
HTR+ versus Pylaia
Version 1.12.0
As you have probably noticed, since last summer there is a second recognition engine available in Transkribus besides HTR+ – PyLaia. (link)
We have been experimenting with PyLaia models in the last weeks and would like to document our first impressions and experiences about the different aspects of HTR+ and PyLaia. First of all: considering the economic point of view, PyLaia is definitely a little bit cheaper than HTR+, as you can see on the price list of the Read Coop. Does cheaper also mean worse? – Definitely not! In terms of accuracy rate PyLaia can easily compete with HTR+. It is often slightly better. The following graphic compares an HTR+ and a PyLaia model trained with identical ground truth (approx. 600,000 words) under the same conditions (from the scratch). The performance with and without the Language Model is compared.
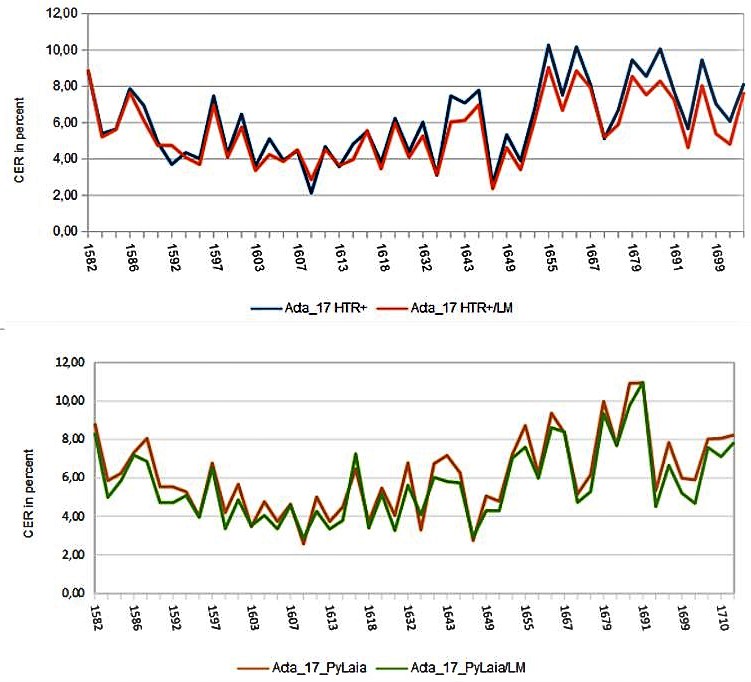
Perhaps the most notable difference is that the results of PyLaia models cannot be improved as much by using a Language Model as is the case with HTR+. This is not necessarily a disadvantage, but rather indicates a high basic reliability of these models. In other words: PyLaia does not necessarily need a Language Model to achieve very good results.
There is also an area where PyLaia performs worse than HTR+. PyLaia has more difficulties to read “curved” lines correctly. For vertical text lines the result is even worse.
In training PyLaia is a bit slower than HTR+, which means that the training takes longer. On the other hand, PyLaia is much faster in “acceleration”. It needs relatively few training epochs or iterations to achieve good results. You can compare this quite well with the two learning curves.
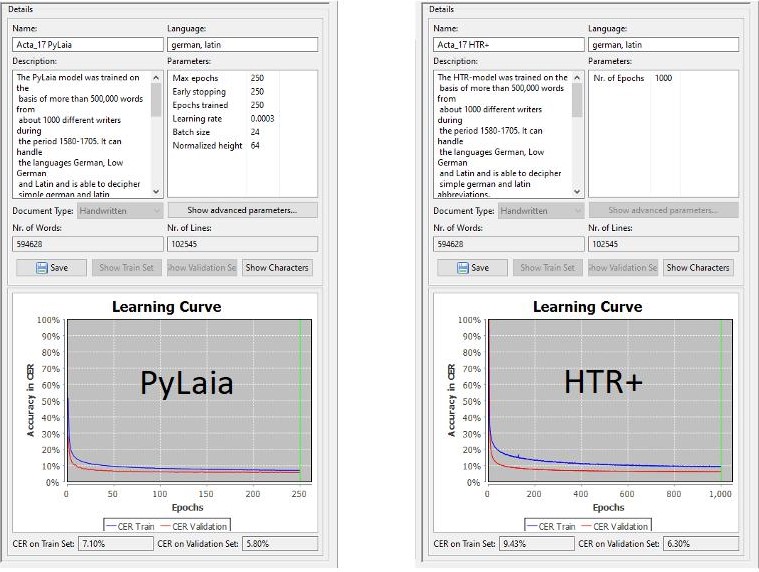
Our observations are of course not exhaustive. So far they only refer to generic models that have been trained with a high level of ground truth. Overall we have the impression that PyLaia can fully exploit its advantages with such large generic models.
