Transkribieren ohne Layoutanalyse?
Release 1.10.1
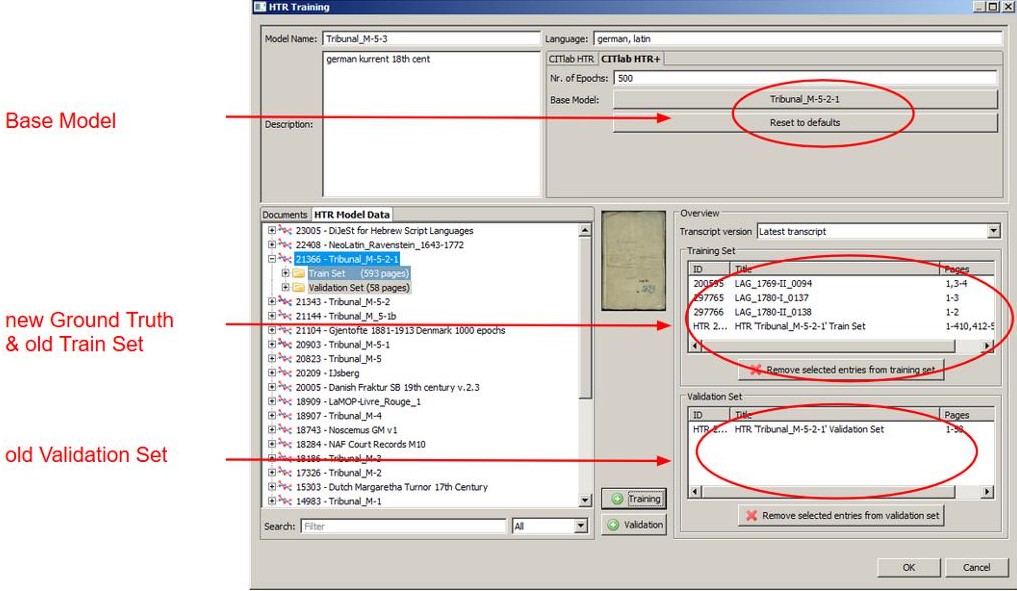
Wir haben in vorherigen Posts immer wieder betont wie wichtig die LA ist. Ohne sie hat ein HTR-Modell, und mag es noch so gut sein, keine Chance einen Text vernünftig zu transkribieren. Die Schritte von automatischer LA (oder einem P2PaLA-Model) und HTR löst man normalerweise getrennt voneinander aus. Jetzt ist uns aufgefallen, dass wenn ein HTR-Modell über eine komplett neue bzw. unbearbeitete Seite läuft, das Programm selbstständig eine LA ausführt.
Diese LA läuft mit den Default-Einstellungen von CITLab-Advanced LA. Dies bedeutet bei den reinen Seiten weniger Linien zu mergen und es werden zum Teil mehr als eine Textregion erkannt.
![]()
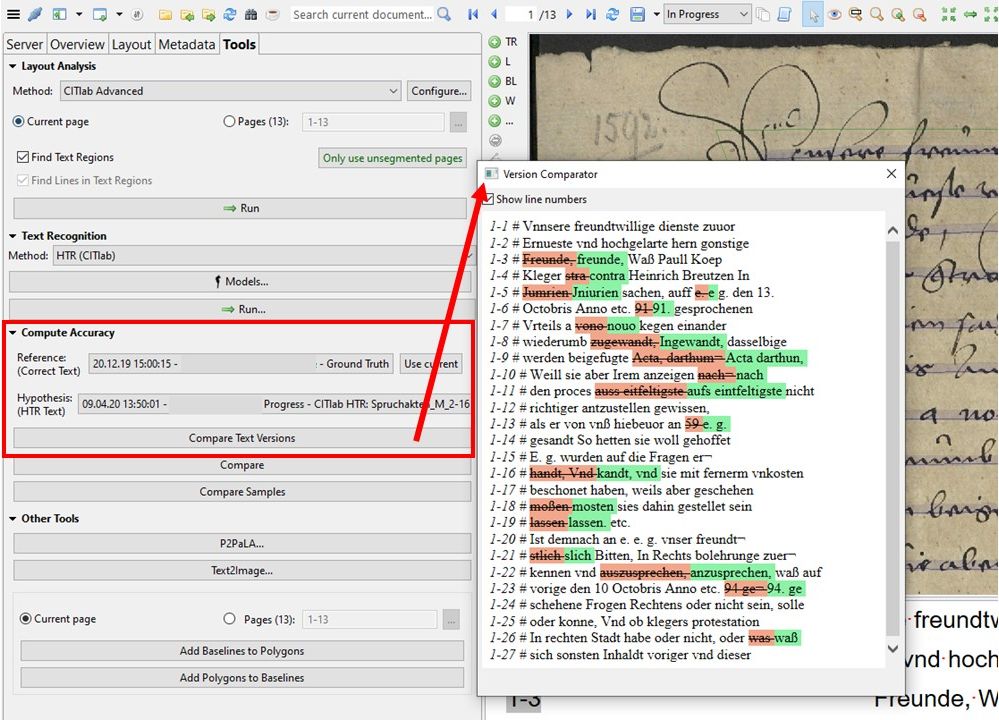
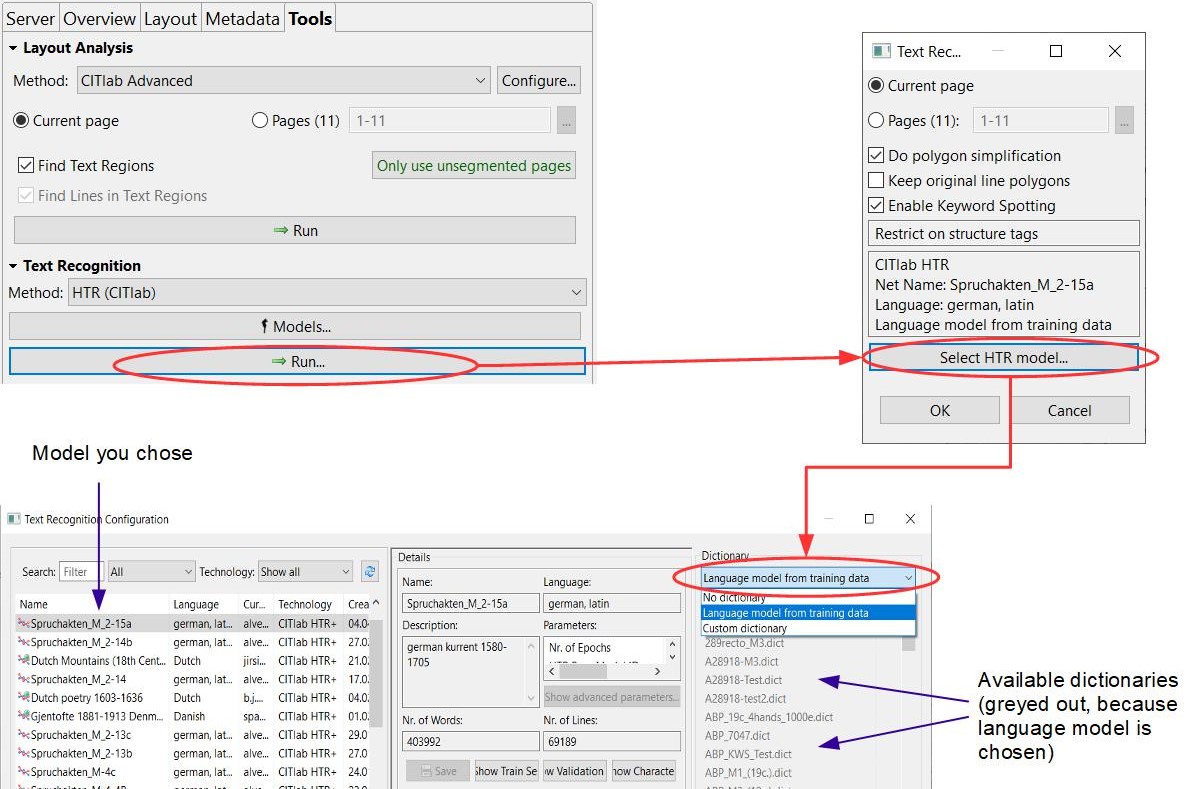
Es bedeutet jedoch auch, dass nur horizontale Schrift erkannt wird. Dasselbe Problem war bei uns auch bei unseren P2PaLA-Modellen aufgefallen. Alles was schräg steht oder gar vertikal kann so nicht erkannt werden. Dafür muss die LA manuell ausgelöst werden, mit der Einstellung ‚Text Orientation‘ auf ‚Heterogeneous‘.
![]()
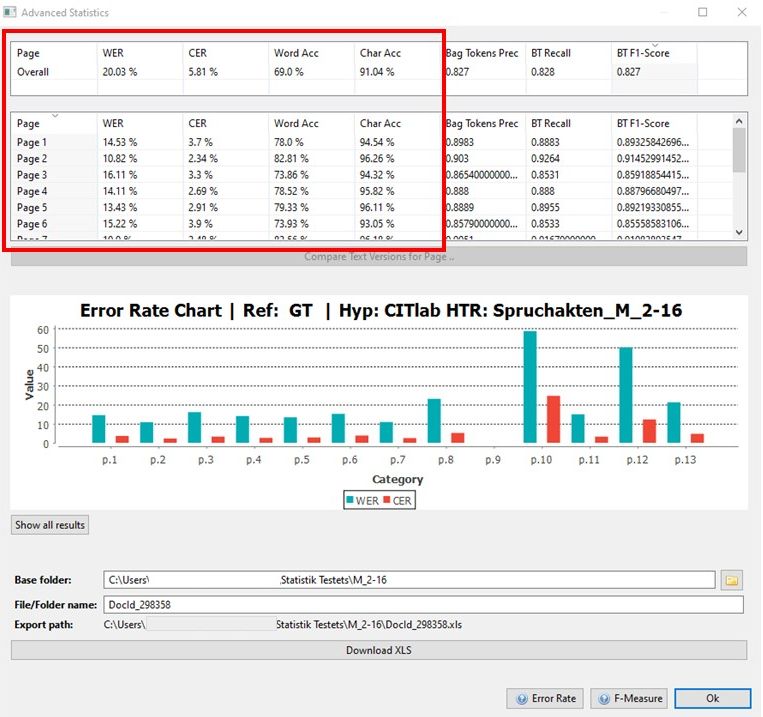
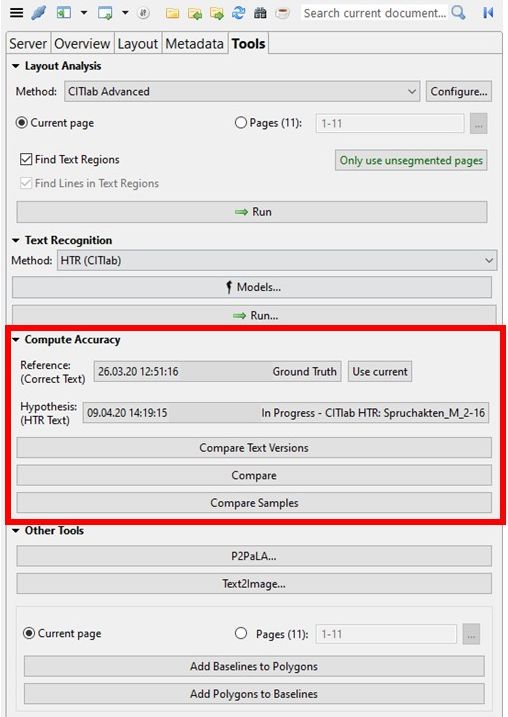
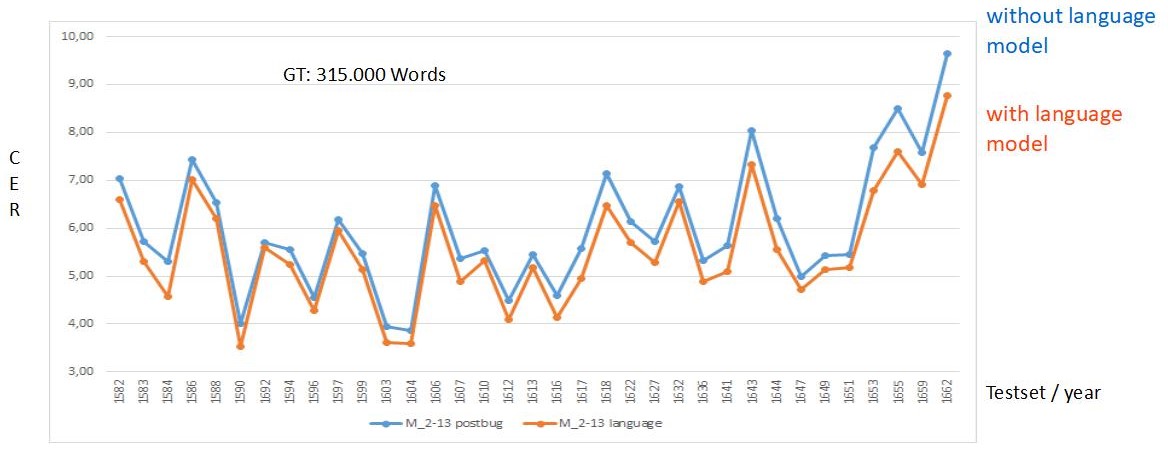
Die HTR Ergebnisse sind bei dieser Methode interessanterweise besser als bei einer HTR die über eine korrigierte Layoutanalyse gelaufen ist. Wir haben dazu an bei einigen Seiten die CER ausgerechnet.
![]()
Damit ist diese Methode eine sehr gute Alternative, vor allem bei Seiten mit unkompliziertem Layout. Man spart Zeit, da man nur einen Vorgang auslösen muss und hat am Ende ein besseres Ergebnis.