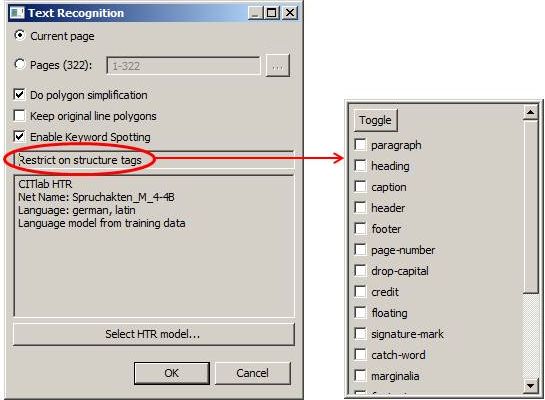
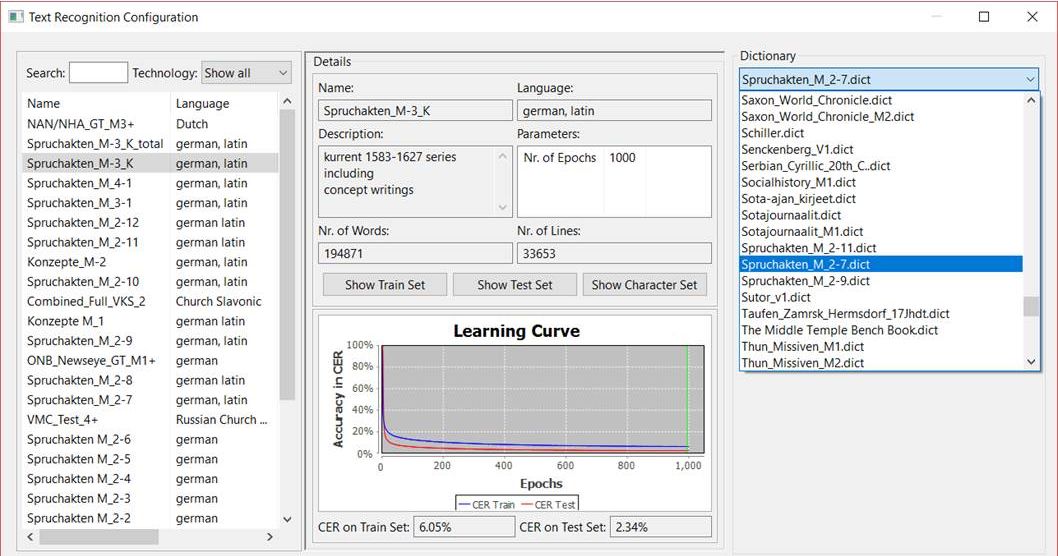
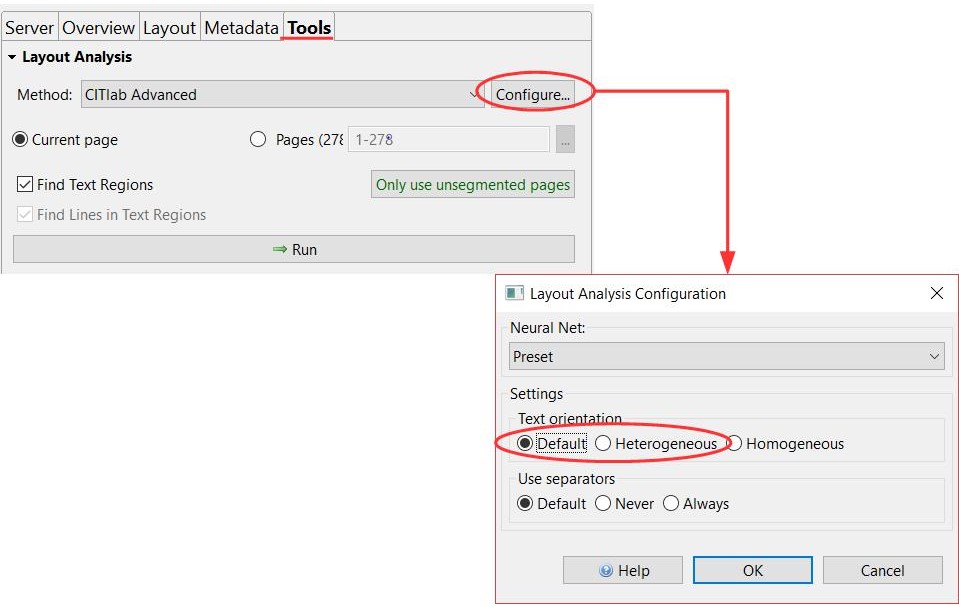
Treatment of erasures and blackenings
HTR models treat erased text the same as any other. They know no difference and therefore always provide a reading result. In fact, they are amazingly good at it, and read useful content even where a transcriber would have given up long ago.
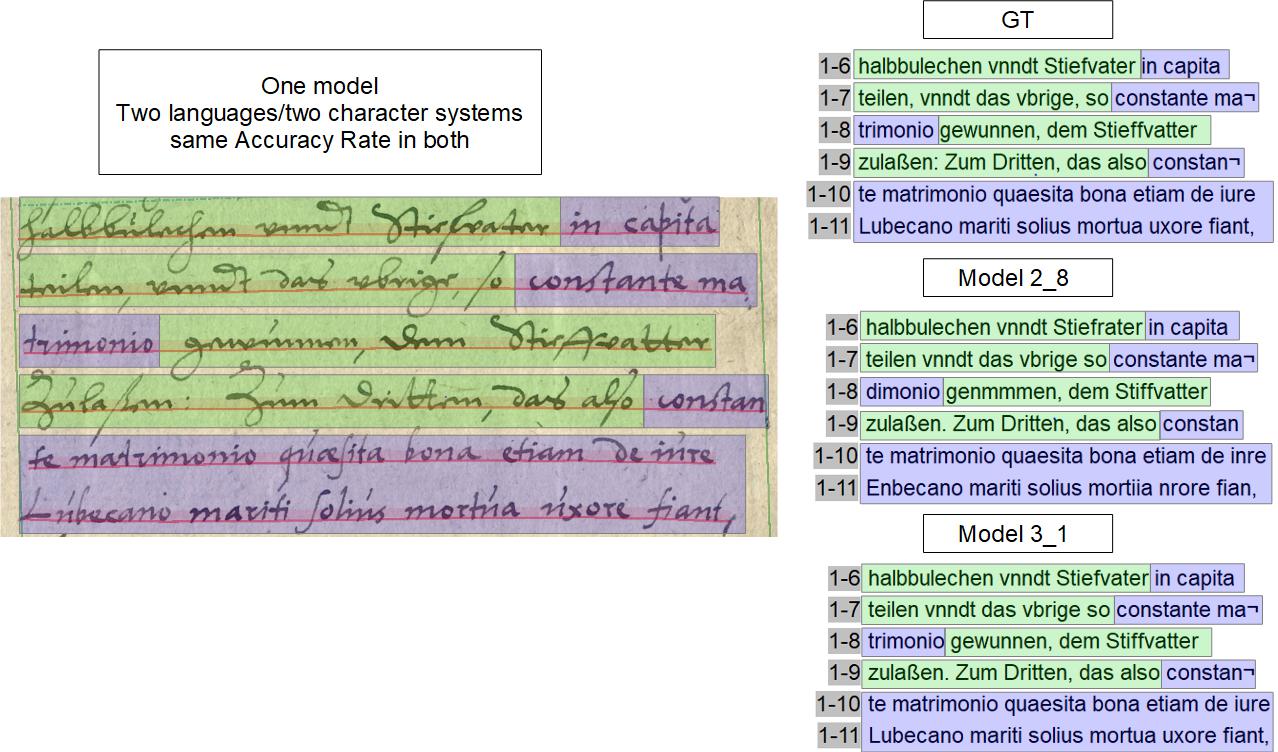
The simple example shows an erased text that is still legible to the human eye and which the HTR model has read almost without error.

Because we have already seen this ability of the HTR models in other projects, we decided from the beginning to transcribe as much of the erased and blacked out text as possible in order to use the potential of the HTR. The corresponding passages are simply tagged as text-style “strike through” in the text and thus remain recognizable for possible internal search operations.
If you don’t want to make this effort, you have the possibility to intervene in the layout at the corresponding text passages that contain erasures or blackenings and, for example, delete the baselines or shorten them accordingly. Then the HTR does not “see” such passages and cannot recognize them. But this is not less complex than the way we have chosen.
Under no circumstances should you work on erasures with the “popular” expression “[…]”. The transcribers know what the deletion sign means, but the HTR learns something completely wrong here, when many such passages come into training.