Einzelne Zeilen vom Training ausschließen
Manch einer wird das aus der Praxis kennen: ihr seid gerade dabei eine besonders schwierige Seite in Transkribus abzuschreiben und könnt beim besten Willen nicht alles entziffern. Was macht man da? Wenn die Seite so auf den Edit Status „Ground Truth“ gesetzt wird, dann geht die Transkription mit samt den offensichtlichen Fehlern (oder dem was ihr nicht lesen konntet) ins Training. Das ist nicht gewollt. Aber einfach „wegwerfen“ wollt ihr die Seite auch nicht.
Wir haben schon in einem anderen Beitrag über die Verwendung von Tags berichtet. Wir benutzen im Projekt in solchen Fällen von Beginn an das „unclear“-tag. Andere benutzen für solche Leseprobleme auch gerne das Tag „gap“.
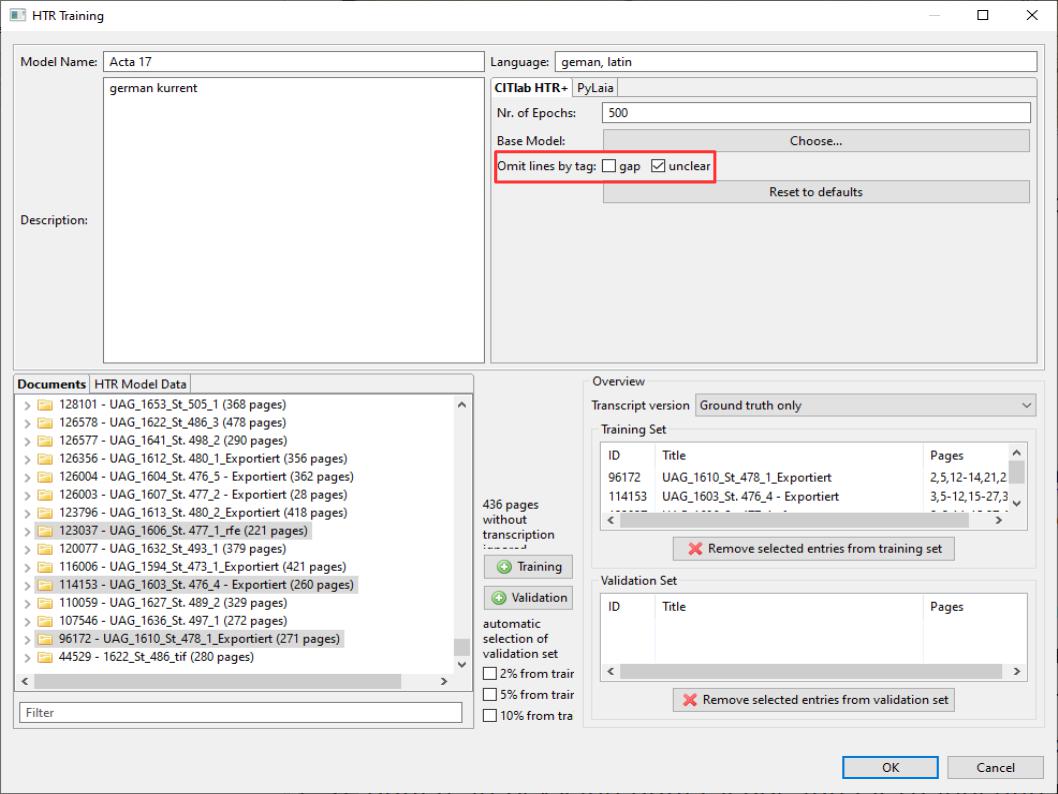
Das erweist sich jetzt als großer Vorteil. Denn seit einigen Monaten gibt es im Trainings-Tool von Transkribus die Funktion „omit lines bei tag“.
Das Tool sorgt dafür, dass auf allen Seiten, die in das Trainings- oder Validaton-Set genommen werden, autormatisch die Zeilen, die ein Tag „unclear“ oder „gap“ aufweisen, nicht mit in das Training einbezogen werden. Das heißt, man kann jetzt selbst Seiten, die nicht perfekt transkribiert sind, bei denen aber die Stellen, die man nicht entziffern konnte, entsprechend durch Tags markiert sind, bedenkenlos mittrainieren.