On the Shoulders of Giants: Training with Base Models
Release 1.10.1
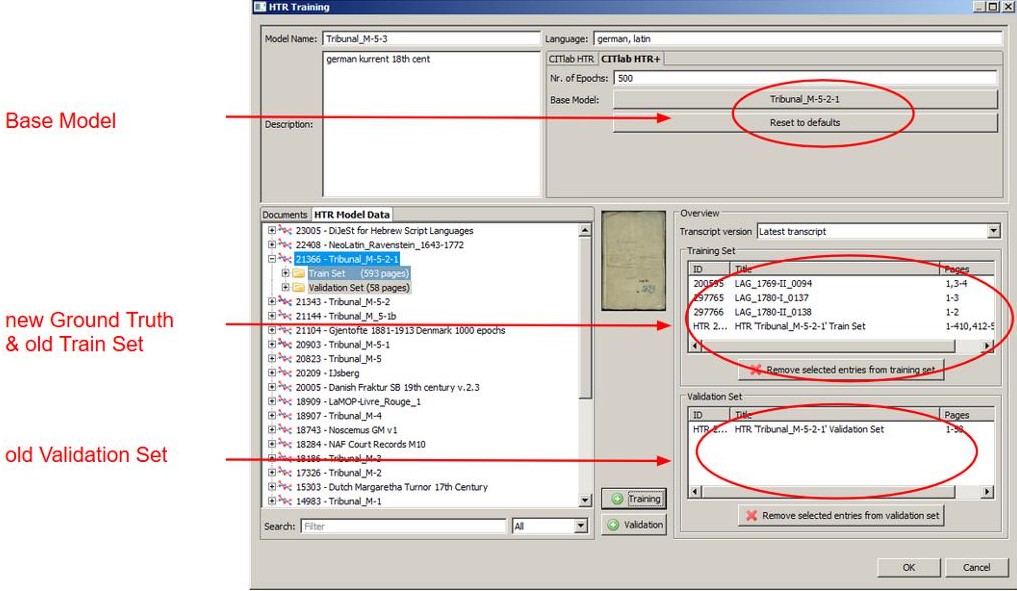
If you want to develop generic HTR models, there is no way around working with base models. When training with base models, each training session for a model is based on an existing model, i.e. a base model. This is usually the last HTR model that was trained in the corresponding project.
Base models “remember” what they have already “learned”. Therefore each new training session improves the quality of the model (theoretically). The new model learns from its predecessor and thus becomes better and better. Therefore, training with Base Models is also particularly suitable for large generic models that are continuously developed over a long period of time.
To carry out training with Base Model, you simply select a specific Base Model in the training tool – in addition to the usual settings. Then, from the HTR Model Data tab, insert the Train Set and the Validation Set (called Test Set in earlier Trankribus versions) of the base model, as well as the new Training and Validation Set. Additionally you can add more new Ground Truth and then start the training.