Advanced Compare
Release 1.10.1
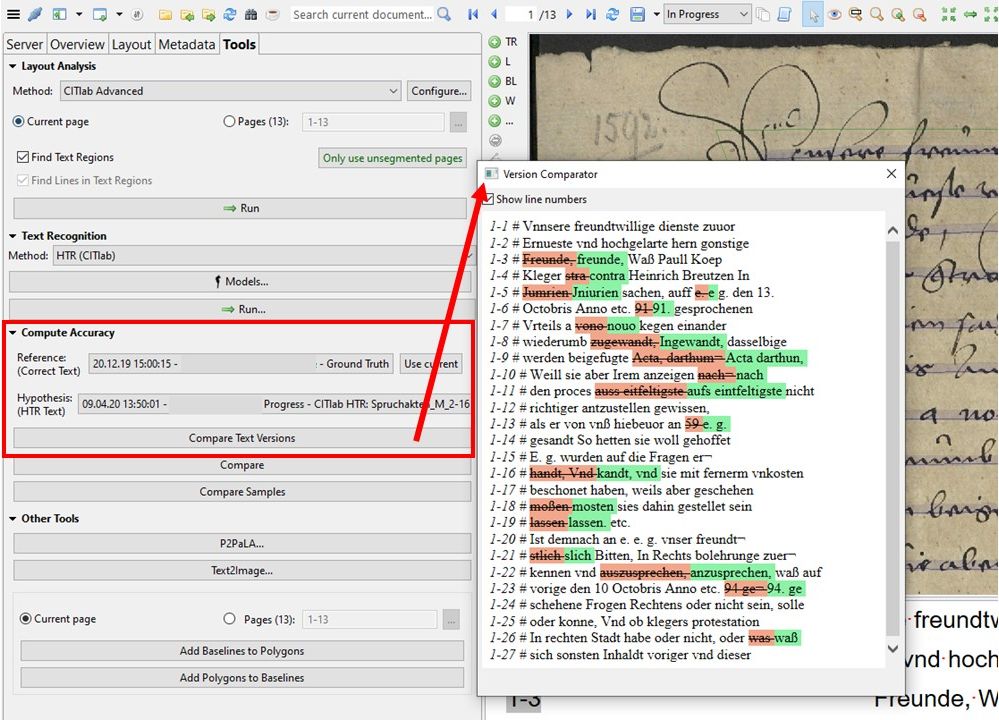
In contrast to the visualization of the errors via the tool “Compare Text Versions” the ordinary “Compare” gives us the same validation results as numerical values.
In addition to the word error rate, we also get the somewhat more conclusive character error rate (CER). Furthermore, in the “Advanced Compare” we can have these results calculated for the whole document or for specific pages in it – always provided that the selected pages have a GT version. Because in Advanced Compare the GT is automatically set as reference.
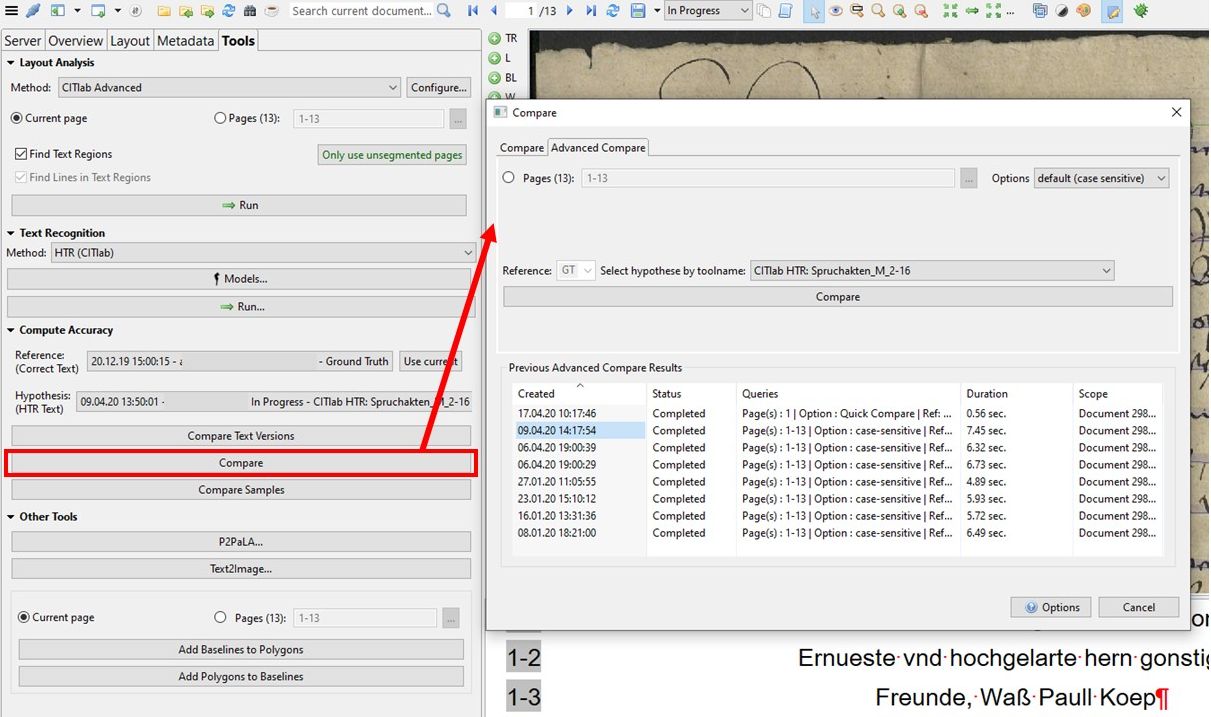
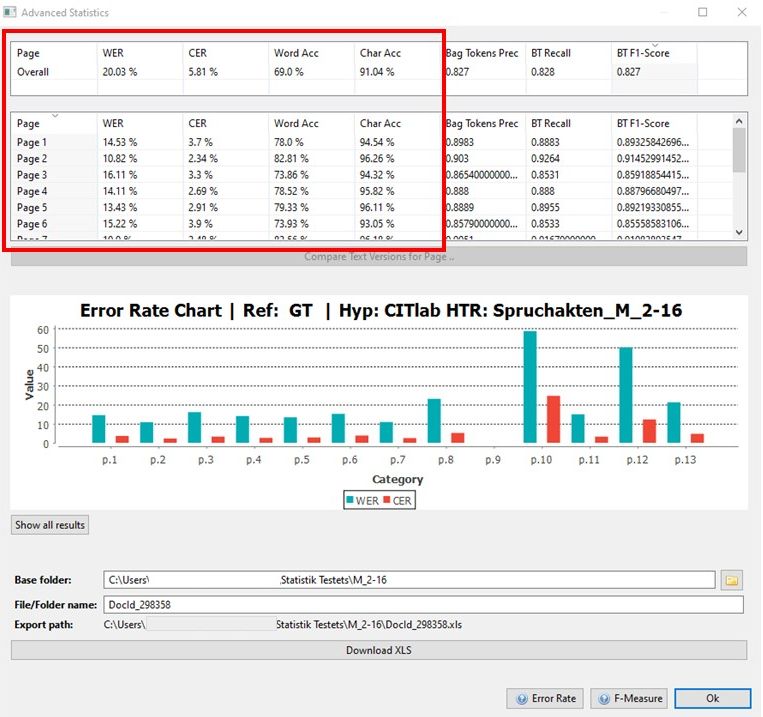
So select the model to be validated and start the calculation. The result gives you not only the average value for the whole document, but also the corresponding values for each individual page. And that makes the Advanced Compare the most important validation tool in systematic analysis when developing models.
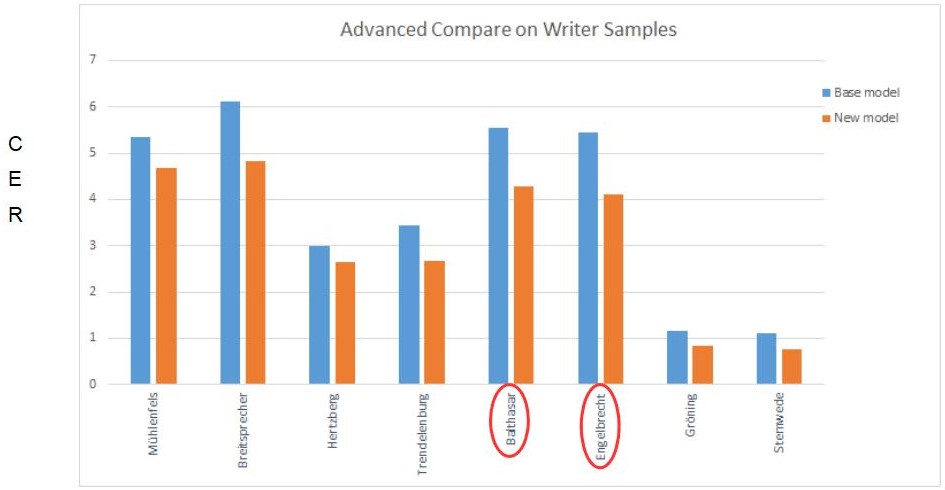
In our rather complex model training for the Spruchakten (over 1000 writer’s hands from more than 150 years) we worked with separate small test sets. On them we could validate our new models over and over again via the Advanced Compare and analyse the results thoroughly. In this way not only average improvements or worsening could be traced in detail. We were also able to identify particular exceptions, such as individual concept fonts or particularly “smeared” ones, which worsened the otherwise good overall result. In addition, we were able to create many graphics from the numerical material, which helped us – and now you – to better understand certain phenomena and developments.
Tips & Tools
You can also download the validation results of the Advanced Compare as an Excel spreadsheet to your computer. To do so, you can select a folder under the result display where you want to save the document. Then click on the button “Download XLS”. Do not just press Enter – otherwise you will have to start all over again.