The more, the better – how much GT do I have to put in?
Release 1.7.1
As I said before: Ground Truth is the key factor when creating HTR models.
GT is the correct and machine-readable copy of the handwriting that the machine uses to learn to “read”. The more the machine can “practice”, the better it will be. The more Ground Truth we have, the lower the error rate.
Of course, the quantity always depends on the specific use case. If we work with a few, easy-to-read writing, little GT is usually enough to train a solid model. However, if the writings are very different because we are dealing with a large number of different writers, the effort will be higher. This means that in such cases we need to provide more GT to produce good HTR models.
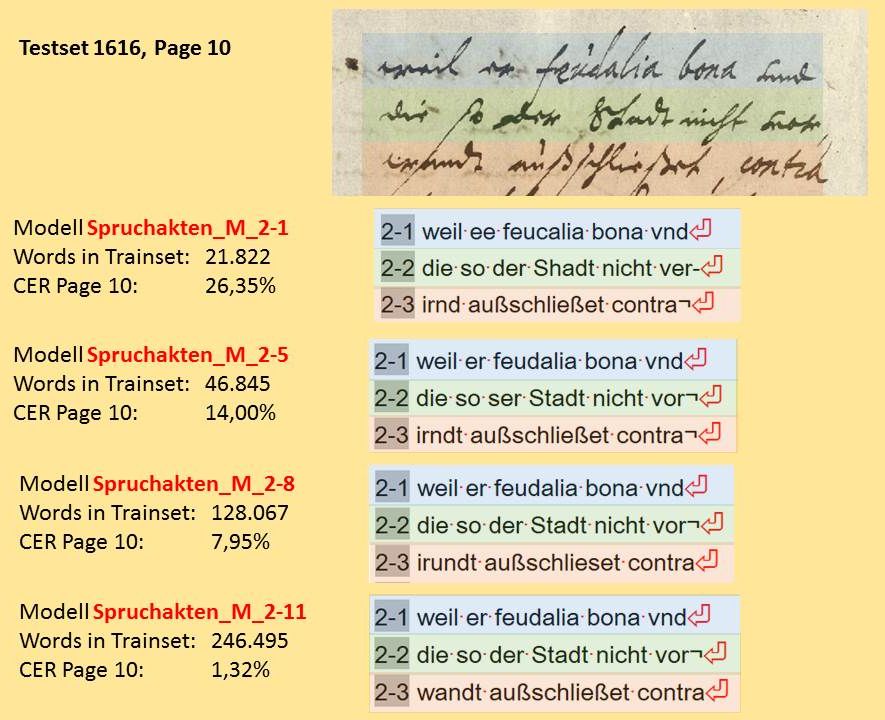
In the Spruchakten we find many different writers. That’s why a lot of GT was created to train the models. Our HTR-models (Spruchakten_M_2-1 to 2-11) clearly show how quickly the error rate actually decreases if as much GT as possible is invested. We can roughly say that doubling the amount of GT in training (words in trainset) will halve the error rate (CER page) of the model.
In our examples we could observe that we have to train the models with at least 50,000 words of GT in order to get good results. With 100,000 words in training, you can already create excellent HTR models.