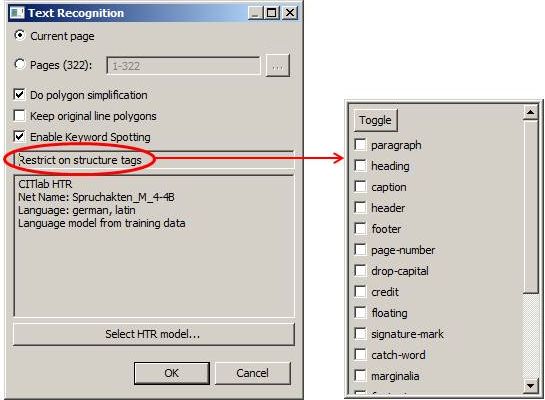
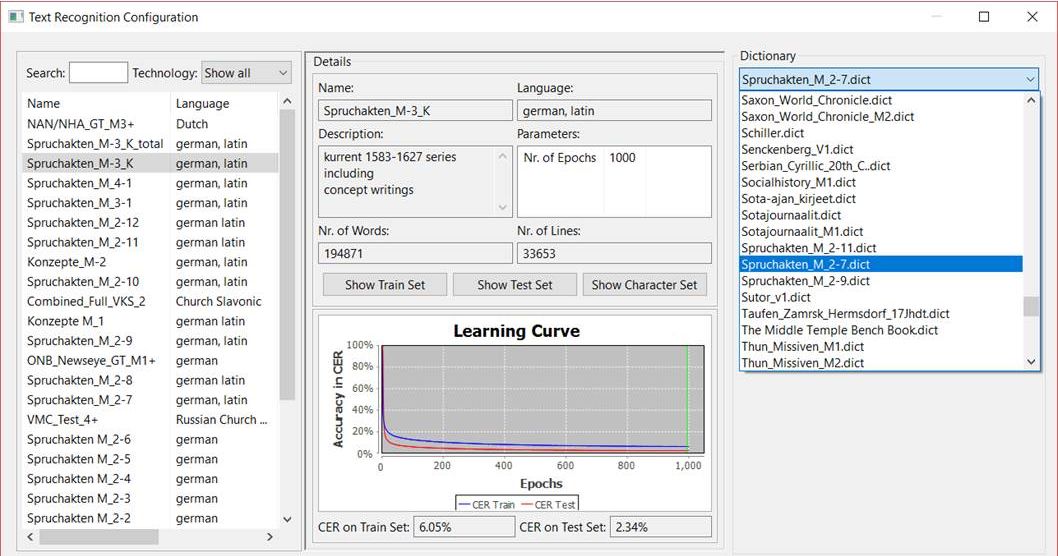
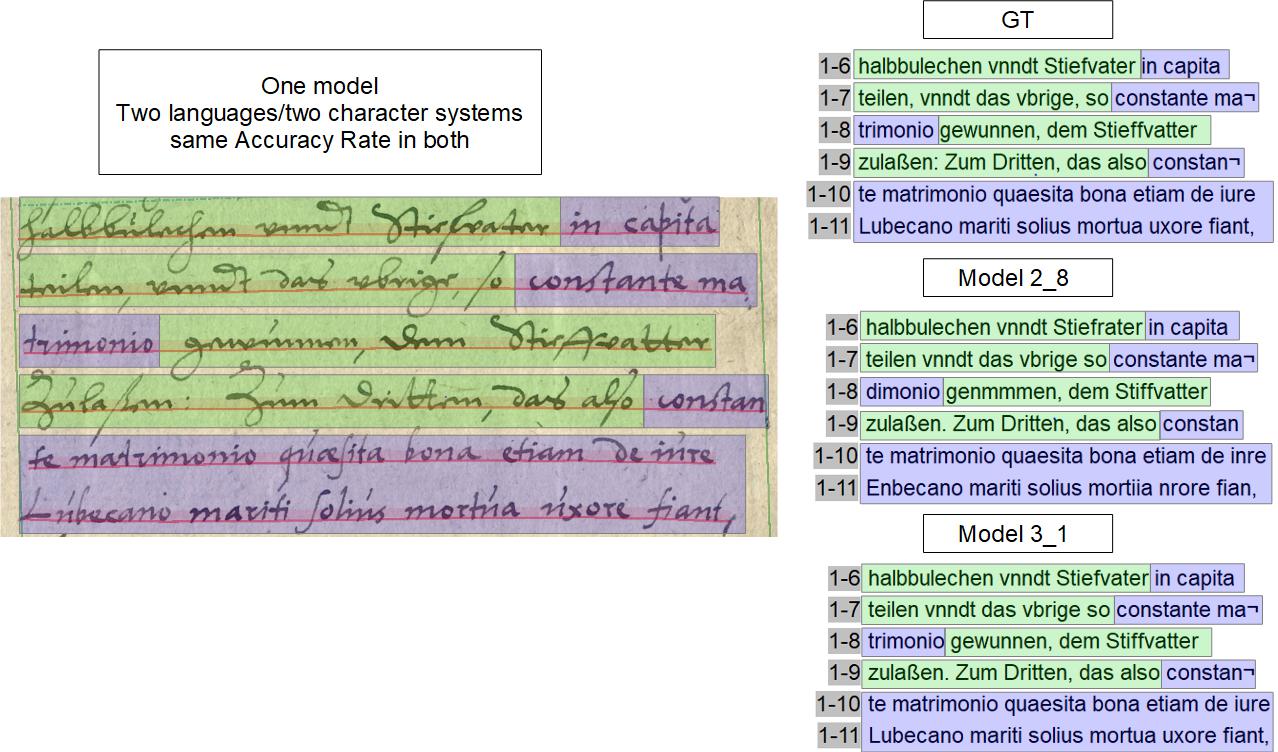
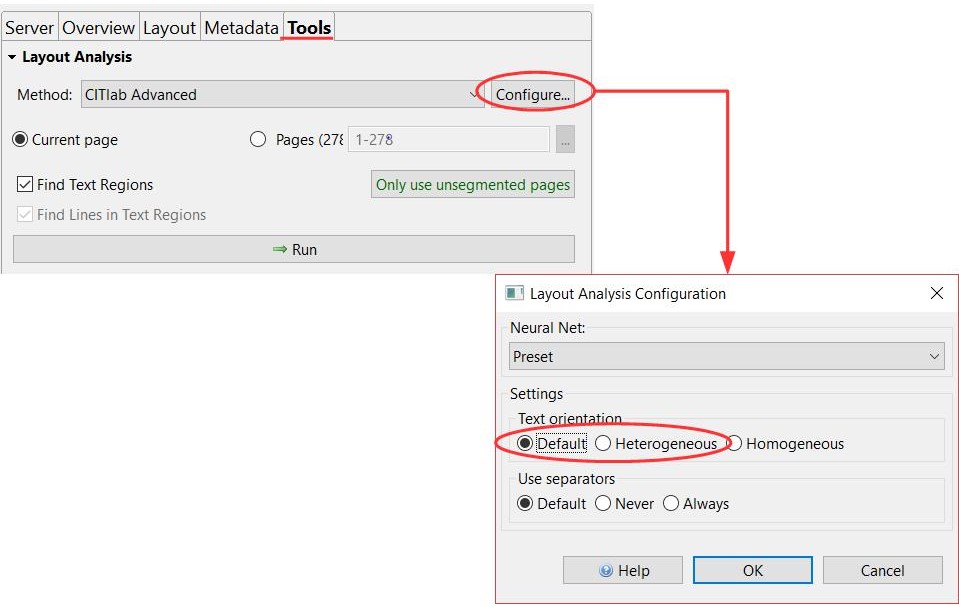
Behandlung von Streichungen und Schwärzungen
HTR-Modelle behandeln gestrichenen Text genauso wie jeden anderen. Sie kennen da keinen Unterschied und bieten also immer ein Leseergebnis. Sie sind dabei sogar erstaunlich gut und lesen auch da noch sinnvolle Inhalte heraus, wo ein Transcriber längst aufgegeben hätte.
Das einfache Beispiel zeigt einen auch für das menschliche Auge noch lesbaren gestrichenen Text, den das HTR-Modell fast fehlerfrei gelesen hat. Richtig wäre die Lesung „billig vormeinet habe“.

Weil wir diese Fähigkeit der HTR-Modelle bereits in anderen Projekten kennenlernen durften, haben wir von Anfang an beschlossen, auch Streichungen und Schwärzungen, so gut es eben geht, zu transkribieren um dieses Potential der HTR ebenfalls auszunutzen. Die entsprechenden Passagen werden von uns im Text einfach als text-style „strike through“ getaggt und bleiben so auch für evtl. interne Suchabfragen kenntlich.
Möchte man diesen Aufwand nicht treiben, hat man schlicht die Möglichkeit, an den entsprechenden Textpassagen, die Streichungen oder Schwärzungen enthalten, in das Layout einzugreifen und bspw. die Baselines zu löschen oder entsprechend zu verkürzen. Dann „sieht“ die HTR solche Passagen nicht und kann sie auch nicht erkennen. Das ist aber nicht weniger aufwendig als der von uns gewählte Weg.
Auf keinen Fall sollte man an Streichungen generell mit dem „beliebten“ Ausdruck „[…]“ arbeiten. Die Transkriber wissen zwar was das Auslassungszeichen bedeutet, die HTR lernt hier aber, wenn viele solche Stellen ins Training kommen, etwas völlig Falsches.