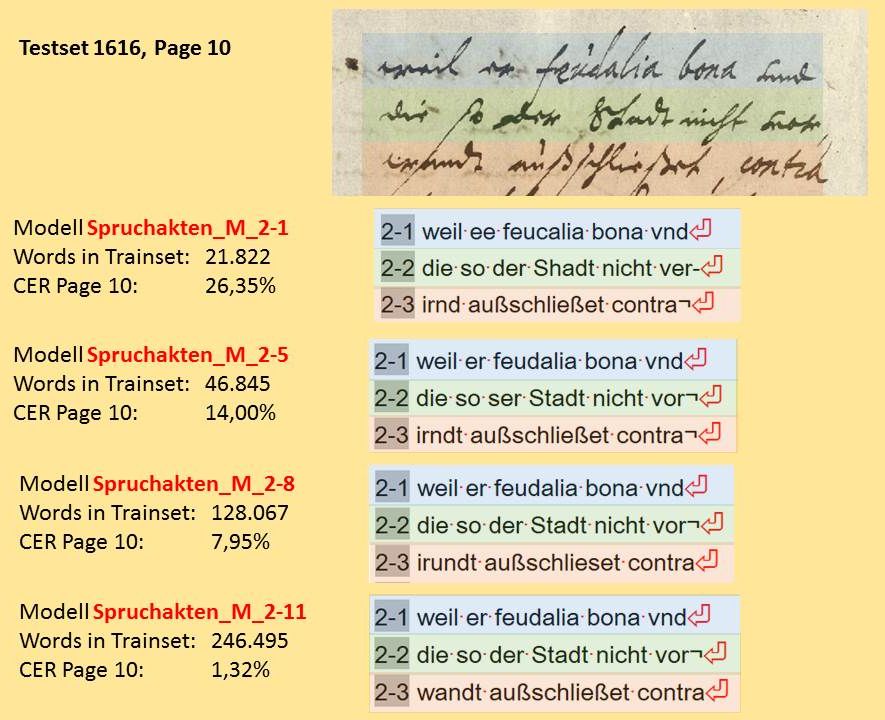
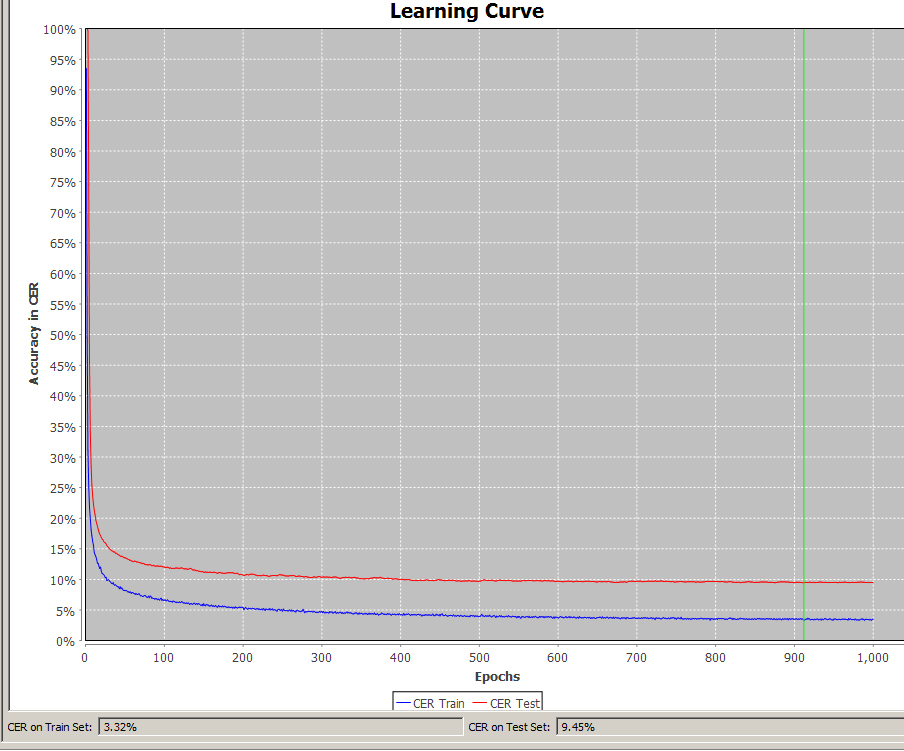
Unsere HTR-Ergebnisse in der Digitalen Bibliothek MV
Wir präsentieren unsere Ergebnisse in der Digitalen Bibliothek Mecklenburg-Vorpommern. Hier findest du die Digitalisate mit der dazugehörigen Transkription.
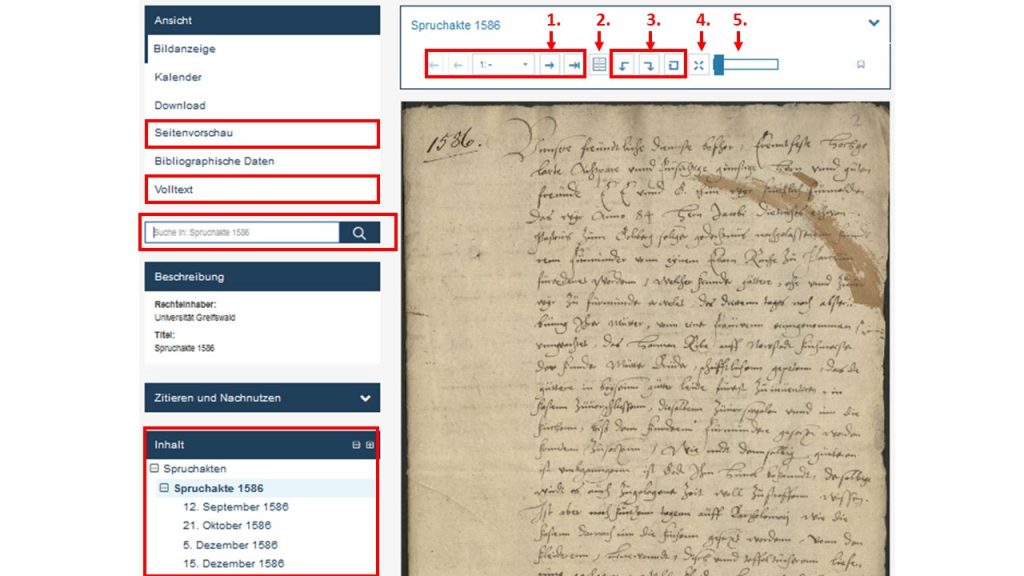
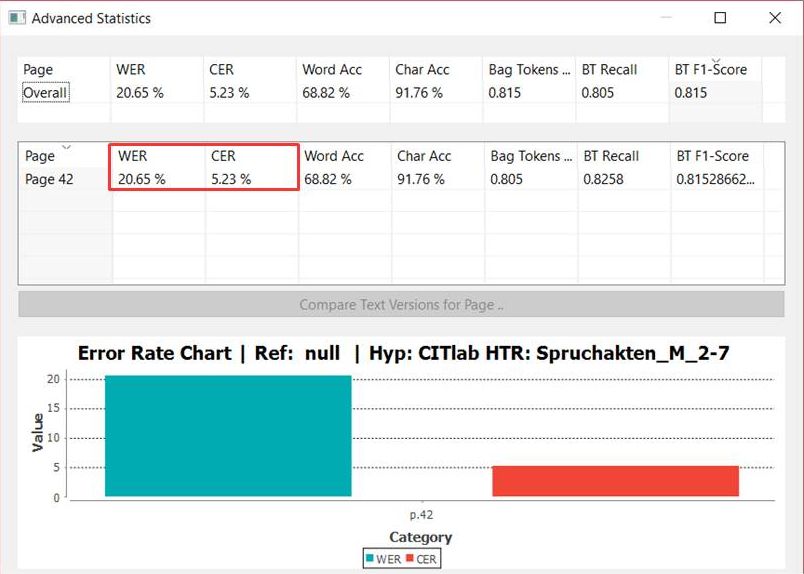
Wenn du eine Akte ausgewählt hast, wie hier zum Beispiel die Spruchakte von 1586, siehst du mittig die erste Seite. In der Box darüber kannst du zur nächsten, zur vorherigen oder auch zu irgendeiner Seite deiner Wahl wechseln (1.) , den Doppelseitenmodus wählen (2.), das Bild rotieren (3.), in den Vollbildmodus wechseln (4.) und es vergrößern oder verkleinern (5.).
Auf der linken Seite kannst du verschiedene Ansichten auswählen. Du kannst dir beispielsweise statt nur der einen Seite alle Bilder auf einmal anzeigen lassen (Seitenvorschau) oder du kannst gleich die Transkription des Textes in der Volltext-Anzeige lesen.
Wenn du in der Struktur der Akte navigieren möchtest, musst du zuerst in der untersten linken Inhalt-Box über das kleine Plus-Symbol dir den Strukturbaum der Akte anzeigen lassen. Dort kannst du dann ein Datum auswählen.
Suchst du einen bestimmten Namen, einen Ort oder einen anderen Begriff? Dann trage diesen einfach in das linke Suchfeld („Suche in: Spruchakte 1568“) ein. Wenn der Begriff in der Akte vorkommt, werden die „Volltexttreffer“, d. h. sämtliche Stellen an denen dein Suchbegriff vorkommt, angegeben.
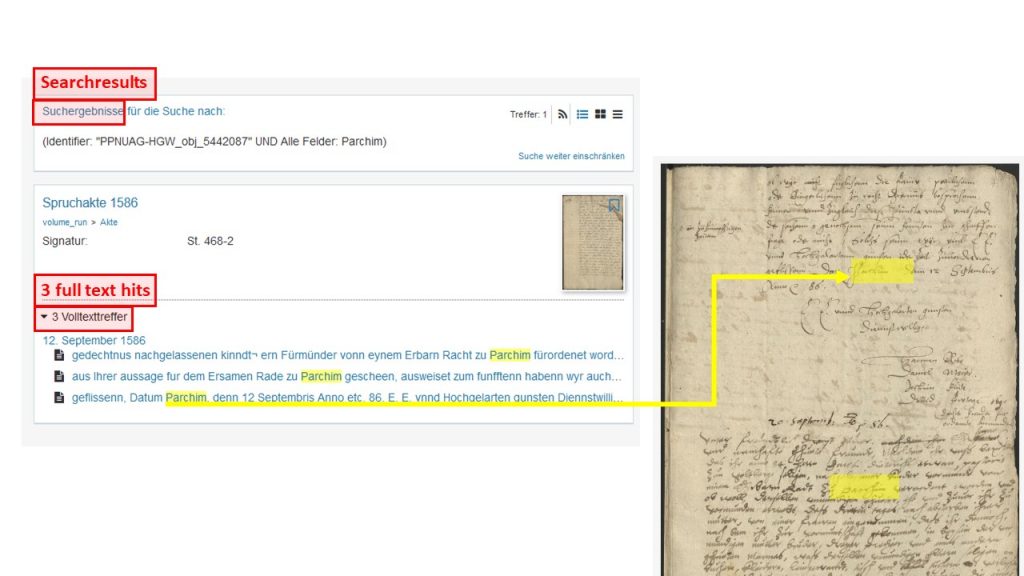
Wenn du hier einen der Treffer auswählst, erscheint dein Suchbegriff auf dem Digitalisat gelb markiert. Das Highlighten der Suchergebniss funktioniert vorläufig nur auf dem Digitalisat, noch nicht im Volltext.
Tipps & Tools
Lass dir die Volltexttreffer in einem neuen Tab (über die rechte Maustaste) anzeigen. Das vor- und zurücknavigieren ist in der Digitalen Bibliothek leider noch etwas umständlich. So kannst du sicher gehen, dass du immer wieder auf deine vorherige Auswahl zurückkommst.