Unser erstes öffentlich zugängliches Modell für die deutschen Kurrentschriften des 17. Jahrhunderts
Heute präsentieren wir „Acta 17“ als öffentlich zugängliches HTR Modell.
Das Modell wurde anhand von mehr als 500.000 Wörtern aus Texten von etwa 1000 verschiedenen Schreibern aus der Zeit von 1580-1705 vom Universitätsarchiv Greifswald trainiert. Es kann mit deutschsprachigen, lateinischen und niederdeutschen Texten umgehen und ist in der Lage, einfache deutsche und lateinische Abkürzungen aufzulösen. Neben den üblichen Kanzleischriften enthielt das Trainingsmaterial auch eine Auswahl von Konzeptschriften und Druckschriften der Zeit.
Das gesamte Trainingsmaterial basiert auf Konsulentenanfragen, Prozessschriften und Urteilen aus dem Aktenbestand der Greifswalder Juristenfakultät Die Validierungssets basieren auf einer chronologischen Auswahl der Jahre 1580 – 1705 . GT & Validierungssets wurden von Dirk Alvermann, Elisabeth Heigl, Anna Brandt erstellt.
Aufgrund einiger Probleme bei der Durchführung umfangreicherer Serien von base model Trainings für HTR+ Modelle in den letzten Wochen haben wir beschlossen, ein von Grund auf neu trainiertes HTR+ Modell als öffentliche zugängliches Modell bereit zu stellen.
Es wird von einem PyLaia-Modell begleitet, das auf den gleichen Trainings- und Validierungssets basiert und ebenfalls ohne Nutzung eines Base Modells trainiert wurde.
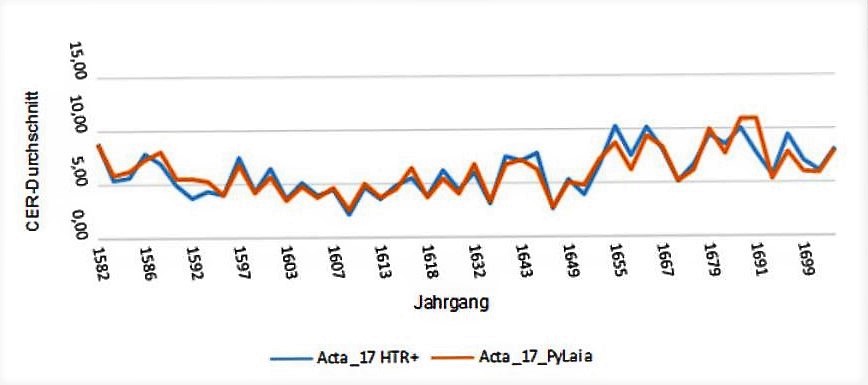
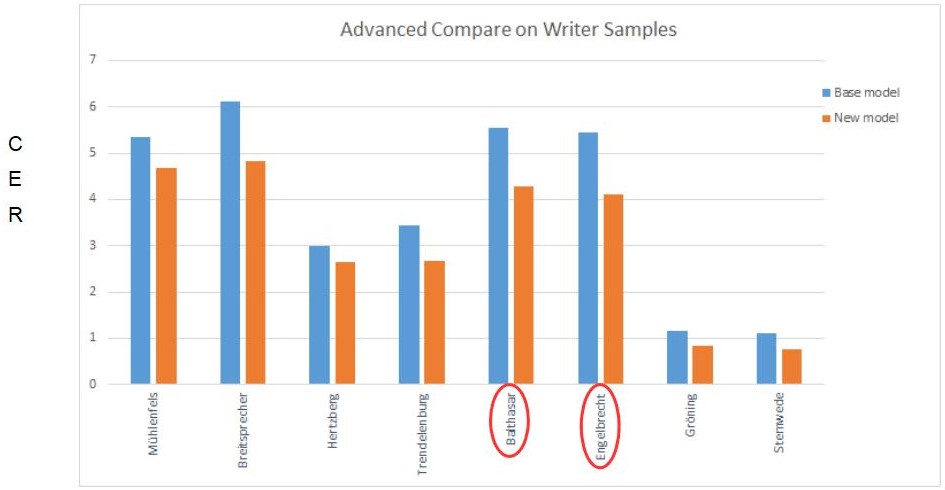
Für das Validierungsset wählten wir Seiten, die einzelne Jahre des gesamten verfügbaren Materials repräsentieren. Insgesamt waren es 48 ausgewählte Jahre, fünf Seiten pro Jahr.
Wie sich die Modelle in den verschiedenen Zeiträumen des Validierungssets verhalten, könnt ihr im untenstehenden Vergleich sehen. Beide Modelle wurden ohne language model ausgeführt.