwise you risk that the training will be stopped too early.
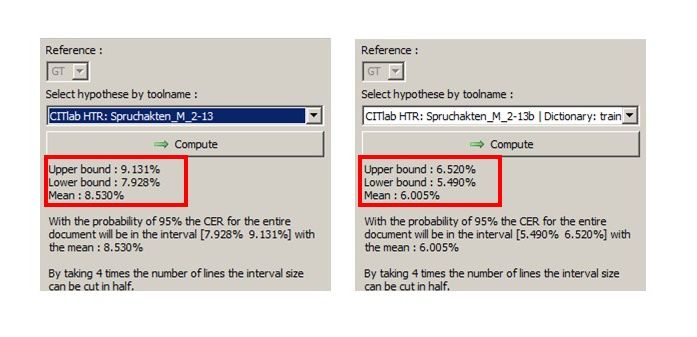
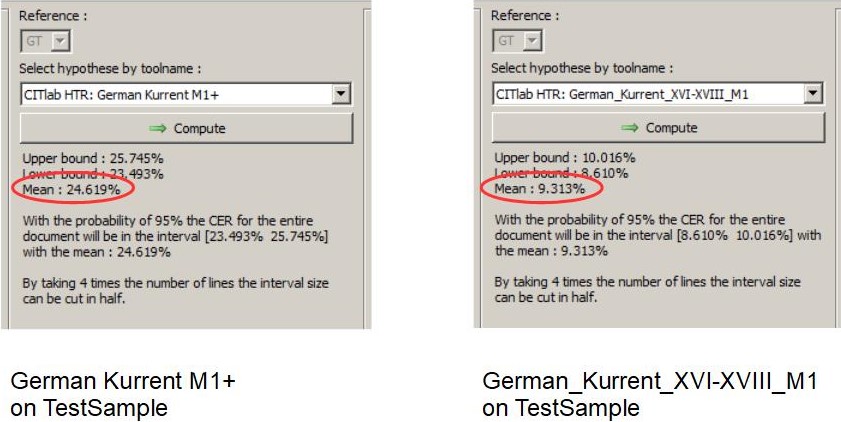
The most important difference is that in PyLaia Training you can choose whether you want to train with the original images or with compressed images. Our recommendation is: train with compressed images. The PyLaia training with original images can take weeks in the worst case (with a correspondingly large amount of GT). With compressed images a PyLaia training is finished within hours or days (if you train with about 500.000 words).
Tips & Tools
For more detailed information, especially for setting specific training parameters, we recommend the tutorial by Annemieke Romein and the READ Coop guidelines.