Tag Export II
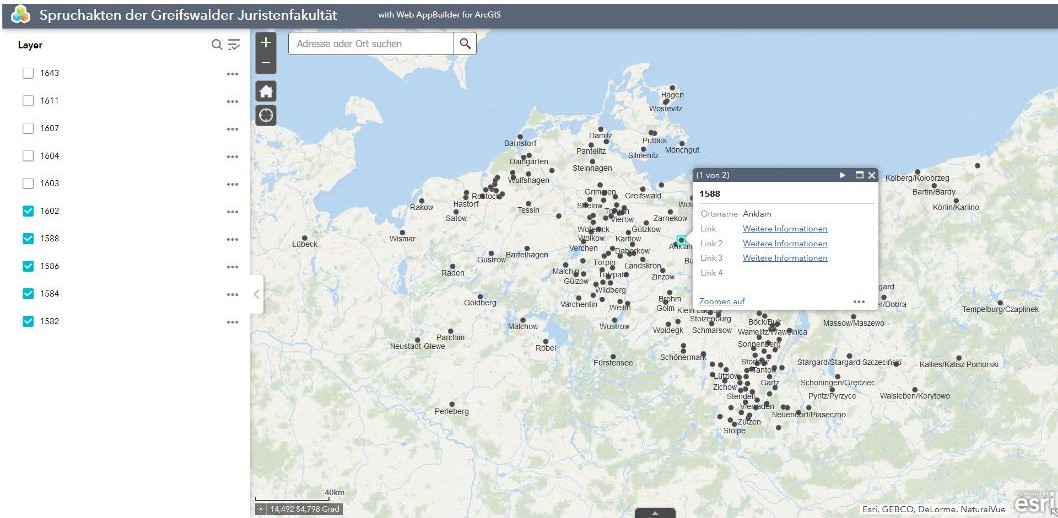
Im letzten Post haben wir den Nutzen von Tags für die Visualisierung von Ergebnissen anhand der Darstellung von Place-Tags auf einer Karte vorgestellt. Es gibt aber noch andere Möglichkeiten.
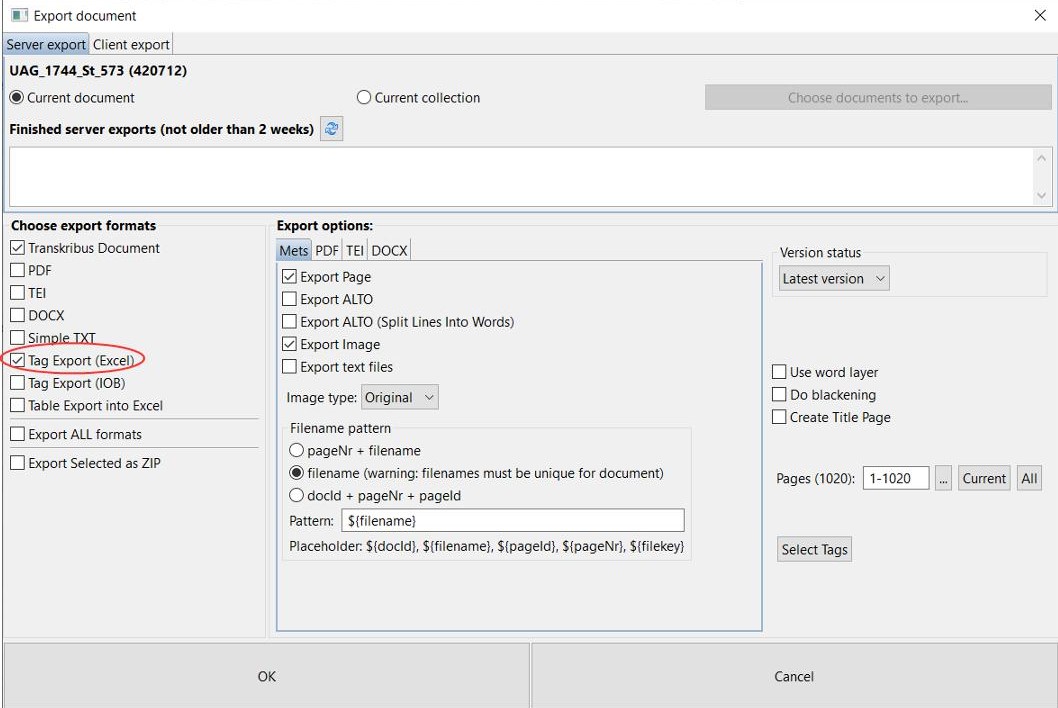
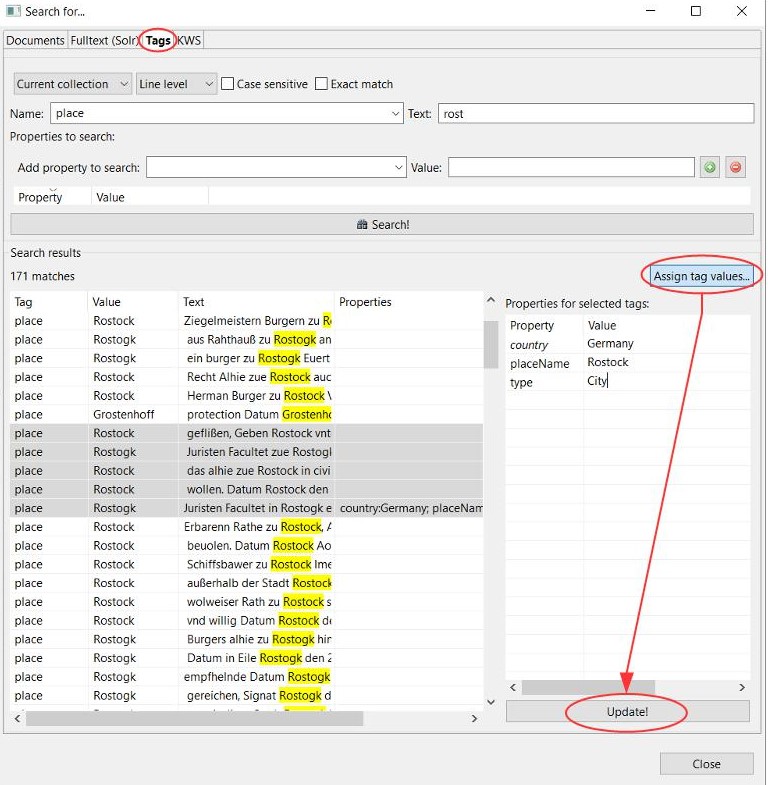
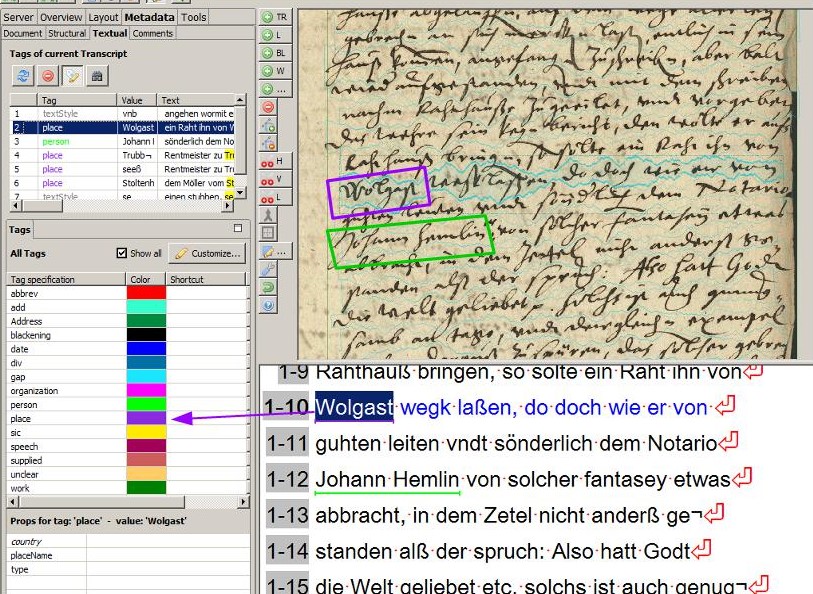
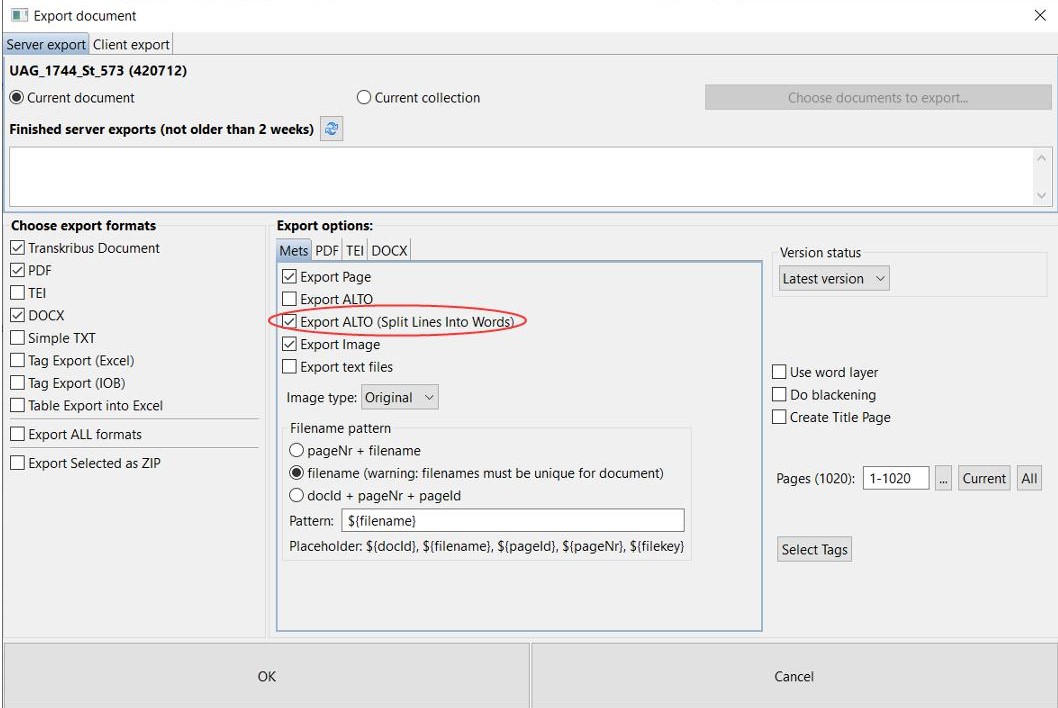
Tags können nicht nur separat, wie in Form einer Excel-Tabelle exportiert werden. Einige Tags (place oder person) werden auch in den ALTO-Dateien mit ausgegeben. Diese Dateien sind unter anderem dafür verantwortlich, dass wir in unserem Viewer/Presenter die Treffer der Volltextsuche anzeigen können. Dazu wählt man einfach beim Export der METS-Dateien zusätzlich „Export ALTO (Split lines into words)“.
In unserem Presenter in der Digitalen Bibliothek Mecklenburg-Vorpommern werden die Tags dann als „named entities“ getrennt nach Orten und Personen für das jeweilige Dokument angezeigt. Das ganze ist noch in der Versuchsphase und soll in nächster Zeit so weiterentwickelt werden, dass man über eine tatsächliche Tagcloud direkt auf die entsprechenden Stellen im Dokumente springen kann.