Languages
HTR does not require dictionaries and works regardless of the language in which a text is written – as long as it uses the character system the model is trained for.
For the training strategy in our project, this means that we do not distinguish between Latin and German texts or Low German and High German texts when selecting the training material. So far, we have not found any serious differences in the quality of the HTR results between texts in both languages.
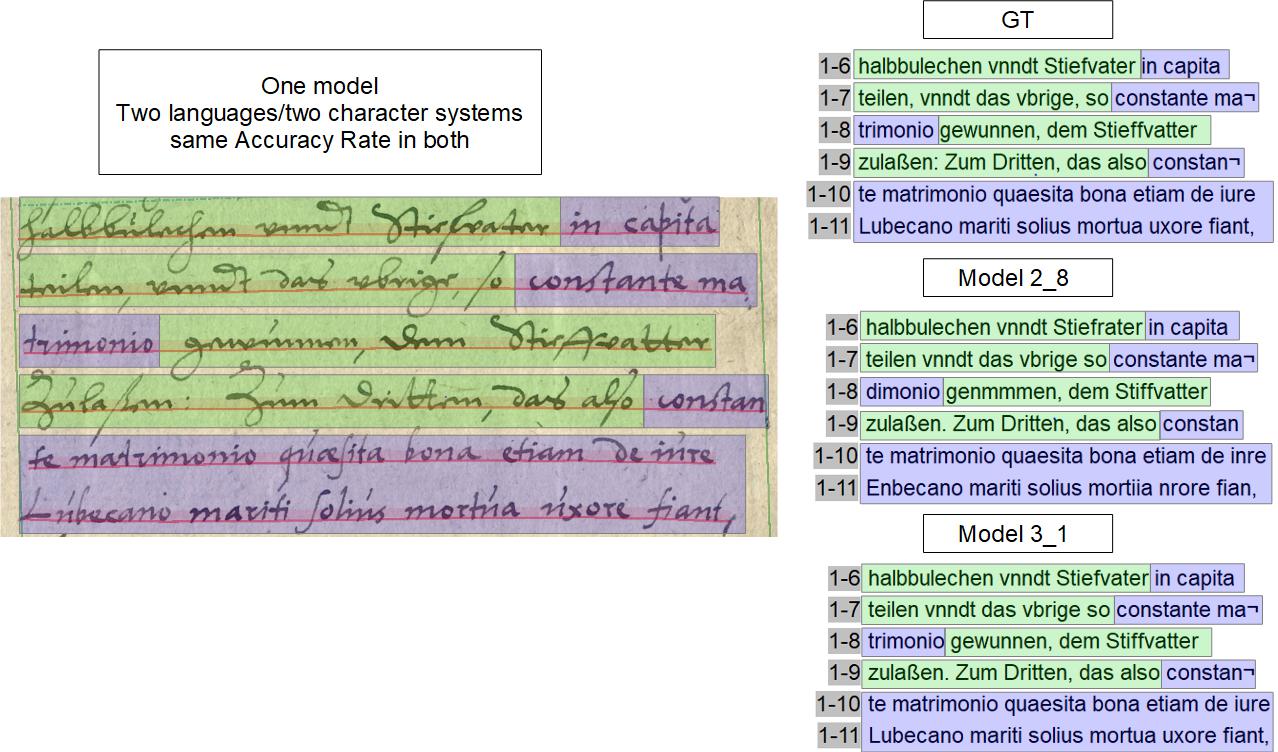
This observation is important for historical manuscripts from the German-speaking countries. Usually, the language used within a document also affects the script. Most writers of the 16th to 18th centuries, when they switch from German to Latin, change in the middle of the text from Kurrent to Antiqua. In contrast to OCR, where the mixed use of gothic and antiqua typefaces in modern printing is very difficult, HTR – if it is trained for it – has no problem with this change.
A very typical case in our material, here with a comparison of the HTR result and GT, can illustrate the problem. The error rate in the linguistically different text sections of the page is quite comparable. The models used were the Spruchakten_M 2-8 and M 3-1. The first is an generic model, the second is specialized for writings from 1583 to 1627.