Viel hilft viel – wieviel GT muss ich investieren?
Release 1.7.1
Wie schon gesagt: Ground Truth ist das A und O bei der Erstellung von HTR-Modellen.
GT ist die korrekte und maschinenlesbare Abschrift der Handschrift mit deren Hilfe die Maschine das „Lesen“ lernt. Je mehr die Maschine „üben“ kann, desto besser wird sie. Je mehr Ground Truth wir also haben desto geringer werden die Fehlerquoten. Viel hilft also auch viel.
Natürlich hängt die Menge immer vom konkreten Anwendungsfall ab. Wenn wir mit wenigen, gut lesbaren Schriften arbeiten, genügt in der Regel wenig GT, um ein solide arbeitendes Modell zu trainieren. Sind die Schriften aber sehr unterschiedlich, weil wir es mit einer großen Anzahl verschiedener Schreiber zu tun haben, wird der Aufwand höher. Das heißt, in solchen Fällen müssen wir mehr GT bereitstellen um gute HTR-Modelle zu erzeugen.
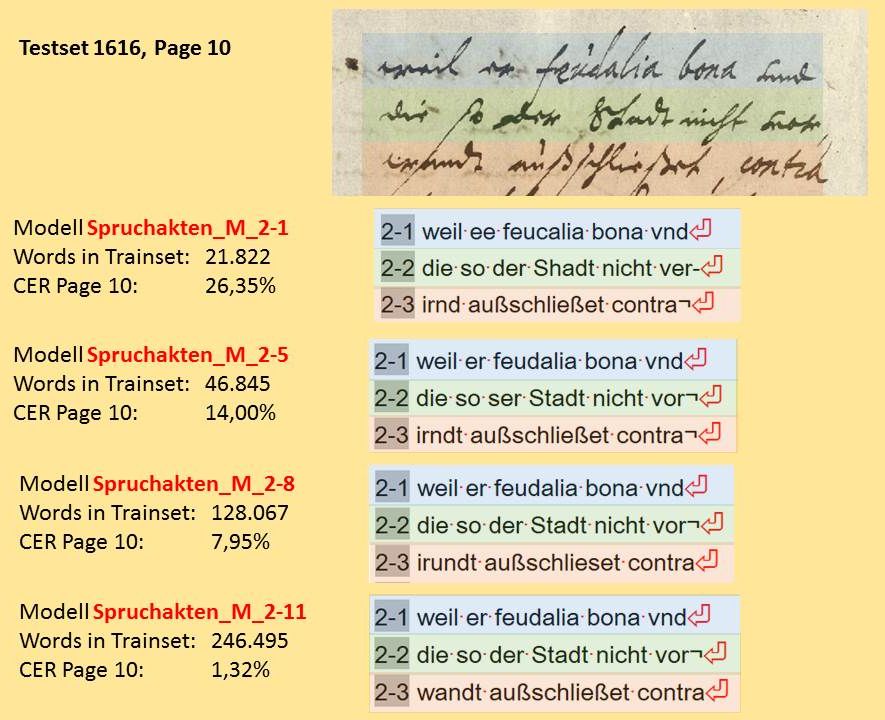
In den Spruchakten finden wir besonders viele unterschiedliche Schreiber. Darum wurde hier auch sehr viel GT erzeugt um die Modelle zu trainieren. An unseren Spruchaktenmodellen (Spruchakten_M_2-1 bis 2-11) lässt sich deutlich ablesen, wie schnell die Fehlerquote tatsächlich zurückgeht, wenn möglichst viel GT investiert wird. Ganz grob lässt sich sagen, dass bei Verdoppelung der Menge des GT im Training (words in trainset) die Fehlerquote (CER Page) des Modells jeweils halbiert wird.
In unseren Beispielen konnten wir beobachten, dass wir die Modelle mit mindestens 50.000 Wörtern GT trainieren müssen, um gute Ergebnisse zu erzielen. Mit 100.000 Wörtern im Training kann man bereits ausgezeichnete HTR-Modelle erhalten.