Word Error Rate & Character Error Rate – woran sich ein Modell messen lässt
Release 1.7.1
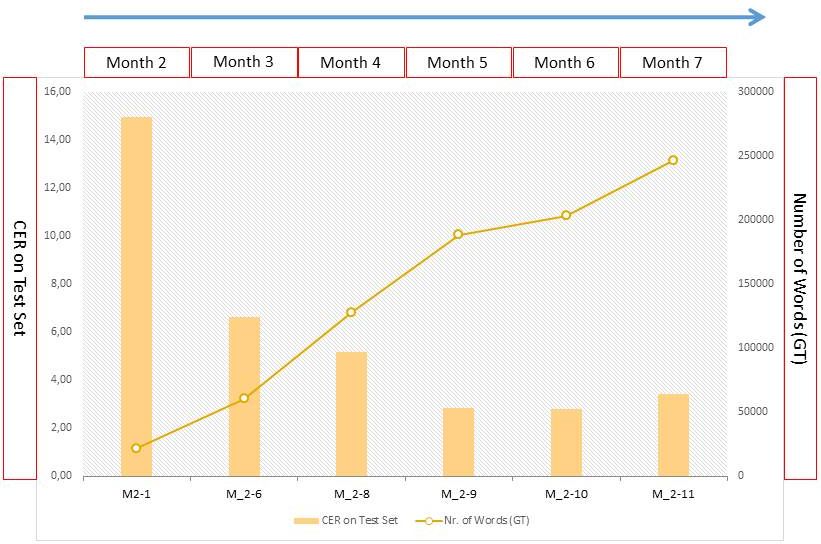
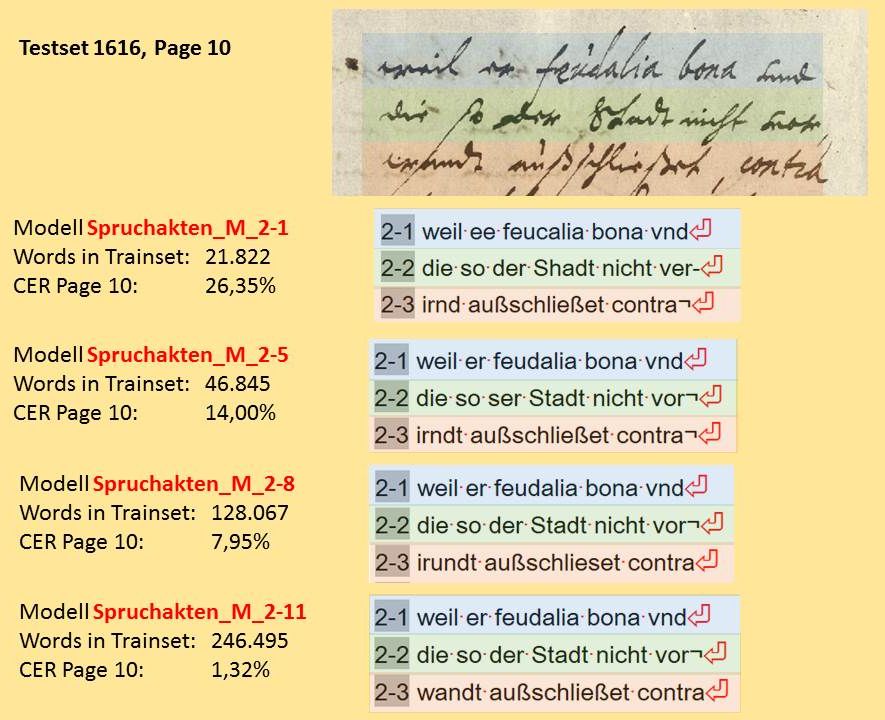
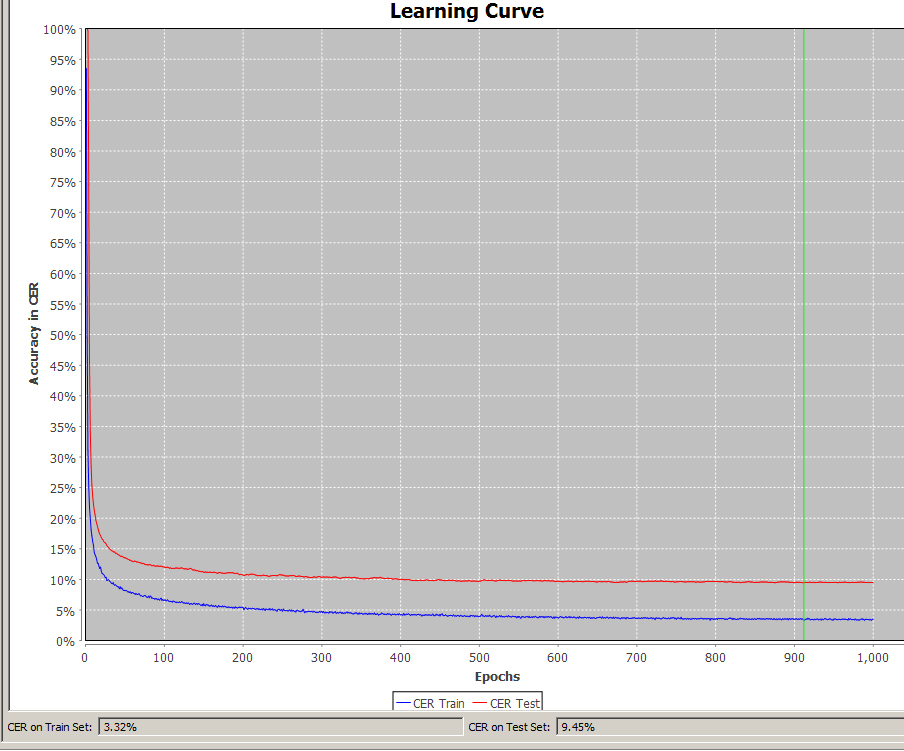
Die Word Error Rate (WER) und Character Error Rate (CER) zeigen an, wie hoch der Textanteil einer Handschrift ist, den das angewendete HTR-Modell nicht korrket gelesen hat. Eine CER von 10% bedeutet also, dass jedes zehnte Zeichen (und das sind nicht nur Buchstaben, sondern auch Interpunktionen, Leerzeichen etc.) nicht richtig erkannt wurde. Die Accuracy Rate läge demnach bei 90 %. Von einem guten HTR-Modell kann man sprechen, wenn 95% einer Handschrift korrekt erkannt wurde, die CER also nicht über 5% liegt. Das ist in etwa auch der Wert, den man heute mit „schmutziger“ OCR bei Frakturschriften erziehlt. Im Übrigen entspricht eine Accuracy Rate von 95% auch den Erwartungen, die in den DFG-Praxisregeln Digitalisierung formuliert sind.
Selbst bei einer guten CER kann die Word Error Rate hoch sein. Die WER zeigt, wie gut die wortgenaue Wiedergabe des Textes ist. In Aller Regel liegt die WER um das drei bis vierfache höher als die CER und verhält sich proportional zu ihr. Der Wert der WER ist nicht besonders aussagekräftig für die Qualität des Modells, denn anders als Zeichen, sind Wörter unterschiedlich lang und gestatten keine gleichermaßen eindeutigen Vergleich (ein Wort ist schon falsch erkannt, wenn ein Buchstabe darin falsch ist). Darum wird sie auch seltener benutzt, um den Wert eines Modells zu charakterisieren.
Die WER gibt aber Hinweise auf einen wichtigen Aspekt. Denn wenn ich eine Texterkennung mit dem Ziel durchführe, später eine Volltextsuche in meinem Dokuemnt durchzuführen, dann zeigt mir die WER genau die Erfolgsquote, mit der ich bei meiner Suche rechnen kann. Gesucht wird ja nach Worten oder Wortteilen. Egal also wie gut meine CER ist: bei einer WER von 10% kann potentiell jeder zehnte Suchbegriff nicht gefunden werden.
Tipps & Tools
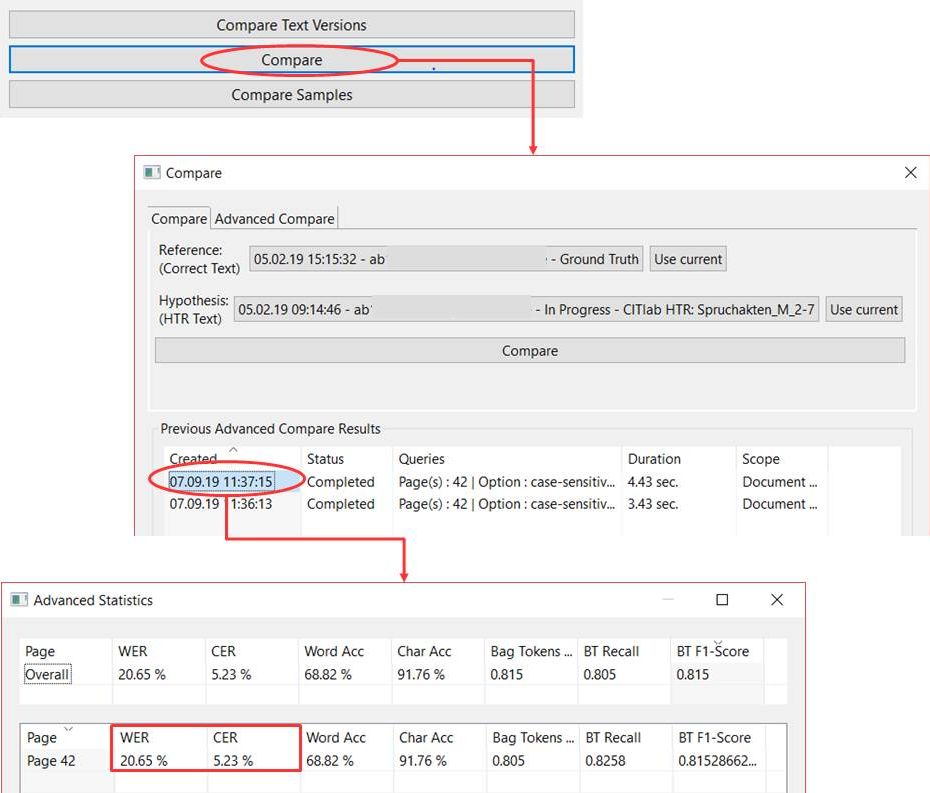
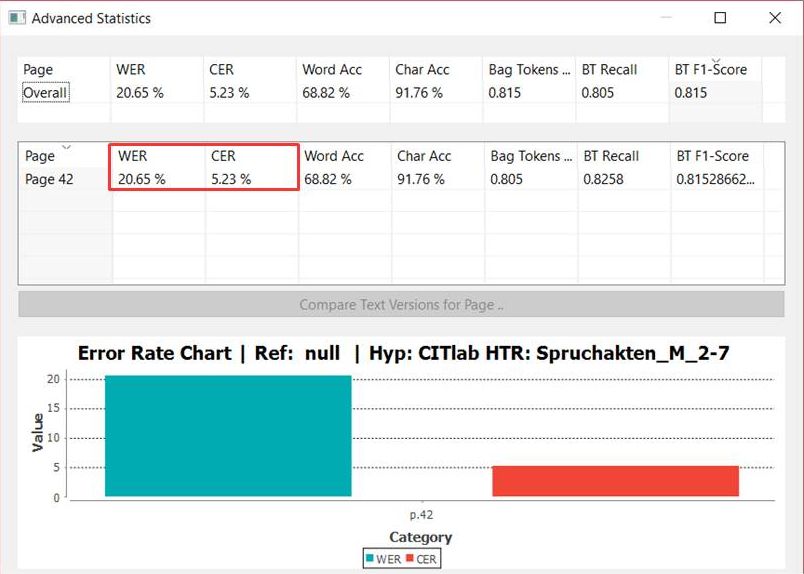
Am einfachsten lässt sich die CER und WER mithilfe der Compare Funktion unter Tools anzeigen. Hier könnt ihr bei einer oder mehreren Seiten eine Ground Truth Version mit einem HTR-Text vergleichen und so die Qualität des Modells einschätzen.