Structural tagging – what else you might do with it (Layout and beyond)
In one of the last posts you read how we use structural tagging. Here you can find how the whole toolbox of structural tagging works in general. In our project it was mainly used to create an adapted LA model for the mixed layouts. But there is even more potential in it.
Who doesn’t know the problem?
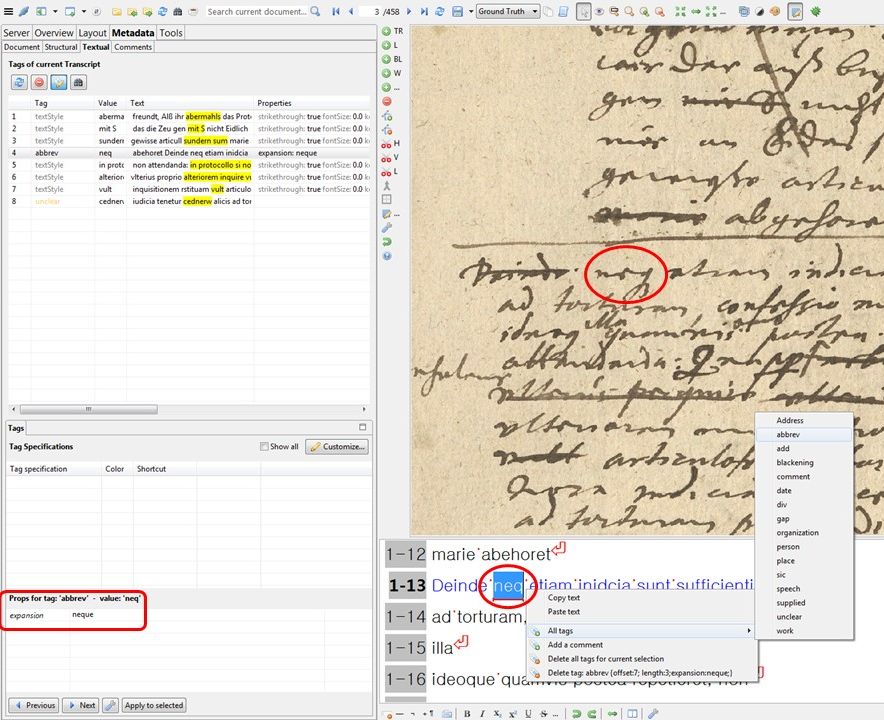
There are several, very different handwritings on one page and it becomes difficult to get consistently good HTR results. This happens most often when a ‘clean’ handwriting has been commented in concept handwriting by another writer. Here is an example:

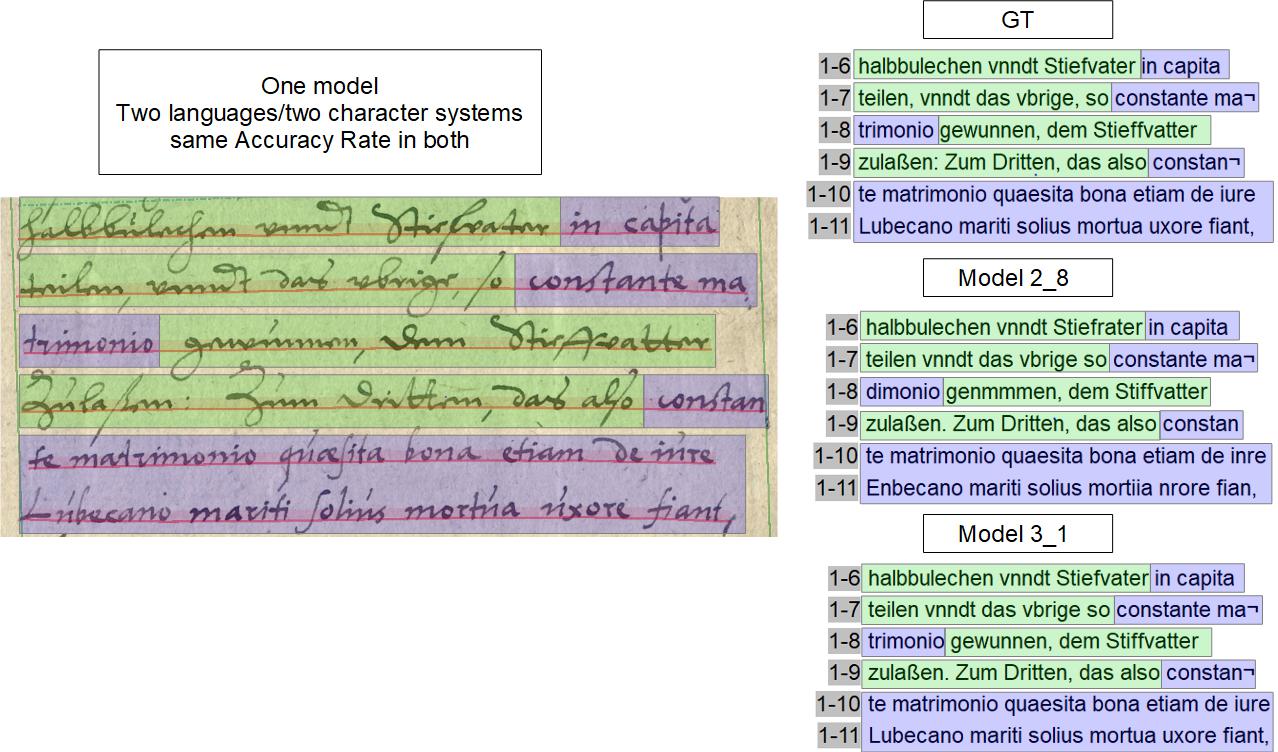
The real reason for the problem is that HTR has only been executed at the page level so far. This means that you can have one page or several pages read either with one or the other HTR model. But it is not possible to read with two different models, which are adapted to the respective handwritings.
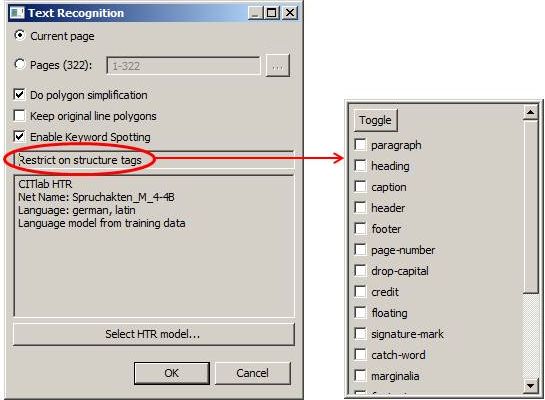
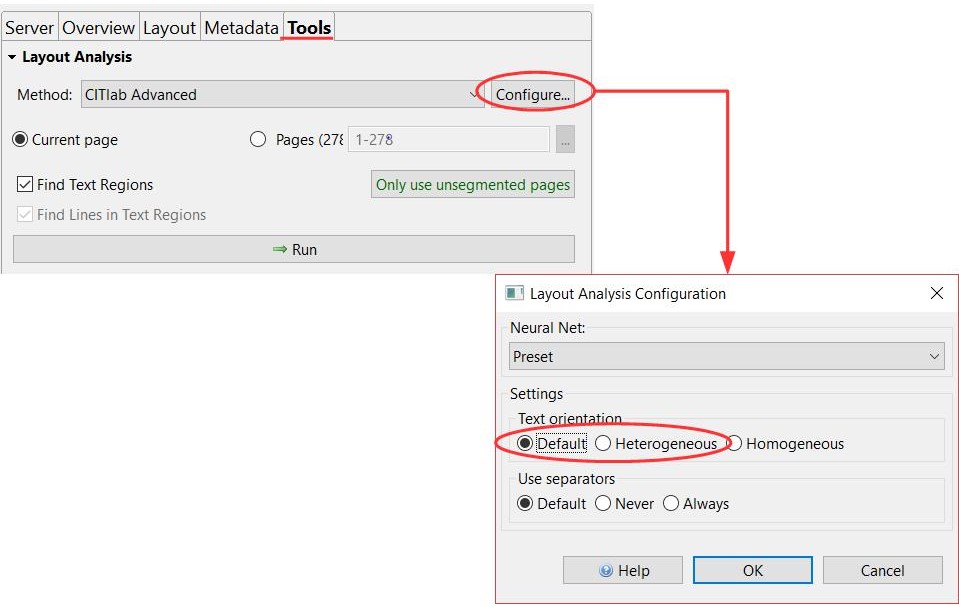
Since version 1.10. it is possible to apply HTR models on the level of text regions instead of just assigning them to pages. This allows the contents of individual specific text regions on a page to be read using different HTR models. Structure tagging plays an important role here, for example, in the case of text regions with script styles that differ from the main text. These are tagged with a specific structure tag, to which a special HTR model is then assigned. Reason enough, therefore, to take a closer look at structure tagging.