How to create test sets and why they are important, #1
Release 1.7.1
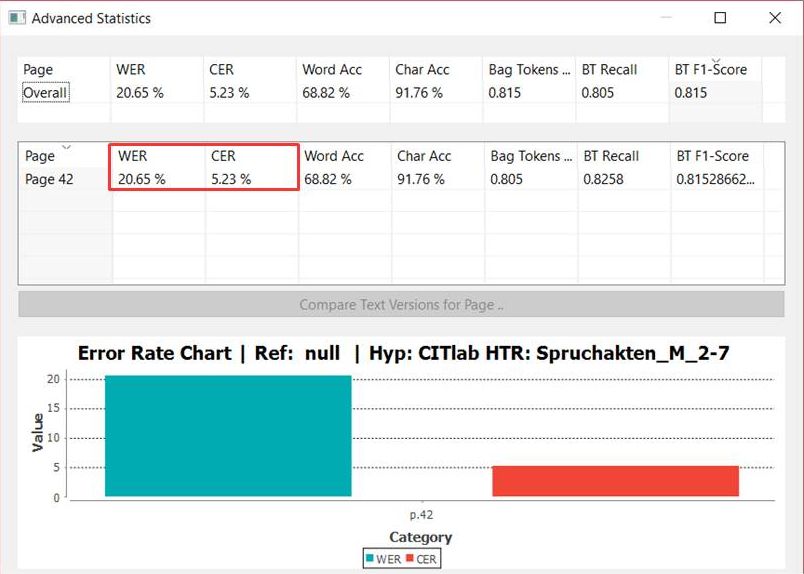
If we want to know how much a model has learned in training, we have to test it. We do this with precisely defined test sets. Test sets – like the training set – contain exclusively Ground Truth. However, we make sure that this GT has never been used to train the model. So the model does not “know” this material. This is the most important characteristic of test sets. A text page that has already been used as training material will always be better read by the model than one it is not yet “familiar” with. This can easily be proved experimentally. So if you want to get valid statements about CERs and WER, you need “non-corrupted” test sets.
It is also important that a test set is representative. As long as you train an HTR model for a single writer or an individual handwriting, it’s not difficult – after all, it’s always the same hand. As soon as there are several writers involved, you have to make sure that all the individual handwritings used in the training material are also included in the test set. The more different handwritings are trained in a model, the larger the test sets will be.
The size of the test set is another factor that influences representativity. As a rule, a test set should contain 5-10% of the training material. However, this rule of thumb should always be adapted to the specific requirements of the material and the training objectives.
To illustrate this with two examples: Our model for the Spruchakten from 1580 to 1627 was trained with a training set of almost 200,000 words. The test set contains 44,000 words. This is of course a very high proportion of about 20%. It is due to the fact that material of about 300 different writers was trained in this model, which must also be represented in the test set. – In our model for the judges’ opinions of the Wismar Tribunal, there are about 46,000 words in the training set, the test set contains only 2,500 words, i.e. a share of about 5%. However, we only have to deal with 5 different writers. In order to have a representative test set, the material is sufficient.