Advanced Compare
Release 1.10.1
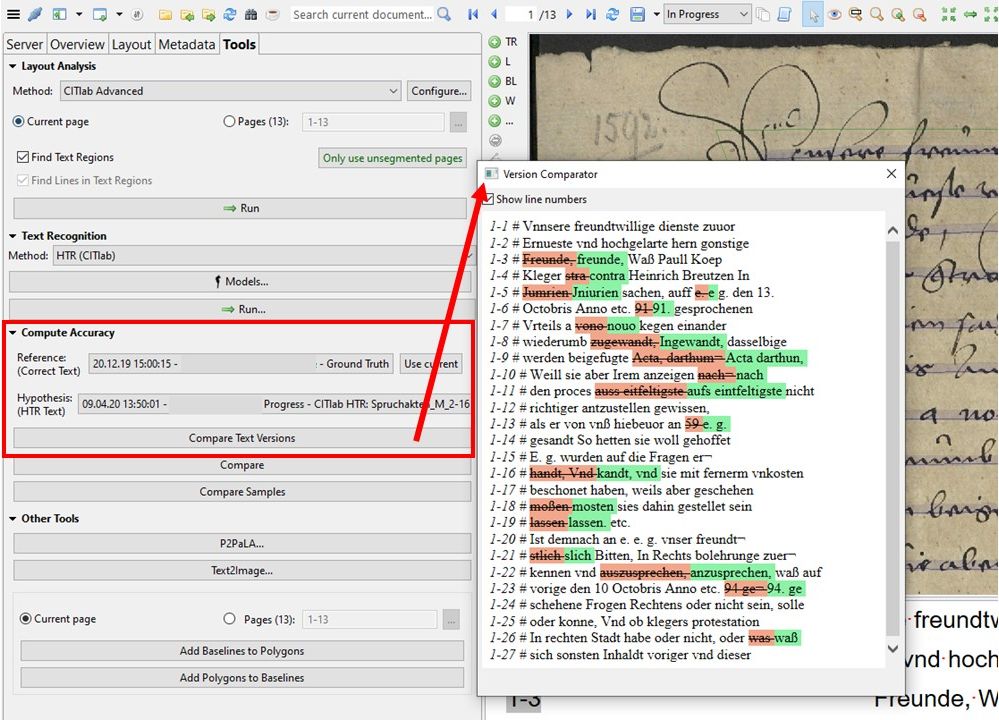
Im Gegensatz zur Visualisierung der Fehler über das Tool „Compare Text Versions“ gibt uns der gewöhnliche „Compare“ die gleichen Validierungsergebnisse als Zahlenwerte.
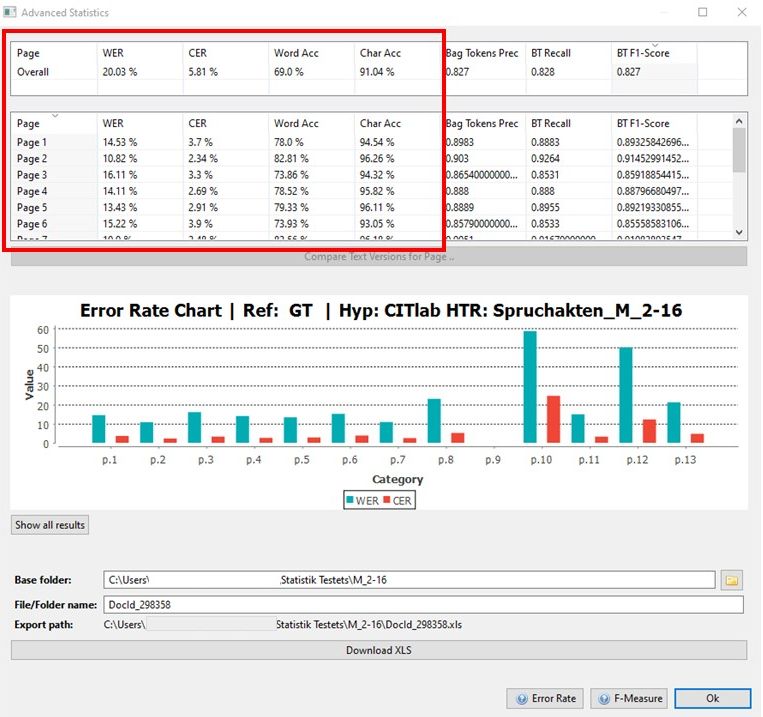
Hier erhalten wir neben der Wortfehlerquote auch die etwas aussagekräftigere Zeichenfehlerquote (CER). Außerdem können wir im „Advanced Compare“ diese Ergebnisse für das gesamte Dokument oder für bestimmte Seiten darin berechnen lassen – immer vorausgesetzt, dass die ausgewählten Seiten über eine GT Version verfügen. Denn beim Advanced Compare ist automatisch der GT als Referenz eingestellt.
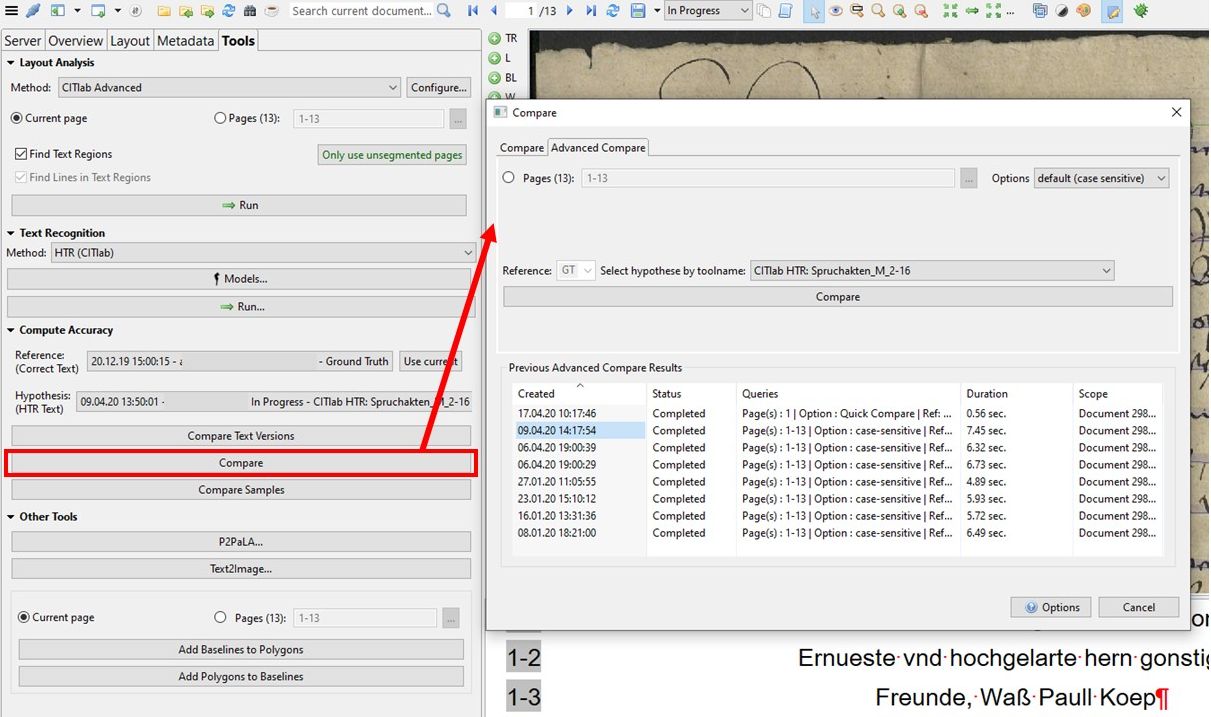
Wähle also das zu validierende Modell als Hypothese aus und starte die Berechnung. Das Ergebnis gibt dir nicht nur den Durchschnittswert für das gesamte Dokument, sondern auch die entsprechenden Werte für jede einzelne Seite an. Und das macht den Advanced Compare zum wichtigsten Validierungstool in der systematischen Analyse bei der Entwicklung von Modellen.
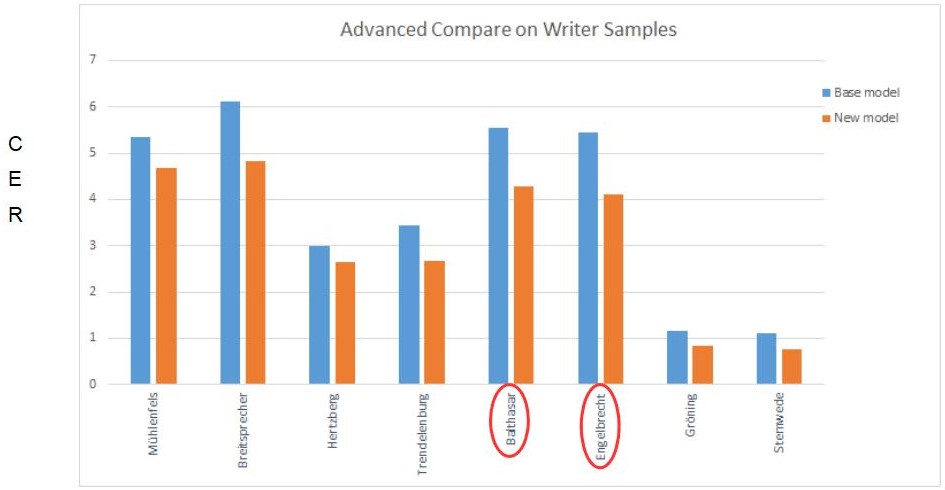
In unserem recht komplexen Modelltraining für die Spruchakten (über 1000 Schreiberhänden aus über 150 Jahren) haben wir mit gesonderten kleinen Testsets gearbeitet an denen wir unsere neuen Modelle über das Advanced Compare immer wieder testen und die Ergebnisse genau analysieren konnten. So ließen sich nicht nur durchschnittliche Verbesserungen oder auch Verschlechterungen detailliert nachvollziehen. Wir konnten auch besondere Ausreißer, wie z.B. einzelne Konzeptschriften oder besonders „verschmierte“ ausmachen, die das sonst gute Gesamtergebnis verschlechterten. Darüber hinaus konnten wir aus diesem Zahlenmaterial viele Grafiken erstellen, die uns und euch bestimmte Phänomene und Entwicklungen veranschaulichen und dadurch verständlicher machen.
Tipps & Tools
Die Validierungsergebnisse des Advanced Compare kannst du dir auch als Excelltabelle auf deinen Rechner herunterladen. Dazu kannst du unter der Ergebnisdarstellung einen Ordner auswählen, in den das Dokument gespeichert werden soll. Klicke dann auf den Button „Download XLS“. Drücke nicht einfach Enter – sonst musst du wieder von vorne anfangen.